Sous le capot d'un Chatbot : le cerveau de Skynet
Comment un programme peut-il apprendre par lui-même à répondre à des questions qu’on ne lui a jamais posées ? Quels algorithmes se cachent derrière les chatbots ? La réponse à ces questions dans le second article de cette série consacrée aux agents conversationnels.
Dernièrement, Quantmetry a eu l’occasion de travailler sur la création et l’implémentation d’un chatbot qui répond aux visiteurs d’un site de formations en ligne. Dans ce nouvel opus, nous abordons la modélisation et l’entraînement du chatbot, tandis que la construction d’une API qui intègre l’intelligence du modèle de réponse dans un chat fera l’objet du troisième et dernier article de cette série.
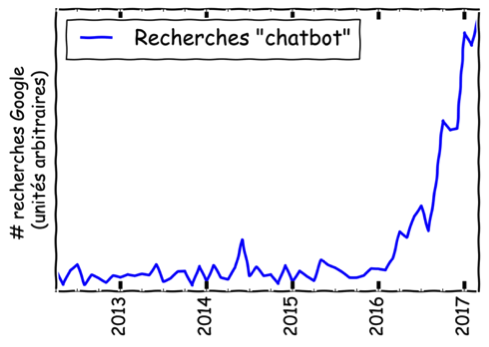
Au passage, si vous n’étiez pas encore au fait de l’omniprésence imminente des chatbots jetez un œil au graphique ci-dessous, ou mieux encore lisez le premier article de cette série si vous ne l’avez pas déjà fait !
Introduction

La création d’un chatbot à même d’avoir une conversation cohérente dans n’importe quel contexte est le Graal de l’intelligence artificielle. Ce chatbot générique fait l’objet d’un effort de recherche intense, soutenu par les chercheurs des universités et grands groupes tels que Google, Facebook, Amazon, et quelques autres [1]. Pour s’adapter à n’importe quel contexte ou interlocuteur, un tel agent conversationnel doit générer ses réponses mot par mot ; on parle de chatbot génératif. Le problème de cette approche est qu’elle est trop générale et les chatbots peinent à avoir une conversation cohérente ou même à produire des phrases syntaxiquement valides avec les modèles actuels.

Le modèle que l’on veut construire doit être à même de produire une réponse cohérente au dernier message de son interlocuteur, tout en prenant en compte l’historique de la conversation.
La formalisation du problème pose plusieurs questions :
● Quelles données sont nécessaires ? Comment représenter les conversations pour qu’un modèle statistique puisse les appréhender ?
● Quels modèles d’apprentissage automatique peuvent traiter ce problème efficacement ?
● Comment évaluer les performances du chatbot ? Autrement dit comment quantifier la plausibilité d’une réponse proposée par le chatbot et la cohérence de la conversation au vu des réponses du chatbot ?
De la conversation au modèle statistique
Pour un ordinateur, une conversation n’est qu’une série de lettres sans structure. On doit d’abord trouver un moyen de simplifier le texte, puis de transformer les conversations en vecteurs tout en conservant la structure du langage, avant d’entraîner le modèle de génération de réponse; enfin, on doit choisir une métrique d’évaluation du modèle pour sélectionner automatiquement le plus performant.
Pré-traitement
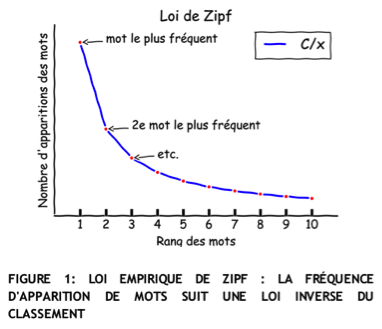
Nous avions 25 000 conversations à notre disposition pour l’entraînement du chatbot. C’est énorme … et très peu à la fois. En effet la plupart des quelques 20 000 mots différents qui apparaissent dans notre corpus de conversation n’apparaissent qu’une fois. Cette observation confirme une fois de plus la loi empirique de Zipf (cf. Figure 1), qui implique notamment que la plupart des mots d’un texte ou corpus n’apparaissent qu’une ou deux fois. Le deuxième mot le plus présent, par exemple, est typiquement deux fois moins représenté du premier.
