

Une petite histoire du Machine Learning

Le Machine Learning (ML) (1) a émergé dans la seconde moitié du XXème siècle du domaine de l’intelligence artificielle et correspond à l’élaboration d’algorithmes capables d’accumuler de la connaissance et de l’intelligence à partir d’expériences, sans être humainement guidés au cours de leur apprentissage, ni explicitement programmés pour gérer telle ou telle expérience ou donnée spécifique.
LES DÉBUTS DE L’INTELLIGENCE ARTIFICIELLE
L’intelligence artificielle (IA) est l’une des disciplines scientifiques et d’ingénierie les plus récentes et les plus florissantes. Les pionniers de l’IA ont commencé leurs travaux vers la fin de la seconde guerre mondiale. En 1956, dix pionniers de la recherche américaine en théorie des automates, des réseaux de neurones et de l’intelligence se sont réunis pour un workshop de deux mois à Dartmouth College : J. McCarthy (Dartmouth), Minsky (Princeton), C. Shannon (Bell Labs/MIT), N. Rochester (IBM), T. More (Princeton), A. Newell (Carnegie Tech), H. Simon (Carnegie Tech), A. Samuel (IBM), R. Solomonoff (MIT), O. Selfridge (MIT). C’est lors de ce workshop, que le terme d’IA est apparu : l’IA était officiellement née.
Rapidement, l’IA a suscité beaucoup de débats parmi les spécialistes quant à l’approche à adopter. Plusieurs écoles ont vu le jour. Les comportementalistes cherchaient à construire des IA capables de penser ou agir comme les humains. Les rationalistes s’orientaient vers une vision rationnelle des IA qui devaient selon eux produire des fonctionnements et des raisonnements rationnels, plutôt que d’essayer à tout prix d’imiter le cerveau humain.
Les rationalistes ont donc d’abord tenté de construire des programmes capables de résoudre n’importe quel problème décrit par une notation logique. Néanmoins, la traduction d’une connaissance complexe ou informelle dans le cadre de la logique est très ardue. D’autre part, construire des IA capables de produire un raisonnement et un comportement rationnel suppose le traitement exact de nombreux paramètres : une capacité de calcul inaccessible à l’époque.
Dans l’approche comportementaliste, le test de Turing (très récemment revenu sur le devant de la scène avec Eugene Goostman (2), ou certains films médiatisés comme Ex machina (3) a été pensé pour fournir une définition de l’intelligence. Une IA passe le test de Turing si un humain n’est pas capable de déterminer dans une conversation si l’IA est un humain ou un ordinateur. Une telle prouesse suppose un certain nombre de capacités : traitement automatique de la langue humaine (Natural Language Processing), représentation (stockage ordonné) des connaissances et des expériences passées, facultés de raisonnement automatique et du ML, c’est-à-dire une capacité d’adaptation en fonction des circonstances. Cet ensemble de facultés nécessaires pour une intelligence sont particulièrement difficiles à développer simultanément dans une IA.
A ce jour, on ne peut pas dire qu’une IA ait encore passé le test de Turing de façon incontestable, même si la perspective devient plus plausible avec les avancées scientifiques et technologiques.
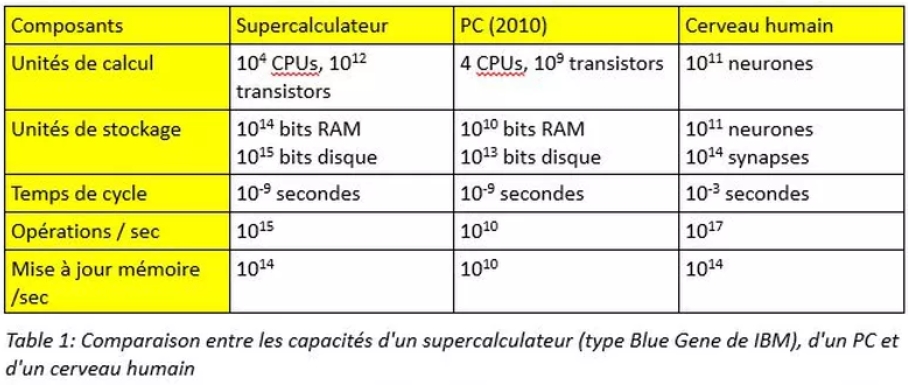
Le tableau 1 montre une comparaison des capacités d’un supercalculateur, d’un PC et d’un cerveau humain. Chaque génération de hardware représente une amélioration de la vitesse et de la capacité de calcul, ainsi qu’une baisse des coûts. Jusque vers 2005, les constructeurs amélioraient surtout la vitesse de calcul, puis on a commencé à multiplier le nombre de CPUs. Actuellement, la tendance est à la parallélisation massive des calculs et du stockage qui offre des perspectives impressionnantes de puissance.
