

Modèle d’attribution : cap vers le data-driven

Comment des modèles d’attribution intelligents vont-ils permettre d’affiner la connaissance des parcours clients et d’individualiser les décisions marketing ? Le marketing data-driven apporte une réponse à cette question en développant de nouveaux modèles d’attribution. Les enjeux de ce nouveau paradigme sont avant tout business, mais ils ne pourront être relevés qu’avec une meilleure maîtrise de la donnée et une mise à niveau des algorithmes d’attribution.
Selon une étude réalisée par IBM[1] la performance globale sur les investissements marketing augmente de 25 à 50% grâce au passage d’un modèle d’attribution classique à un modèle data-driven.
Dans cet article, les deux premières parties traitent des enjeux business et les deux dernières offrent un éclairage technique sur les différentes approches.
1. Dépasser la vision “dernier clic”
Chaque parcours client est unique, il est constitué de tous les points de contact en amont de la réalisation de l’objectif: recherche Google, bannière sur un site, réseaux sociaux, article de blog…
D’après une étude Criteo[2], presque 80% des annonceurs utilisent encore le modèle du dernier clic. Dans l’exemple de parcours client ci-dessous, on distingue plusieurs modèles d’attribution classiques qui vont chacun donner une contribution différente de chaque point de contact dans la vente. Par exemple, la Newsletter serait créditée de 100% de la vente dans un modèle “dernier clic”:
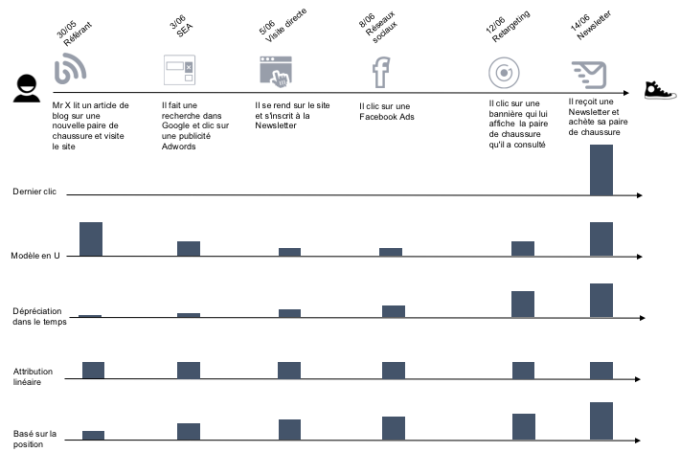
À partir d’un modèle d’attribution découle une vision de la performance. Aujourd’hui, de nombreuses décisions sont prises basées sur des KPI construits autour de modèles d’attribution simples (Dernier clic, …). Or, ces modèles ne rendent pas compte de la complexité des parcours clients. Une vision data-driven reflète cette complexité et apporte une meilleure compréhension au moment de la prise de décision.
Nos travaux de recherche chez Quantmetry traitent de l’attribution data-driven. Grâce à des algorithmes qui vont analyser de gigantesques jeux de données, on va pouvoir expliquer la contribution de chaque point de contact dans la réalisation d’un objectif. C’est un modèle dit bottom-up qui utilise l’historique de tous les visiteurs (points de contact et données CRM) et donne ainsi une attribution data-driven. L’algorithme va analyser les séquences, le nombre, la typologie des points de contacts…
L’analyse au dernier clic a tendance à valoriser les leviers payants au détriment des leviers branding qui interviennent plus tôt dans le parcours client. Dans un contexte où les leviers payants coûtent de plus en plus cher, il devient crucial de valoriser l’ensemble des points de contact et comprendre la contribution de chacun d’eux dans la vente. En commençant par des KPI plus justes et une meilleure compréhension des parcours clients, l’attribution data-driven se révèle un indicateur précieux pour de l’optimisation opérationnelle, à savoir comment allouer ses ressources.
De plus, l’industrialisation de ces algorithmes ouvre des perspectives sur des actions en temps réels comme par exemple:
-
Identifier les clients pour qui l’envoi d’un type de newsletter à un moment donné aura un fort impact sur leur probabilité de conversion.
-
Mettre à jour le ciblage des leviers payants pour augmenter ou arrêter la pression publicitaire.
-
Personnaliser le site en fonction du parcours client en amont.
Le défi de l’automatisation ne peut se faire sans une bonne compréhension de l’impact de chaque point de contact pour individualiser au plus juste les décisions marketing.