Au cours de cette étape, on cherche à réduire la complexité du texte en appliquant certaines des opérations suivantes :
● Suppression des mots vides (et, le, de, …) qui sont omniprésents et ne sont pas nécessaires à la compréhension du texte
● Remplacement de tous les mots rares (moins de 5 apparitions typiquement) à une balise ‘<OOV>’ (« Out Of Vocabulary »)
● Normalisation : c’est l’opération qui consiste à la conjugaison, les marques de nombre, de genre, … On distingue :
o La racinisation qui se base sur des dictionnaires : e.g. peuvent → pouvoir
o La lemmatisation qui applique des règles d’amputation des mots : maisons → maison
● Association de la fonction grammaticale aux mots –- c’est l’étiquetage morpho-syntaxique — pour ne pas confondre le joint d’étanchéité et le fait de joindre quelqu’un par exemple
● Étiquetage de certains mots. Par exemple une séquence du type xxxx@xxx.com gagne à être estampillée par une balise <email>, autrement chaque adresse serait perçue comme un nouveau mot à ajouter au vocabulaire.
● Séparation de la phrase en unités lexicales. Cette étape consiste à transformer la chaîne de caractères qui correspond à une phrase en une liste de mots. Elle implique des choix sur la gestion des tirets, la suppression de la ponctuation, etc.
Il faut noter que ces opérations sont partiellement destructrices pour le texte, elles peuvent même le rendre inintelligible par endroit. Le choix des opérations de pré-traitement à appliquer doit donc résulter d’une inspection approfondie d’exemples et de l’impact sur les performances finales du modèle. On remarque que l’ordre des opérations de prétraitement joue un rôle, et que des opérations préliminaires de nettoyage du texte sont souvent nécessaires pour retirer des balises HTML, remplacer des acronymes spécifiques, traduire certains mots, verbaliser des émoticônes, …
En Python, la bibliothèque NLTK possède les corpus et fonctionnalités nécessaires à toutes ces tâches, même en français ! Voici un exemple de transformation typique du texte au cours du prétraitement, sur le paragraphe que vous venez de lire (« Il faut noter que … ») :
faut not oper partiel destructric pour text elle peuvent mem rendr inintelligibl endroit choix oper pre trait a appliqu doit donc result dun inspect approfond dexempl limpact le perform final model lordr oper pre trait jou rol oper preliminair nettoyag text souvent necessair pour retir balis html remplac acronym specif traduir certain mot verbalis emoticon
Un exemple plus simple, mais détaillé :
Exemple de pré-traitement d’une phrase :
initial: Bonjour.Il est 15h mon numéro de tel c’est le 06 00 00 00 00.
tokenization: [‘bonjour’, ‘.’, ‘il’, ‘est’, ’15h’, ‘mon’, ‘numero’, ‘de’, ‘tel’, ‘c’, « ‘ », ‘est’, ‘le’, ’06’, ’00’, ’00’, ’00’, ’00’, ‘.’]
stopwords: [‘bonjour’, ‘.’, ’15h’, ‘numero’, ‘tel’, « ‘ », ’06’, ’00’, ’00’, ’00’, ’00’, ‘.’]
tagging: bonjour . _HOUR_ numero tel ‘ _PHONENUMBER_ .
Vectorisation
Une fois le texte préparé, il est nécessaire d’associer un vecteur à chaque conversation dont on veut déterminer la réponse. Il existe plusieurs méthodes de vectorisation de textes. Par ordre de complexité croissante on peut mentionner le “sac de mots”, la TF-IDF, GloVe, word2vec et paragraph2vec.
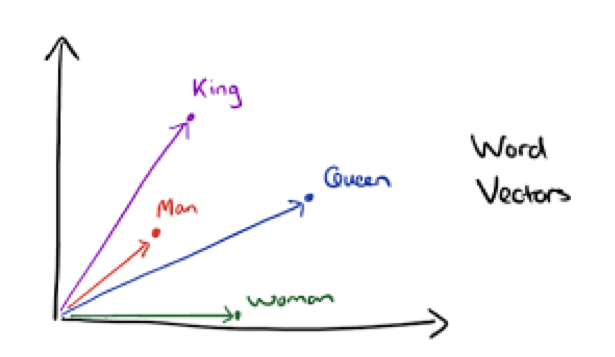
Figure 2 : word2vec. Cette représentation capture une partie des relations sémantiques.
Il faut noter que ces représentations ne tiennent pas compte de l’ordre des mots. En effet elles produisent les mêmes vecteurs pour deux phrases qui ont les mêmes mots, même dans un ordre différent. C’est un problème auquel on peut palier en utilisant des modèles séquentiels tels que des réseaux de neurones récurrents (voir notamment seq2seq), qui seront évoqués plus loin.
Une approche plus simple que nous avons régulièrement exploitée pour résoudre ce problème consiste à introduire les « n-grammes ». Dans cette approche on ne considère plus seulement la présence individuelle des mots pour déterminer la représentation d’un message, mais également les paires de mots, triplets, etc. On obtient alors un lexique très important ; par exemple mille mots différents peuvent générer jusqu’à un million de paires, et un milliard de triplets ! Cette source de complexité est modérée en ne considérant que les combinaisons les plus fréquentes : dans notre cas, les 300 n-grammes les plus fréquents étaient suffisants pour obtenir les meilleurs résultats.