LA SINGULARITÉ
Le concept de singularité technologique contient l’idée, qu’à partir d’un point de l’évolution humaine (la singularité), les IA dépasseront les performances humaines de raisonnement d’une part et les capacités d’évolution de l’humanité d’autre part. Les progrès seraient alors portés par des IA que la société humaine ne serait plus capable de contrôler. L’idée remonte aux années 1950 avec John von Neumann et a été débattue par I. J. Good, V. Vinge (4) ou R. Kurzweil (5). On la retrouve fréquemment dans la culture populaire avec 2001 Odyssée de l’espace, Terminator, Minority Report, Matrix, et plus récemment Her ou encore Transcendance.
La pertinence de ce concept est encore très contestée et débattue dans la communauté scientifique aujourd’hui. Nous nous contentons ici de mentionner l’existence du concept, car il est intéressant de le connaître, mais sans engager de débat.
PREMIÈRES AVANCÉES
Les premiers travaux d’IA reconnus comme tels ont été menés par McCulloch et Pitts en 1943 avec le premier modèle de neurones artificiels : chaque neurone est caractérisé comme étant ouvert ou fermé et a la capacité de s’ouvrir en réponse à une stimulation par un nombre suffisant de neurones voisins afin de transmettre un signal. Un autre pionnier de l’IA, Hebb, a proposé en 1949 un système de neurones où les connections entre neurones sont pondérées avec des règles de modification des poids constituant un apprentissage.
La période qui a suivi jusque dans les années 60 a été ponctuée de grandes avancées et de grands espoirs (6) : le « General Problem Solver » de Newell et Simon, qui tentait d’imiter les méthodes humaines de résolution des problèmes ; le « Geometry Theorem Prover », de Gelernter, capable de prouver des théorèmes mathématiques difficiles ; les premiers programmes de jeu d’échecs (A. Samuel) ; la création de Lisp (J. McCarthy), devenu par la suite le langage de programmation dominant pour les IA ; le « Advice Taker » de McCarthy, un programme hypothétique construit pour utiliser la connaissance acquise afin de résoudre des problèmes : la première apparition des principes de représentation formelle et explicite des connaissances et la manipulation de cette représentation par des processus de déduction.
Bien des personnes, incluant des responsables de programmes gouvernementaux se sont alors enflammées en imaginant des IA capables d’atteindre les capacités du cerveau humain.
UN COUP D’ARRÊT À L’IA
Après l’emballement des années 50, les années 60 ont ramené plus de réalisme et de pragmatisme dans le domaine. D’abord, on s’est rendu compte que la plupart des IA fonctionnaient surtout par manipulations syntaxiques simples et non par des raisonnements véritablement basés sur la connaissance. Dans le cas de la traduction par exemple, la machine a besoin d’avoir une compréhension fine du contexte pour traduire sans ambiguité. Les IA échouaient à traduire des textes même simples. Outre la traduction, beaucoup de problèmes (théorèmes mathématiques, raisonnements par déduction, problèmes complexes impliquant plusieurs sous tâches) s’avéraient impossibles à résoudre en raison du nombre de paramètres en jeu.
Enfin, les structures de réseaux de neurones proposées étaient beaucoup trop limitées en taille et en capacité de représentation de la connaissance pour espérer produire un comportement intelligent. En 1969, Minsky et Papert ont démontré que les perceptrons (des modèles simples basés sur les travaux de McCulloch et Pitts) ne pouvaient construire qu’une représentation très minime : ils n’étaient par exemple pas capables d’implémenter la fonction XOR (7) qui permet de reconnaître si deux inputs sont différents.