2. Les étapes dans la mise en place d’une stratégie d’attribution data-driven
A. Évaluer son degré de maturité sur la data
Pour que l’algorithme soit performant, il est important d’avoir de nombreuses données et de bonne qualité. Nous réalisons un audit pour comprendre la structure des données en évaluant par exemple:
-
La centralisation de la donnée: CRM, Data Management Plateform (DMP), partenaires médias (Adwords, Criteo, …), …
-
La granularité de la donnée à savoir le niveau de précision disponible. Par exemple, pour un point de contact SEA : Adwords > Campagne > Annonce > Mot-clé
-
La distribution des données pour s’assurer de la pertinence de la segmentation. Par exemple, mieux comprendre les mécanismes de conversion en étudiant la distribution du temps entre le premier point de contact et l’achat.
-
Le nombre moyen de points de contact avant achat
-
Les comportements non-acheteurs pour mieux cerner les mécanismes de conversion.
-
L’intégration des données avec les systèmes de pilotage (Bid Management System, Ad servers, Ad viewability measurement…).

B. Définir un objectif commun
L’enjeu est de réconcilier les visions au sein des différentes business-units pour casser les silos de données, c’est une mission de conduite du changement. L’idée est d’évaluer la performance globale plutôt que chaque point de contact de manière indépendante. Un autre bénéfice peut être dans l’évaluation des parcours clients. Par exemple, l’étude des séquences entre les différents points de contact va permettre d’identifier et/ou de valider les parcours les plus performants sur les phases d’acquisition, de conversion et de fidélisation.
C. Établir la feuille de route du Proof Of Concept jusqu’à son industrialisation
Nous travaillons du Proof of Concept à la mise en production d’algorithmes d’attribution data-driven. Notre méthodologie est de suivre une démarche itérative pour perfectionner le modèle en capitalisant sur l’expertise métier. Afin d’affiner l’analyse nous ajoutons des paramètres comme:
-
Segmentation client
-
Coût des campagnes
-
Devices: mobile, tablette et desktop
-
Critères géographiques (pays, villes) et de temporalité (matin, après-midi, soir)
-
Saisonnalité: opération commercial, lancement nouveau produit, …
-
Story-telling: s’assurer du bon message tout au long des points de contact
En support du développement du modèle algorithmique, nous accompagnons la conduite du changement:
-
Par une interface sur mesure à destination des métiers et opérationnels afin de faciliter l’accès à une information pertinente pour leurs cas d’usage.
-
Par l’automatisation de certaines actions marketing, par exemple le déclenchement d’un mail automatique aux visiteurs les plus appétants.
D. Mesurer le succès
En combinant 3 approches, nous pouvons évaluer la pertinence et le ROI des modèles data-driven:
L’A/B testing permet de valider en permanence la pertinence du modèle et mieux se rendre compte de son impact réel. Nous recommandons cette approche pour comparer les performances de plusieurs modèles (classiques vs. data-driven).
L’effet marginal, qui donne l’impact d’1€ investi en chiffre d’affaire, est utilisé pour simuler des prises de décisions sur les différents modèles. Ainsi, nous pouvons évaluer le ROI et donner des indicateurs précieux aux directions marketing pour ventiler au mieux leur budget média.
Le calcul de l’uplift nous permet aussi d’évaluer le modèle; il permet d’extraire la sensibilité d’un client à un levier en particulier. Ainsi, nous vérifions la contribution réelle de chaque point de contact.
3. Comment juger la performance d’un modèle d’attribution ?
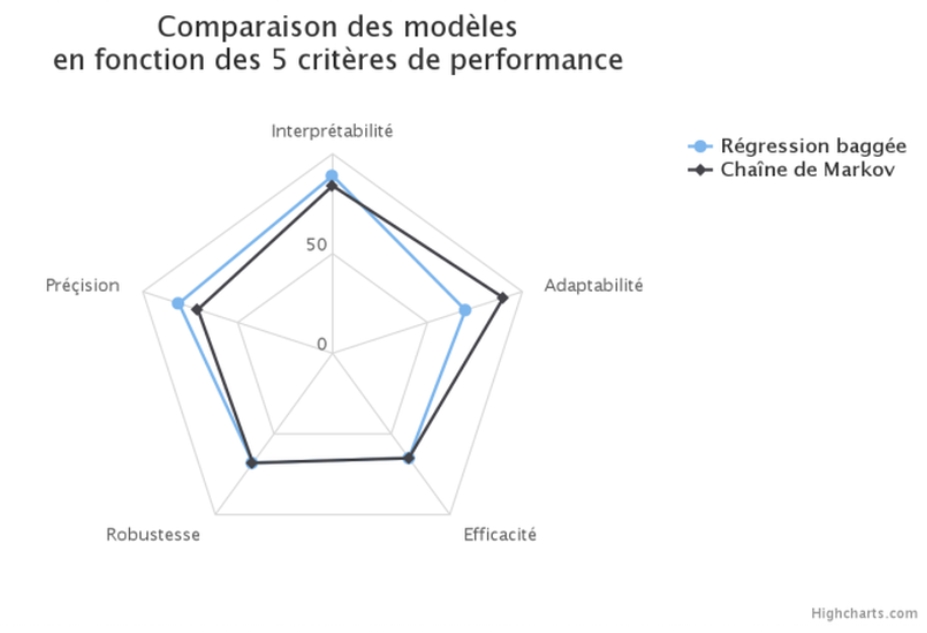
Nous retenons 5 axes qui permettent de déterminer la pertinence d’un modèle.
