

Comment l'IA apprend à lire? Introduction au traitement automatique du langage

✍ Hugo Perrier / Temps de lecture : 8 minutes.
Introduction
Le traitement du langage naturel, souvent désigné par l’acronyme anglais NLP (Natural Language Processing) est une branche de l’intelligence artificielle qui a pour but de comprendre le langage humain. Le NLP connaît actuellement un essor fulgurant et de nombreuses applications industrielles ont vu le jour ces dernières années :
- La classification des emails dans une boîte de réception (Package open-Source de traitement des emails MELUSINE)
- La détection de thèmes récurrents dans un corpus (Analyse du Grand Débat National avec TALAGRAND)
- La traduction de texte
- La création de chatbots
Cet article a pour but de présenter en termes simples un concept fondamental du NLP : la représentation des mots (en informatique). Les concepts décrits dans cette article permettent de répondre à la problématique suivante :
La sémantique en informatique : comment comparer le sens des mots ?
Cette problématique peut être illustrée par une question simple :
Le mot « chat » est-il plus proche du mot « char » ou du mot « félin » ?
Intuitivement un humain répondrait sûrement « félin » à cette question…
mais quid d’un ordinateur ?

Source d’image : https://www.suck.uk.com
Exemple d’application de la représentation des mots
Quantmetry a contribué au développement du package open-source Melusine dédié au traitement automatique des emails en français. L’utilisation principale de Melusine est le routage des emails reçus par une entreprise vers les entités compétentes pour le traiter. Un email de résiliation peut ainsi être affecté à l’entité en charge des résiliations.
L’assignation d’une catégorie (une entité) à une donnée d’entrée (un email) est appelé un problème de classification. Lors de la classification, on peut imaginer que les emails qui traitent d’automobile doivent être envoyés vers une entité particulière. Il est alors pertinent de pouvoir détecter des modèles de voiture (Twingo, Ka, Panda, Multiplat) ou le vocabulaire automobile (pare-brise, volant) pour optimiser le routage. Demander à un humain de lister tous les mots du champs lexical de la voiture est une tâche chronophage et ennuyante alors qu’un ordinateur capable de comprendre automatiquement les relations entre les mots pourrait réaliser cette tâche en une fraction de seconde!
Une bonne représentation des mots (en informatique) est donc un élément déterminant pour réaliser de nombreuses taches, à l’instar du routage des emails.
Les différentes méthodes de représentation des mots
Représentation des mots par des chaînes de caractère
La représentation par défaut d’un texte en informatique est une chaîne de caractères. Le mot « chat » est donc une combinaison des caractères :
chat = c + h + a + t
Métrique de comparaison des mots
Si on représente un mot comme une chaîne de caractères (un string), la similarité entre deux mots peut être définie comme le nombre de transformations nécessaires pour passer d’un mot à l’autre (distance de Levenshtein). Les mots « chat » et « char » ne diffèrent que d’une lettre et ils sont donc très similaires.
Résultat
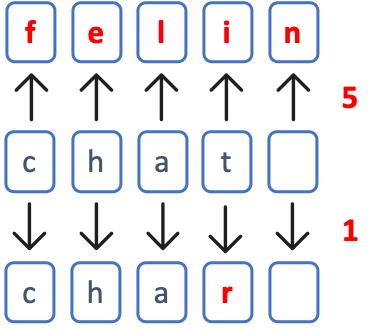
Les distances de Levenshtein entre les mots sont les suivantes :
- Distance chat/char : 1
- Distance chat/félin : 5
Même si la représentation des mots en chaîne de caractère a l’avantage de s’appuyer sur la représentation « native » du texte en langage informatique, on s’aperçoit que le résultat obtenu n’est pas conforme à l’intuition humaine (chat est plus proche de félin que de char). Cette représentation des mots ne permet pas de prendre en compte le sens des mots (la sémantique).