La perspective de construire des systèmes plus complexes était en décalage avec la quantité de données disponibles et le stockage (c’est-à-dire la représentation des connaissances) nécessaire. D’autre part, la puissance de calcul des ordinateurs de l’époque ne permettait pas de mettre en oeuvre un apprentissage de ces modèles. Les espoirs placés dans l’IA ont donc été considérablement déçus et beaucoup de programmes de recherche ont été arrêtés. Ceci a amené un ralentissement brutal des investissements dans la recherche, en particulier celle axée sur les réseaux de neurones et cherchant à reproduire les raisonnements humains.
PRAGMATISME ET MODESTIE : L’ÉMERGENCE DU MACHINE LEARNING
Entre les années 70 et 80, les efforts se sont portés sur des systèmes d’expertise restreints à des domaines spécifiques comme l’analyse en chimie, le diagnostic médical, les systèmes experts de l’industrie, et les robots ou logiciels très spécialisés.
Des travaux sur les modèles de Markov, les avancées théoriques et techniques sur les simulations Monte Carlo, et le développement du formalisme des réseaux Bayésien ont ponctué cette période de vingt ans, avec une utilisation dans des domaines spécifiques avec relativement peu d’échanges interdisciplinaires. La fin des années 80 a également vu le retour des réseaux de neurones, avec la (ré)-invention de l’apprentissage par backpropagation et son application à des problèmes spécifiques comme la reconnaissance de caractères. Mais il faudra encore attendre le milieu des années 2000 pour voir des succès sur des problèmes plus complexes et dans des domaines plus larges.
L’émergence du ML en tant que discipline à part entière s’inscrit dans cette dynamique de pragmatisme et de modestie ; elle a eu lieu dans les années 90 avec la volonté de s’attacher à résoudre des problèmes très concrets et plus humbles, en lien direct avec les données à disposition.
Parallèlement à cela, l’arrivée d’Internet a permis d’établir des collaborations plus fortes entre les différents groupes de recherche, une communication plus rapide des résultats et surtout la possibilité de reproduire les expériences en utilisant des dépots de données test et de codes. L’interdisciplinarité avec l’ingénierie et l’informatique a également permis d’avancer beaucoup plus vite sur ces systèmes. Avec une approche scientifique plus systématique, les experts ont pu concentrer leurs efforts à améliorer ensemble les théories et les modèles existants et prometteurs, plutôt que de fonctionner de manière isolée.
Notons que c’est environ à ce moment de l’histoire que les mathématiques et plus particulièrement les statistiques ont été réintroduites dans le développement des aspects théoriques et appliqués du ML.
ENTRÉE DU BIG DATA
Il faut aussi noter l’importance de l’arrivée du Big Data : la disponibilité d’ensembles de plus variés de données massives et l’augmentation des capacités de calcul et de stockage.
Le développement des technologies Big Data a permis de dépasser des limites importantes du ML : l’absence d’une quantité suffisante de données ne permet pas d’entraîner efficacement un algorithme de prédiction. Par conséquent, en l’absence de telles données, on ne dispose pas d’expérimentations probantes ; il est alors plus difficile de développer les fondements théoriques d’un algorithme de ML.
Le Big Data pose également des challenges d’ordre théorique pour le ML, comme les problèmes de grandes dimensions : le croisement de nombreuses sources de données diluent fortement l’information. On augmente ainsi le nombre de variables à explorer, mais pas le nombre d’exemples disponibles.
QU’EST-CE QUE LE ML ?
Le ML est une sous-partie de l’intelligence artificielle qui s’attache a créer des machines qui se comportent et opèrent de manière intelligente ou qui simulent cette intelligence.
L’IA n’implique pas forcément un apprentissage de la machine. Par exemple dans le cas des machines qui jouent aux échecs. : une IA ne saura pas faire face à une stratégie nouvelle d’un joueur humain en apprenant de l’expérience pour adapter son comportement, à moins d’avoir été conçue dans le cadre du ML.
Pour qu’une machine apprenne et s’adapte automatiquement, la connaissance qu’elle peut extraire de ses expériences doit être stockée sous une certaine forme, de façon à pouvoir être utilisée dans un but précis. En général, le but est de prédire le futur (un comportement, un nombre, etc.), mais une machine peut également être construite pour générer artificiellement de nouvelles données (machines génératives) ressemblant statistiquement aux données originales, ou bien pour détecter des schémas de fonctionnement (causalités, structure d’un réseau, etc.).