A. Précision de la prédiction : le but de cet axe est de déterminer si l’algorithme est juste et précis dans les prédictions qu’il donne. Autrement dit, est-ce que l’algorithme est pertinent dans l’attribution qu’il associe à chaque canal. Il existe ici de nombreuses métriques bien connues des data scientists, incluant par exemple l’aire sous la courbe ROC. En fonction des applications d’autres indicateurs comme les mesures de lift ou la courbe de precision-recall peuvent être utilisés.
B. Robustesse : Il est capital de construire un modèle qui soit stable dans le temps. Par principe, un modèle d’attribution n’est pas à usage unique et doit donc pouvoir encaisser les mouvements et transformations temporelles. Les métriques de robustesse peuvent être calculées en utilisant différentes photographies datées des données et en étudiant les variations de précision entre ces photographies. Un autre aspect de la robustesse est la reproductibilité du modèle, c’est-à-dire sa capacité a être réutilisé dans des contextes variés.

C. Interprétabilité : Ce point est essentiel pour un modèle d’attribution. En effet, le modèle est avant tout à destination des équipes marketing et opérationnelles et se doit donc d’être compréhensible et utilisable facilement. Un modèle trop “boite noire” freinera fortement la prise de décisions et finira par ne plus être utilisé. Au contraire, un modèle compris des décideurs sera une vraie aide et un véritable soutien à la décision marketing.
D. Adaptabilité : Les stratégies marketing évoluent rapidement dans le temps. Ainsi, les points de contacts utilisés sont amenés à évoluer, apparaître ou disparaître. Un outil d’attribution doit être capable de s’adapter à des nouveaux contextes et aux nouveaux objectifs (vente, inscription, trafic, …), ainsi qu’à toutes les formes de personnalisations possibles pour encourager l’innovation marketing.
E. Efficacité algorithmique : Elle représente la capacité du modèle à supporter une forte croissance du flux de données (scalabilité) en gardant une vitesse d’exécution satisfaisante. Notons qu’un modèle d’attribution peut être amené à être exécuté en temps réel.
La combinaison de ces différents critères permet de juger des performances d’un modèle d’attribution data-driven de manière efficace et transverse.
Par ailleurs, si la précision ou encore l’efficacité algorithmique sont des métriques bien connues dans tous les modèles de machine learning classiques, l’interprétabilité et la versatilité prennent une forte importance dans les modèles d’attribution. Ce nouveau paradigme nous pousse à proposer des modèles orientés et construits différemment de ceux éprouvés par la littérature scientifique classique.
4. Deux différentes approches dans la construction d’un modèle d’attribution data-driven
“Quelle est la prochaine action qui maximisera la chance de conversion de mon client ?”. Les techniques présentées ci-dessous nous permettent de répondre en temps réel et pour chaque client à cette question. Une approche par la data science des modèles d’attribution nous permet non seulement d’obtenir des modèles précis, mais également des modèles interprétables et compréhensibles par les équipes métiers et opérationnelles.

A. Bagged Logistic Regression
De nombreux modèles de classification ont été développés dans la littérature machine learning ces dernières années. Parmi eux les réseaux de neurones, les forêts aléatoires ou les machines à support de vecteurs ont tous empiriquement montré de très bonnes performances en précision dans de nombreux domaines d’applications différents. Cependant, ces modèles sont qualifiés de “boite noire” parce qu’ils sont difficile à interpréter.
D’autre part, les résultats d’un modèle basique comme la régression logistique sont facilement interprétables mais les performances de précision ont été plusieurs fois démontrées comme bien inférieures à d’autres algorithmes plus complexes.
