“Off-the-shelf” APIs or custom model?
Speech transcription is used in more and more use cases. Most of the large internet companies offer speech-to-text APIs. Even though those APIs are powerful and easy-to-use, they present major drawbacks:
-
Their price is not always negligible;
-
They bring privacy and security issues as the audio is sent over the Internet;
-
They are trained for generic applications and work poorly on specific use-cases.
At Quantmetry we worked on a challenge organized by Airbus to transcribe air traffic conversation between aircraft pilots and towers of controls. In this application the sounds are noisy, with high speech rate and lots of domain-specific vocabulary. We found that generic « off-the-shelf » APIs perform poorly on such difficult problems, and that training a custom model gives much better results.
See bellow some exemples of audio, with the comparison of the transcription of Google API and the one of model we built.

Google API transcription:
behind this traffic from my phone and internet page lesson right behind
Custom model transcription:
beeline four two bravo behind the traffic from mike four line up runway three two left and wait behind
Real transcription:
beeline four two bravo behind this traffic from mike four line up runway three two left and wait behind
Google’s transcription is far from the real transcription. It gets some words right (« traffic », « behind »), but it adds some words that would not be used in the air traffic context (« internet page »). In comparison, our custom model gets only one word wrong (« the » vs « this »).
Google API transcription:
7 :4 0 to write my paper to write on
Custom model transcription:
Eurowings seven four three two is huh right mike eight cross runway three two right on the the and contact ground one two one nine goodbye
Real transcription:
Eurowings seven four three two first huh right mike eight cross runway three two right on the other side contact ground one two one nine goodbye
It is interesting to compare the transcription « write » by Google vs « right » by our model (and the real transcription). Those words are pronounced the same way, but « right » is much more probable in the air traffic context. This was learnt by our custom model, but not by Google which is trained for the generic case.
Google API transcription:
I just want a donut
Custom model transcription:
KLM six three tango reduce one eight zero knots
Real transcription:
KLM six three tango reduce one eight zero knots
A donut sounds nice though…
Those exemples illustrate that « off-the-shelf » APIs have difficulty to perform well on specific applications. In that case, it is better to train specific custom models.
Quantitatively, the
Word Error Rate (or WER
, the percentage of error on words between the inferred and the real transcription) on a set of test audio is much lower using our algorithm.
Comparison of the error of our algorithm and Google API on a test set of our use case. The lowest the Word Error Rate is, the most precise is the model.
So, how to train a custom speech recognition system?
There are two main approaches:
-
The traditional approach is built around several components (sound preprocessing, pronunciation model, acoustic model, etc.) that are put together to form a decoder. The downside is that this requires many hand-engineered features.
-
New approaches are based on state-of-the-art deep learning algorithms, that convert speech to text directly, without the need for several hand-engineered stages.
We used a deep-learning approach,
Deep Speech, that was developed by Baidu and implemented by Mozilla in an
open-source project. It is based on two main elements:
The following paragraphs describe in more details how the algorithm work, and how to train it in practice.
The acoustic model: converting sounds to letters
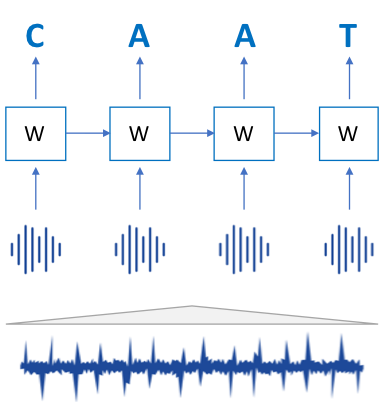
The acoustic model detects the letters that are said along the audio. To do so, the audio is cut into a sequence of small chunks of 0.1 seconds, and a model tries to detect the letter pronounced in each one of them. This type of problem is known as sequence-to-sequence: the model translates a sequence of sounds to a sequence of letters.
Recurrent Neural Networks (« RNN ») are a type of neural networks that allow to carry information along a sequence. Each step of network takes as input both an element of the sequence, and some context information transferred from the preceding elements. Our inputs here are the spectrograms of the audio chunks, and our outputs are the letters pronounced on those chunks.