Comme nous l’avons mentionné plus haut, le ML a beaucoup puisé dans les mathématiques et les statistiques. Classiquement, les statistiques s’attachent à permettre une compréhension globale des données : quelles sont les caractéristiques d’une variable (minimum, maximum, moyenne) ? De façon plus avancée, quelle est la distribution statistique ? Peut-on modéliser le processus de génération des données en essayant d’extraire le bruit contenu dans les données ? Le modèle le plus simple est la régression, très utilisée dans de nombreux domaines. Entraîner (faire apprendre) un modèle de régression c’est faire du ML. On peut donc faire remonter le machine learning au XVIIème siècle avec Legendre et Gauss et leur méthode des moindres carrés.
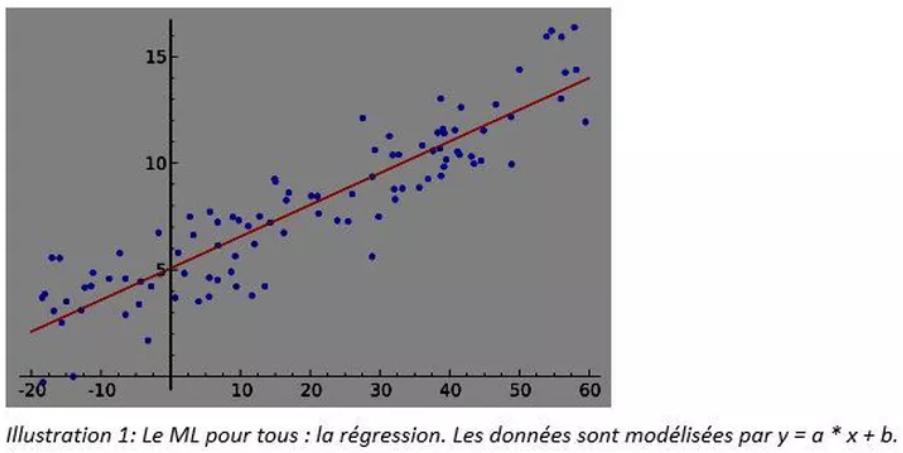
Le ML peut être vu comme l’ensemble des méthodes permettant de déterminer la meilleure manière de modéliser les données. Parmi ces méthodes, la plus centrale et la plus importante est l’apprentissage. L’apprentissage consiste, pour un modèle donné, à choisir les meilleurs paramètres possibles pour décrire les données. Pour une régression simple, il s’agit de choisir le meilleur couple a, b (voir figure 1). Dans ce cas, la connaissance acquise par l’expérience (les différents échantillons de données sont autant de micro-expériences), est stockée dans ces deux coefficients a et b. Un modèle plus complexe stocke sa connaissance dans un nombre beaucoup plus grand de coefficients pouvant dépasser le million voire le milliard (pour les réseaux de neurones complexes par exemple), mais le principe est le même : le ML permet à une machine (le modèle, simple ou complexe) d’apprendre et de stocker sa compréhension du monde.
Les modèles et leurs procédures d’apprentissage associées incluent des idées découlant directement des statistiques et des mathématiques, mais pas uniquement. Le pragmatisme a amené la recherche à repousser les frontières interdisciplinaires. La physique (notamment la physique statistique pour les machines de Boltzmann, un cas particulier des réseaux de neurones), la biologie et la neurobiologie, l’imagerie et l’ingénierie ont été des sources très importantes d’idées pour développer des modèles de ML et les techniques d’apprentissage.
On regroupe les algorithmes de ML en deux ou trois grandes classes, qui correspondent à différents types d’apprentissage :
-
l’apprentissage supervisé : on donne à l’algorithme un certain nombre d’exemples (input) sur lesquels apprendre, et ces exemples sont « labellisés », c’est-à-dire qu’on leur associe un résultat désiré (output). L’algorithme a alors pour tâche de trouver la loi qui permet de trouver l’output en fonction des inputs.
Un exemple typique est la classification d’email en deux classes : « spam » ou « ham ». L’input dans ce cas est l’email, soit brut, soit formaté (préparé sous forme d’un ensemble de « features », ou variables) de manière à optimiser la performance de l’algorithme. L’output est un label, 0/1, ou Spam/Ham.