Ainsi, nous cherchons à construire un modèle à la fois performant en terme de précision de prédiction mais également facilement interprétable et souple. Cette combinaison de paramètres, essentielle pour les modèles d’attribution, ne se retrouve pas dans les algorithmes sus-cités.
L’idée de la régression logistique baggée[3] est de combiner les performances de précision du bagging (à la base des forêts aléatoires) avec les qualités d’interprétabilité et de stabilité de la régression logistique. Le bagging consiste à répéter un modèle simple plusieurs fois sur des sous-ensembles aléatoire de la population et des variables afin d’agréger les résultats pour améliorer la robustesse et la précision. En “baggant” des régressions logistiques, nous gagnons en interprétabilité et en stabilité par rapport à un bagging d’arbres de décision, tout en gardant des performances en précision plutôt bonnes inhérentes à cette technique.
Techniquement, la régression logistique “baggée” peut se résumer en 2 étapes :
-
Étape 1 : Sur le jeu de données, sélectionner aléatoirement un échantillon des observations avec une probabilité Ps puis un sous-ensemble des variables avec une probabilité Pc. Lancer une régression logistique simple sur l’échantillon de la population en utilisant que les variables sélectionnées dans le sous-ensemble. Sauvegarder les coefficients issus de la régression logistique.
-
Étape 2 : Répéter la première étape M fois. Les coefficients finaux pour chaque variable seront calculés en prenant la moyenne des estimations des coefficients sur chacune des itérations où la variable a été aléatoirement sélectionnée.
Les coefficients obtenus en sortie de cet algorithme vont permettre de déterminer l’importance de chacun des canaux dans la décision de conversion. Des tests statistiques permettent de juger de la significativité d’un coefficient dans ce type de modèle.
Le gain en interprétabilité est donc très fort par rapport à un modèle boîte noire et les performances sont quasiment équivalentes. Par ailleurs, chaque itération étant indépendante des autres, le modèle peut en lancer plusieurs en parallèle pour gagner en vitesse d’exécution. Enfin il est possible d’intégrer la valeur client dans le modèle pour valoriser la précision sur les clients à plus fort potentiel. Dans ce cas là nous expliquons non seulement les points de contact qui entraînent la conversion mais également ceux qui maximisent sa valeur.
B. Modélisation par chaîne de Markov[4]

Dans le cas d’un modèle d’attribution, chaque état correspond à un point de contact et la matrice de transition correspond donc aux probabilités de passage d’un point de contact à un autre. Dans une modélisation simple, la liste des états S correspond à la liste des points de contact disponibles. Cependant, il serait pertinent de pouvoir prendre en compte une information plus complexe dans notre modélisation. Par exemple, l’ordre d’apparition du point de contact dans le parcours du visiteur semble pertinent pour un bon modèle d’attribution. Ainsi, il existe plusieurs manières de définir le nombre d’états dans un modèle par chaîne de Markov:
-
La méthode ‘forward’ consiste à définir comme état toute combinaison point de contact/positionnement. Par exemple, pour 2 visiteurs aux parcours respectifs {Start – Réseaux Sociaux – Emailing – Conversion} et {Start – Emailing – Réseaux Sociaux – Conversion}, l’ensemble des valeurs possibles serait : {Start – Réseaux Sociaux 1 – Réseaux Sociaux 2 – Emailing 1 – Emailing 2 – Conversion} (1 et 2 représentant les ordres d’apparition de chacun des canaux).
-
La méthode ‘bathtub’ définit comme état toutes les combinaisons entre points de contact et trois positionnements clés : premier, intermédiaire et dernier. la position intermédiaire rassemble toutes les positions autres que la première ou la dernière. Par exemple, pour un parcours {Start – Emailing – Réseaux Sociaux – Affiliation – Emailing – Conversion}, on obtient l’ensemble des états {Start – Emailing First – Emailing Last – Réseaux Sociaux intermediate – Affiliation intermediate – Conversion}

Dans la modélisation sus-citée, la probabilité d’un point de contact ne dépend que du précédent, ce qui est en pratique une hypothèse bien trop forte. En effet, on aimerait pouvoir garder un historique plus profond pour chaque visiteur. L’ordre d’une chaîne de Markov définit la profondeur de l’historique utilisée pour calculer les probabilités de transition. Le nombre de paramètres indépendants d’un modèle par chaîne de Markov augmente de manière exponentielle avec l’ordre. Il convient donc de garder un ordre raisonnable pour ne pas perdre l’efficacité algorithmique comme qualité de notre modèle. Augmenter l’ordre complexifie le modèle et le rend plus précis. A l’inverse, un modèle d’ordre 1 est très intuitif et compréhensible. La construction d’un bon modèle consiste à trouver un compromis équilibré entre complexité et précision des résultats.