Representation of a Recurrent Neural Network for transcription. The audio wave is first cut into a sequence of chunks, which spectrograms are fed to the network. Each step of the network takes as input both a spectrogram and the information carried from the previous stpes; it outputs the letter pronounced in the chunk.
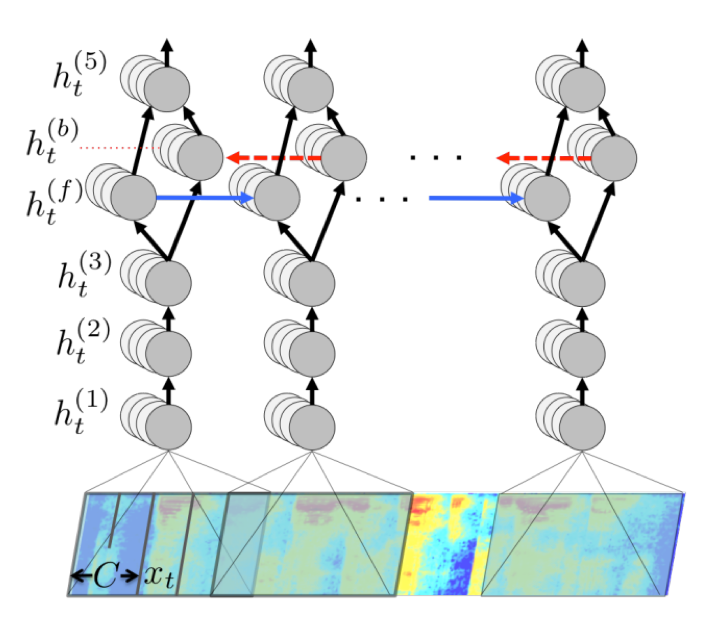
The architecture proposed by Deep Speech is a bit more complex than a vanilla RNN, with several fully connected layers for abstraction, and a bi-directional RNN to take into account the context from both the past and the future and the sequence.
Architecture proposed in Deep Speech. The first three layers are fully connected. They are followed by a forward and a backward RNN (respectively carrying information from the past and the future of the sequence). The last layer is a softmax, which outputs a probability that a given letter is pronounced at a given step of the sequence.
The RNN outputs a raw sequence of characters. This sequence needs to be retreated to be turned into a meaningful sequence. This is the goal of the language model.
The language model: bringing meaning to the transcription
Language models are used to choose which sequence of words make the most sense for a given use-case. They are especially useful to differentiate between words that sound the same but are written differently. For instance, even though “right” and “write” sound the same, a good language model would prefer to output the sentence “please turn right” over “please turn right” as it makes more sense.
Language model are trained easily, as they do not require labeled data. There exist several approaches to train a language model. The most intuitive one, called n-grams, simply relies on the number of times that a sequence of n words occurs in the training corpus.
The example bellow shows the training of a bigram (n-gram with n=2) model for a corpus composed of two simple sentences.
The probability of a sentence is computed using the chain rule. For instance, with the model above, the probability of the sentence “the cat is hungry” is:
Putting it together through an objective function
Every model of machine learning needs an objective function to optimize. Here is the one of our model:
The weights of the acoustic model are learnt by maximizing the objective function for the real transcription. For a new audio, the transcription is chosen as the sequence of characters that maximizes the objective function.
Implementing the model
Three points are to be noticed regarding the implementation of the model.