On peut aussi établir des diagnostics médicaux : un patient est-il atteint d’un cancer ou non (output), en fonction de ses symptômes et phénotypes (input)
Un autre exemple : la reconnaissance de chiffres manuscrits (l’image est-un « 1 » ou un « 9 » ?). Dans ce cas, l’input est un ensemble de pixels, et l’output prend 10 valeurs, de 0 à 9. -
l’apprentissage non-supervisé : ici, on ne fournit aucun label à l’algorithme et il doit découvrir sans assistance humaine la structure caractéristique de l’input.
L’exemple typique est le clustering. L’algorithme va regrouper les exemples en différents clusters ou classes. Un cas d’usage est la reconnaissance d’images : un algorithme de clustering va pouvoir regrouper des images de voitures dans un même cluster, et des images d’immeubles dans un autre cluster. Il pourra faire cela car il sait apprendre qu’une voiture a pour caractéristique d’avoir des roues, et une forme particulière et un bâtiment des formes plus droites. Cet apprentissage, l’algorithme le fait seul, sans qu’un humain lui introduise explicitement le concept de voiture ou de bâtiment, ni ne lui explique qu’il doit chercher la présence de roues pour identifier une voiture. Il apprend seul le concept de courbe, de droite, de coin, etc., indépendamment des représentations humaines. Cet indépendance peut parfois rendre le fonctionnement de l’algorithme assez opaque et difficile à interpréter. L’humain est entraîner par ses semblables à représenter le monde et interpréter ses expériences comme les autres, c’est pour cette raison que nous pouvons communiquer entre nous des descriptions. Nos représentations humaines sont très orientées sur la vue. Les autres sens ont une représentation peut-être moins consensuelle. Deux personnes différentes auront quelques difficultés à expliquer mutuellement leurs expériences gustatives par défaut d’une représentation commune. C’est un peu la même chose avec un algorithme de reconnaissance d’image. Il va construire sa propre représentation et un humain pourra avoir des difficultés à la comprendre.
-
l’apprentissage par renforcement : c’est un peu un intermédiaire entre les deux premiers
-
types d’apprentissage. L’algorithme est concu pour chercher à optimiser à tout prix une récompense quantitative, positive ou négative, à partir d’expériences correspondant à différentes situations.
Un exemple des plus actuels et des plus impressionnants d’apprentissage par renforcement est le robot Big Dog de Boston Dynamics (8). C’est un robot à quatre pattes, capable de marcher, courir, grimper et de porter des charges lourdes. Le robot est entraîné à marcher par renforcement : sa récompense est forte et positive s’il reste debout, sa récompense est négative s’il tombe. Il est programmé pour explorer les différents mouvements qu’il peut effectuer et faire ses propres expériences. C’est ainsi qu’il apprend seul à monter une pente et à optimiser la manière de poser ses pattes (vitesse, fréquence, angle, etc.) d’une manière très similaire à un animal ou un humain.
L’apprentissage supervisé est un peu plus intuitif, en partie parce que maints algorithmes d’apprentissage supervisés ont été utilisés avec succès dans beaucoup de cas. Parmi les modèles d’apprentissage supervisé les plus populaires et les plus largement utilisés, on trouve la régression linéaire, la régression logistique.
En 1984, Leo Breiman, Jerome Friedman, Richard Olshen et Charles Stones posent une des pierres angulaires du ML, en introduisant les bases théoriques de l’apprentissage moderne des arbres de décision, avec des techniques innovantes et des algorithmes permettant de traiter de grandes quantités de données. Leur travail a eu une très forte influence et en 2001, Leo Breiman (9) et Adele Cutler (10) introduisent les forêts aléatoires (ou random forests), un modèle de ML aujourd’hui extrêmement populaire et puissant. De même, le gradient boosting, un autre type de modèle très populaire est le produit du travail de Breiman, Friedman, Mason, Baxter, Bartlett et Frean (11).
Enfin, depuis quelques années, les réseaux de neurones sont revenus sous les projecteurs. Ils constituent un domaine à part entière du machine learning. Comme on l’a vu, leur histoire commence dans les années 50 et ils ont connu plusieurs revers jusqu’en 1989, avec l’application enfin réussie de l’algorithme de backpropagation aux réseaux de neurones profonds (LeCun), puis en 2006 avec plusieurs avancées techniques importantes dans l’apprentissage des réseaux de neurones (dans les travaux de Hinton, Bengio, Ranzato, LeCun, Larochelle, …).