Une fois le modèle construit, nous pouvons calculer différents indicateurs qui nous permettront de juger des points de contact les plus importants. Par exemple, le modèle peut, étant donner le parcours effectué d’un visiteur, donner sa probabilité de conversion. Ainsi, pour chaque visiteur, le modèle peut prioriser ceux ayant une forte probabilité de conversion.
Une autre métrique est celle du Removal Effect. Il s’agit de calculer le changement dans la probabilité de conversion si l’on enlève un point de contact. Si ce changement est fort, cela signifie que le point de contact est capital dans la conversion des visiteurs.
Ce modèle pose également un cadre pour le calcul de nombreux autres indicateurs. On pensera notamment à l’identification des meilleurs parcours de conversion ou, étant donné le parcours d’un visiteur, déterminer le prochain point de contact quimaximisera ses chances de conversion.
C. Autres approches possibles
Les 2 modèles proposés plus haut ne sont que 2 exemples des nombreuses approches possibles pour construire un modèle d’attribution data-driven. Nous penserons notamment à une approche dite par ‘survival analysis’[5]. Derrière cette dénomination se trouve un modèle qui conceptualise la conversion comme un phénomène de durée et qui cherche à déterminer quels sont les points de contact qui vont raccourcir le parcours client jusqu’à sa conversion.
 Une dernière approche, plus originale, utilise les séries temporelles multivariées[6]. L’idée est d’utiliser les modélisations temporelles de plusieurs indicateurs agrégés comme le nombre de vues ou le nombre de clics sur les différents canaux marketings. Le but est d’étudier les interactions entre certains points de contact et le taux de conversion. L’avantage de cette méthode est d’utiliser des données agrégées et donc plus facilement disponibles. Cependant, le modèle se base uniquement sur des indicateurs agrégés et non sur les parcours uniques de chaque visiteur.
Une dernière approche, plus originale, utilise les séries temporelles multivariées[6]. L’idée est d’utiliser les modélisations temporelles de plusieurs indicateurs agrégés comme le nombre de vues ou le nombre de clics sur les différents canaux marketings. Le but est d’étudier les interactions entre certains points de contact et le taux de conversion. L’avantage de cette méthode est d’utiliser des données agrégées et donc plus facilement disponibles. Cependant, le modèle se base uniquement sur des indicateurs agrégés et non sur les parcours uniques de chaque visiteur.
CONCLUSION
L’attribution marketing data-driven est un enjeu qui va devenir de plus en plus fort avec à la fois la nécessité de valoriser les leviers branding, sous-estimés par les modèles d’attribution classiques, et l’optimisation des parcours clients. Alors que seulement 14% des marketers considèrent le modèle dernier clic comme pertinent[7], le moment est opportun pour passer à l’attribution data-driven.
La data est un fabuleux vecteur pour imaginer de nouvelles expériences, et ceux qui la maîtrisent, seront les grand gagnants de la révolution en marche. Quantmetry accompagne ses clients dans la montée en puissance sur les stratégies de données.
[1] IBM Global Survey of Marketers – The State of Marketing (2013)
[2] Criteo – Marketing attribution comes of age (2013)
http://www.criteo.com/media/1024/en-criteo-white-paper-marketing-attribution-comes-of-age.pdf
[3] Xuhui Shao, Lexin Li – Data-driven Multi-touch Attribution Models (2011) http://www0.cs.ucl.ac.uk/staff/w.zhang/rtb-papers/data-conv-att.pdf
[4] Eva Anderl, Ingo Becker, Florian v. Wangenheim, Jan H. Schumann – Mapping the customer journey: A graph-based framework for online attribution modeling (2014) http://bit.ly/28Q8ZPD
[5] John Winston Chandler-Pepelnjak – Modeling Conversions in Online Advertising (2010)
http://scholarworks.umt.edu/cgi/viewcontent.cgi?article=1689&context=etd
[6] Pavel Kireyev, Koen Pauwels, Sunil Gupta – Do Display Ads Influence Search? Attribution and Dynamics in Online Advertising (2013) https://storage.googleapis.com/gasandbox1/HBR_Do-Display-Ads-Influence-Search-Attribution-and-Dynamics-in-Online-Advertising_13-070.pdf
[7] eConsultancy – Marketing Attribution: Valuing the Customer Journey (2012)
https://www.thinkwithgoogle.com/research-studies/marketing-attribution-valuing-the-customer-journey.html