L’étape de vectorisation est plus compliquée dans le cas de la conversation, car il ne faut pas seulement choisir la méthode de représentation des phrases de chaque interlocuteur mais la manière dont on représente l’ensemble de la conversation. Pour cela nous avons utilisé essentiellement la représentation TF-IDF des messages des visiteurs, tandis que pour représenter les phrases des agents nous avons opté pour une approche différente.
L’astuce simplificatrice : segmentation des phrases de l’opérateur
Le chatbot doit reproduire les phrases formulées par les opérateurs du chat. Mais ces phrases sont très diverses, surtout au vu de notre maigre ensemble de 25 000 conversations. Pour constituer un ensemble de phrases cohérentes nous avons segmenté les réponses des opérateurs pour dégager quelques phrases-types. Dans le cas où les opérateurs suivent un arbre de conversation – et c’était bien notre cas – l’historique de données est naturellement propice à cette segmentation.
Cette étape nous a permis de constituer une base d’une centaine de phrases-type. Le problème se réduit alors à une “simple” classification, où chaque conversation est représentée par un vecteur, et chaque réponse opérateur correspond à une classe.
Modélisation
Nous avons testé plusieurs modèles pour prédire la phrase-type à répondre à un message de visiteur; voici une présentation des modèles les plus pertinents.
Un modèle d’extraction de conversations similaires
Pour chaque prédiction, ce modèle simple recherche le message visiteur le plus proche dans le corpus d’entraînement, et donne la réponse du corpus associée [3]. Explicitement :
● On détermine la représentation TF-IDF à partir des phrases « visiteurs » du corpus d’entraînement
● Pour chaque nouvelle phrase de visiteur dont on veut prédire la réponse, on détermine sa représentation TF-IDF
● On calcule la similarité cosinus de cette phrase avec chaque phrase « visiteur » du corpus d’entraînement
● On prédit la réponse qui a été donnée à la phrase la plus similaire dans le corpus d’entraînement.
Ce modèle est en réalité équivalent à un modèle du plus proche voisin pour la distance cosinus. Il donne des résultats étonnamment proches de notre meilleur modèle au vu de sa simplicité (~50% d’exactitude, voir la discussion du prochain paragraphe).
Une régression logistique
Pour le problème de classification que nous avons formulé, il existe une multitude modèles. Nous avons obtenu les meilleures performances avec une simple régression logistique non régularisée, ce que suggère une relation linéaire entre les variables que nous avons créées.
Il faut noter que les performances de ce modèle dépendent de manière cruciale du découpage en « n-grammes », dans la mesure où la régression logistique ne tient compte ni de l’ordre de mots ni de même de leur co-occurrence !
Nous avons entraîné une régression logistique sur la représentation TF-IDF de dimension 300 qui mêle unigrammes, bigrammes et trigrammes. Cette régression nous permet d’atteindre une exactitude de l’ordre de 65%, dont la valeur est discutée plus bas dans cet article.
Un réseau de neurones récurrent (LSTM)
Dans le domaine du traitement automatique du langage naturel, les modèles rois sont souvent les réseaux de neurones récurrents. Ceux-ci, en tant que réseaux de neurones, sont à même de déceler des interactions complexes entre les mots. Mais ils sont de plus capables de traiter des phrases de longueur variable, tout en tenant compte de l’ordre des mots qu’ils analysent. Ces modèles ne seront pas présentés ici, mais d’excellents sites et ouvrages en détaillent le fonctionnement (voir ce blog, ou ce livre pour les plus courageux).
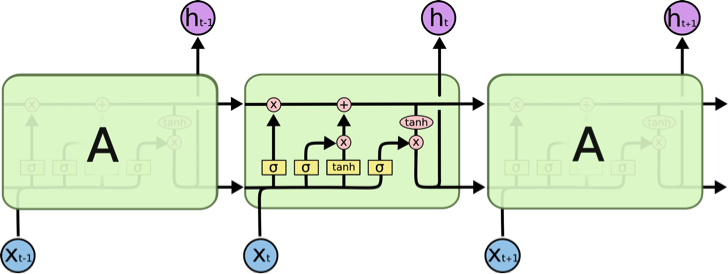
Figure 3: Schéma d’un LSTM. Tiré du blog de Chris Olah
Quelques expérimentations avec un LSTM (Long-Short Term Memory, un type de réseau de neurones récurrent) nous ont permis d’obtenir des performances légèrement meilleures que la régression logistique du paragraphe précédent (~68 % d’exactitude). Cependant l’utilisation d’un LSTM pour la prédiction requiert près d’une seconde par réponse en utilisant les 4 cœurs d’un ordinateur portable. Son utilisation ne sera pertinente que si le serveur du chatbot est à même de maintenir toutes les conversations en parallèle avec un temps de réponse raisonnable.