Les arbres et des forêts de décision, les réseaux de neurones ne sont que quelques exemples populaires de modèles de ML. Bien d’autres modèles existent et sont utilisés avec succès : l’apprentissage bayésien, les réseaux bayésiens, les support vector machine, les k-means (1992), DBSCAN (1996), OPTICS (1999) pour le clustering, ou encore les algorithmes génétiques dont les fondements remontent à 1975 (12).
La bonne connaissance des fondements théoriques et des techniques d’apprentissage permet de choisir le modèle le mieux adapté à la modélisation. C’est l’un des rôles du data scientist dans les projets d’analyse de données.
LA RÉUNIFICATION ?
Ces 20 dernières années, l’IA s’est concentrée sur la conception d’agents intelligents capables de percevoir et d’agir dans un environnement donné. Les algorithmes de machine learning se sont développés et deviennent de plus en plus complexes. La frontière entre les deux domaines tend aujourd’hui à disparaître. Pour résoudre des problèmes complexes faisant intervenir divers phénomènes à des échelles différentes, la recherche tend à combiner IA, ML, robotique et algorithmie dans des systèmes puissants et complexes.
Les robots de Boston Dynamics comme Big Dog (13) ou WildCat (14) en sont des exemples impressionnants : ils combinent l’ingéniérie robotique avec les machines intelligentes entraînées avec du ML pour apprendre par l’expérience.
LES CHALLENGES DU ML
Ces dernières années, l’arrivée du Big Data et la puissance de calcul disponible ont conduit à de grandes avancées dans le ML, y compris sur des techniques d’apprentissage optimisées pour des modèles aussi simples que les régressions. Les challenges sont encore là aujourd’hui pour la recherche. On doit encore poser les fondements théoriques de domaines entiers du ML : en effet, certains modèles sont connus et efficaces, mais la connaissance est parfois très phénomélogiques et basée sur l’observation de nombreuses expériences.
D’autre part, des challenges se posent quant à l’application du ML sur des volumes importants de données, à la parallélisation des algorithmes sur des architectures distribuées et l’implémentation sur des technologies comme Hadoop, Spark, Flink, etc.
Quoi qu’il en soit, les systèmes développés dans les laboratoires de recherche ont définitivement franchi la frontière vers les applications dans la finance, le marketing, l’industrie, l’Internet des objets, et la vie de tous les jours. Les équipes de statisticiens, d’actuaires et de quant des banques et assurances ont été parmi les premiers à exploiter leurs données avec le ML afin d’évaluer les risques financiers, de lutter contre la fraude ou pour des applications marketing / connaissance clients.
Aujourd’hui les industries françaises s’intéressent de plus en plus à la valeur de leurs données : la maintenance prédictive, l’optimisation des chaînes de production, la construction de véhicules autonomes sont autant d’applications du ML qui pourront générer des gains économiques significatifs.
La reconnaissance d’image avec Facebook, Google, et bien d’autres a été très médiatisée car elle nous touche tous. Enfin, la médecine, la recherche pharmaceutique, la ville intelligente, les transports, le BTP, la modernisation de l’action publique, la cybersécurité et encore bien d’autres domaines tirent déjà des bénéfices notables de l’analyse des données et du ML.
La capacité du ML à s’appliquer sur des données réelles de production et à produire des résultats tangibles et utiles n’est donc plus à démontrer.
Néanmoins, en dehors de secteurs bien spécifiques (banque, assurance, RTB, marketing web, les réseaux sociaux et les grands du Web), ces applications bien que réussies, sont encore expérimentales. Le challenge qui se pose aujourd’hui est l’intégration du ML dans les systèmes d’information. Les entreprises devront créer des équipes dédiés à l’analyse des données, qui devront travailler avec les équipes IT pour faire évoluer les systèmes d’information et mettre en place une gouvernance des données et des contrôles qualité robustes. En effet, bien souvent les données ont été créées dans le passé pour des applications opérationnelles bien spécifiques et non pour créer de la valeur par l’analyse et la modélisation. La prise de conscience de la valeur de la donnée entraîne des changements dans les entreprises : de nouveaux rôles (la gouvernance de la donnée par exemple), des collaborations plus fortes (métier/DSI), des nouvelles façon de travailler (agile versus cycle V), etc.