1. Amount of data
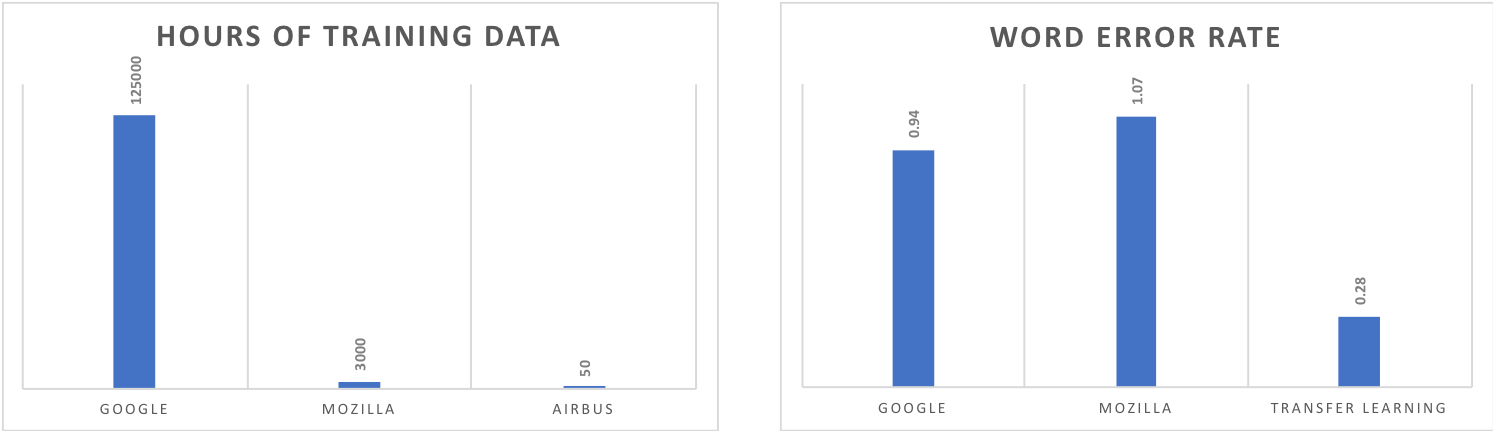
Training a transcription model requires a lot of data: Google uses more than
100,000 hours of audio, Mozilla opened-source a model trained on 3,000 hours, but for our use-case we only had 50 hours of air traffic data. With so few data, we could not train any good model. Therefore we used transfer-learning: we initialized our network with the weights learnt by Mozilla on 3,000 hours, and we re-trained them on our specific data. This resulted in a high increase of the performance of the model.
Comparison of the hours of training data and the performance of Google’s model, Mozilla’s one and the one trained with transfer learning. The added-value of transfer learning is clear.
2. Training on the cloud
The network we used has more than 120 millions parameters. It requires a lot of memory and computation power to train. We quickly ran out of computational power on our own physical machine. We therefore turned to the Cloud where we could rent very powerful machines to train our network for few hours.
3. Predict time comparison
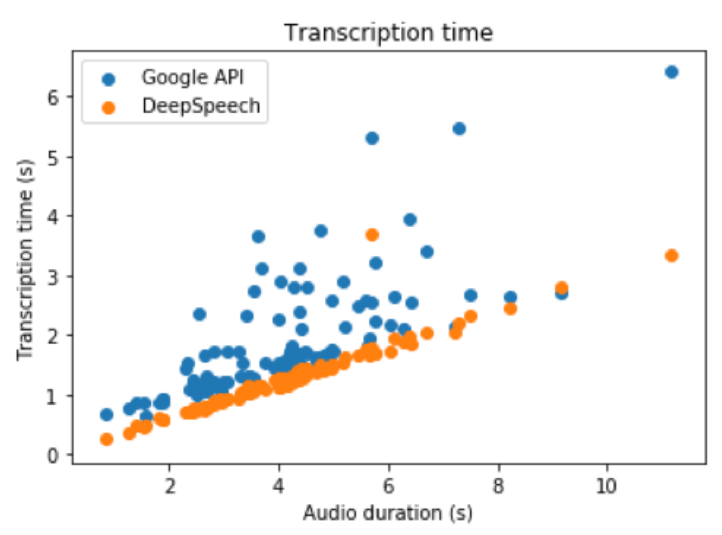
Our model runs on device. This ensures both privacy (the data does not travel through the Internet) and quick transcription time (there is not upload time). This is demonstrated by our benchmark, in which Google API took a mean time of transcription of 50% the time of the audio, while our model took only 30% the time of the audio.
Comparison of transcription time for Google API (on the Cloud) and Deep Speech (on device)
Conclusion
Speech transcription is more and more commun. There exist several « off-the-shelf » APIs that are easy to use, however those APIs are trained for a generic case and they tend to perform badly on specific use-cases. In such a situation, it is a preferable to use a custom model, especially that it is now accessible easily thanks to the progress made in the deep-learning and open-source community.