Nous n’avons fait qu’effleurer les réseaux de neurones récurrents. En effet, il en existe de nombreux types différents (Gated Recurrent Unit, seq2seq, …), dont chaque implémentation doit être ajustée minutieusement pour obtenir les hyper-paramètres optimaux. De plus, pour la classification de texte les réseaux de neurones récurrents sont parfois appliqués caractère par caractère ! Autrement dit on peut aussi entraîner un modèle à analyser les messages des visiteurs lettre par lettre pour prédire la réponse.
Evaluation
Évaluer les performances d’un algorithme de machine learning est toujours un point délicat ; mais pour un chatbot, ce sujet est encore plus épineux que d’habitude. Une métrique couramment utilisée, nommée BLEU, compare les séquences de mots entre les phrases prédites et les phrases à prédire. Le problème est qu’une telle métrique attribue un score de 0 à la phrase « Je vous prie de bien vouloir patienter une minute » lorsque la phrase à prédire est « Pourriez-vous attendre un instant s’il-vous-plaît ? », alors que le sens est similaire. On peut repousser légèrement cette limitation en comparant les représentations word2vec des deux phrases au lieu de comparer les mots eux-mêmes ; les similarités sémantiques sont alors prises en compte. Cependant, une étude approfondie a montré qu’aucune de ces métriques ne s’approche d’une évaluation humaine.
Nous avons donc opté pour une métrique très simple : l’exactitude (i.e. le pourcentage de phrases-type correctement prédites) vis-à-vis de nos phrases type. Cette métrique souffre du fait que prédire une phrase sémantiquement proche de la réponse réelle n’est pas valorisé. Néanmoins c’est la métrique qui nous paraissait la plus représentatives de la qualité des réponses du chatbot, par comparaison avec des essais de conversations.
Notre meilleur modèle atteint donc une exactitude de plus de 65%. Ce chiffre peut paraître assez modeste, alors que des essais nous ont permis de vérifier que le chatbot reproduit bien le comportement des agents dans une conversation. Les erreurs qu’il commet correspondent souvent à une réponse sémantiquement proche de la bonne réponse, et qui en réalité pourrait être considérée valide.
En résumé
L’entraînement d’un chatbot est un problème de d’apprentissage automatique très spécifique. Il comporte des problématiques propres de découpage des messages, pré-traitement du texte, vectorisation, modélisation, et même en ce qui concerne l’évaluation des performances, le problème semble particulièrement épineux. Pour chacune de ces étapes nous avons passé un temps important à vérifier la cohérence entre l’entrée et la sortie, et la construction d’une chaîne de traitement idoine nous a permis d’optimiser chaque opération facilement.
Notre meilleur modèle a été évalué à l’aune de plusieurs métriques, notamment son exactitude, ainsi qu’au regard de sa cohérence dans des conversations tests que nous menions nous-même. Au final, nous avons obtenu les meilleures performances avec un pré-traitement assez standard, une représentation TF-IDF de dimension 300 qui incorpore les bigrammes et trigrammes, et un modèle de régression logistique.
Ce modèle permet d’avoir des conversations avec le chatbot qui sont très proches de celles des opérateurs. Il ne reste plus qu’à le brancher au vrai chat : ce sera le sujet du troisième et dernier article de cette série, dans lequel nous analyserons l’utilisation d’un chatbot en condition de production et son interface avec une API. À suivre sur le blog de Quantmetry !
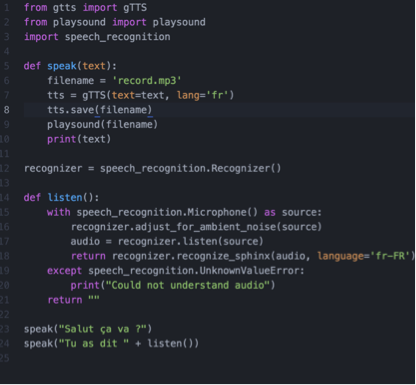
Bonus : Donnez une bouche et des oreilles à votre chatbot !
Bonne nouvelle : il est assez simple de doter notre nouveau chatbot de la parole ! Voici un exemple d’un script python qui prononce une phrase (« Salut, ça va ? ») via votre micro, écoute votre réponse, et vous permet de vérifier qu’il vous a bien compris en répétant votre phrase. Il repose sur gTTS et SpeechRecognition.