Demain, l’un des plus importants challenges sera certainement la construction non pas de modèles isolés, spécifiquement entraînés pour un cas d’usage bien précis, mais des architectures complexes de modèles permettant de gérer plusieurs phénomènes intriqués à différentes échelles, comme l’illustre notre récent article sur les bâtiments connectés.
UNE PRISE DE CONSCIENCE
Récemment, plusieurs milliers de signatures ont été recueillies sur une lettre ouverte (15) assez médiatisée, et notamment celles de grands noms de l’intelligence artifielle et du machine learning comme Yoshua Bengio, Yann LeCun, Geoffrey Hinton, Stuart Russell, Peter Norvig, ainsi que des personnalités renommées comme Stephen Hawking, Elon Musk, Steve Wozniak.
Cette lettre suit une autre lettre ouverte parue fin 2014 (16) qui, bien que très positive sur les avancées de l’intelligence artificielle et ses bénéfices pour l’humanité, avertissait déjà sur ses écueils potentiels. Ici, les signataires affirment que la construction d’armes autonomes capables de sélectionner et d’attaquer des cibles sans intervention humaine sera possible d’ici quelques années. Faisant part de leur inquiétude et de leur refus de participer à une course aux armements, ils appellent à un bannissement des armes offensives autonomes.
Les révélations d’Edward Snowden ont également provoqué une prise de conscience générale sur les capacités des gouvernements et entreprises à surveiller les populations. Bien des villes et d’entreprises sont tentées d’installer de plus en plus de vidéosurveillance et d’utiliser des systèmes de ML capables d’alerter les services de sécurité.
L’Internet des objets poussent les constructeurs et les exploitants à installer de plus en plus de capteurs afin de tirer parti des capacités du ML. On assiste aujourd’hui à une inflation impressionnante du nombre d’objets connectés générant, collectant et envoyant des données.
Le ML pose donc des problématiques dont il faut se saisir : l’éthique, la protection de la vie privée, la cybersécurité, le coût en énergie et la consommation de matières premières non renouvelables. Les législateurs, les pouvoirs publics, la société civile et les citoyens se doivent d’être vigilants sur les dérives et l’emballement du système. En premier lieu, décideurs, ingénieurs, et data scientists ont pour devoir de rester pragmatiques, vigilants sur ce que leur travail implique. Ils ne doivent pas oublier que les données et leur analyse ont un coût qui doit être maîtrisé sur tous les plans.
[1]Le Machine Learning est aussi appelé « apprentissage automatique », mais le terme anglais est plus utilisé.[2]http://www.sciencesetavenir.fr/fondamental/20140609.OBS9871/intelligence-artificielle-eugene-goostman-est-le-tombeur-du-test-de-turing.html
[3]https://fr.wikipedia.org/wiki/Ex_Machina_%28film%29
[4]Vinge, V (1993). The Coming Technological Singularity: How to Survive in the Post-Human Era. In VISION-21 Symposium. NASA Lewis Research Center and the Ohia Aerospace Institute. [5]Kurzweil, R. (2005). The singularity is near: When humans transcend biology. Penguin. [6]Russel, Norvig, Artificial Intelligence, A Modern Approach, Prentice Hall, 2009 [7]https://fr.wikipedia.org/wiki/Fonction_OU_exclusif
[8]http://www.bostondynamics.com/dist/BigDog.wmv
[9]http://link.springer.com/article/10.1023/A:1010933404324
[10]http://www.salford-systems.com/products/randomforests
[11]Boosting Algorithms as Gradient Descent in Function Space by L Mason, J Baxter, P Bartlett, M Frean – 1999 http://citeseer.ist.psu.edu/viewdoc/summarydoi=10.1.1.51.6893
[12]Adaptation in Natural and Artificial Systems, John H. Holland (1975) http://psycnet.apa.org/index.cfm?fa=search.displayRecord&uid=1975-26618-000
[13]https://www.youtube.com/watch?v=cNZPRsrwumQ
[14]https://www.youtube.com/watch?v=wE3fmFTtP9g
[15]http://futureoflife.org/AI/open_letter_autonomous_weapons
[16]http://futureoflife.org/AI/open_letter