Représentation des mots par des vecteurs (aussi appelés embeddings de mots)
Représentation des mots
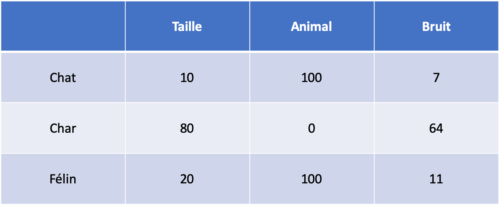
On peut représenter un mot comme un vecteur où chaque composante décrit une caractéristique du mot. Choisissons par exemple de représenter les mots en utilisant une échelle allant de 0 à 100 et selon les trois critères :
- taille : Élevé si le mot évoque une grande taille
- animal : Élevé si le mot évoque un animal
- bruit : Élevé si le mot évoque quelque chose de bruyant
On obtient alors les vecteurs suivants :
Métrique de comparaison des mots
Pour comparer la représentation vectorielle du mot « chat » (10, 100, 7) avec la représentation vectorielle du mot « char » (80, 0, 64), on utilise une métrique de similarité entre vecteurs ou une métrique de distance entre vecteurs (une similarité est l’inverse d’une distance). On peut par exemple utiliser la distance euclidienne définie par :
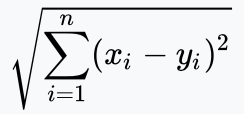
Résultat
On obtient les distance euclidiennes suivantes :
- Distance chat/char : 135
- Distance chat/félin : 11
Avec cette représentation, le mot « chat » est beaucoup plus proche (distance faible) du mot « félin » que du mot « char ». Cette méthode de comparaison permet d’obtenir un résultat beaucoup plus conforme à l’intuition humaine mais souffre de limitations majeures :
- Le résultat est fortement dépendant du choix de catégories (taille, bruit, etc).
Quelle résultat si on choisit d’utiliser les critères durée, confort et végétal ? - Cette méthode nécessite qu’un humain évalue tous les mots selon les catégories prédéfinies. Étant donné que la langue française comporte environ 30000 mots, cette tâche semble impossible.
La génération non-supervisée de vecteurs de mots
Afin de parer aux limitations évoquées ci-dessus, l’utilisation « d’embeddings de mots » (word embeddings en anglais) générés par des méthodes statistiques est très répandue en NLP. Les mots sont toujours représentés par des vecteurs de caractéristiques, cependant, le choix des critères d’évaluation et l’évaluation de tous les mots du vocabulaire selon ces critères sont automatisés. La création des embeddings de mots ne nécessite donc pas d’action humaine (telle qu’évaluer des mots selon des critères prédéfinis), on parle de méthode d’apprentissage non-supervisée. Cependant, il est nécessaire de disposer d’un large corpus de documents pour que les méthodes statistiques utilisées soient pertinentes.
Deux méthodes de génération d’embeddings de mots automatisés sont présentées dans cet article :
- La représentation par une matrice Document-Terme (DocTerm)
- La méthode Word2Vec
Génération des embeddings de mots en utilisant la matrice DocTerm
Représentation des mots
Pour générer une matrice Document-Terme (ou DocTerm), on va simplement compter la fréquence d’apparition des mots dans les différents documents d’un corpus (i.e un ensemble de documents).
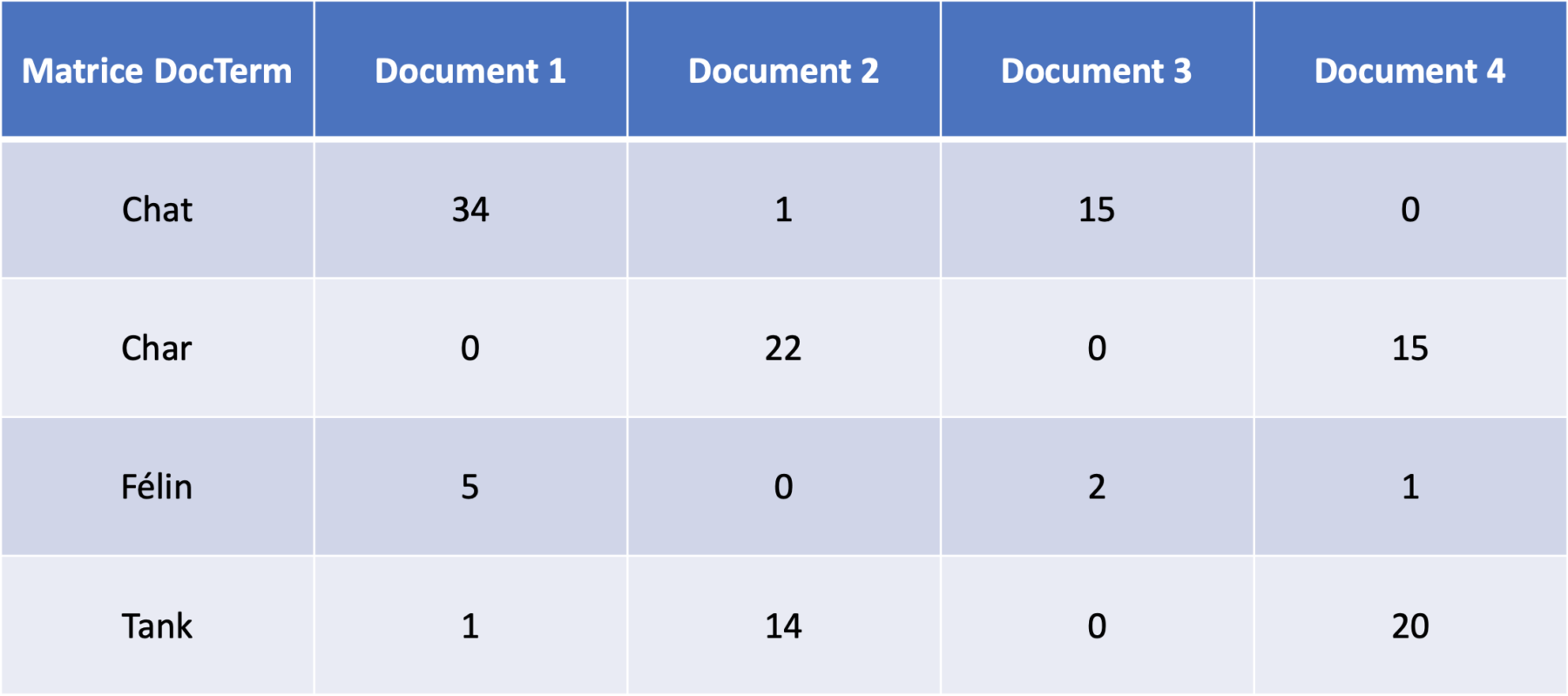
Dans l’exemple ci-dessus, le mot chat apparaît ainsi 34 fois dans le document 1 mais il n’apparaît pas dans le document 4. Les documents du corpus remplacent ainsi les catégories (taille, animal et bruit) utilisées dans la section précédente.
Métrique de comparaison des mots
Comme précédemment, on peut utiliser une métrique de similarité entre vecteurs pour comparer la représentation vectorielle du mot « chat » (34, 1, 15, 0) avec la représentation vectorielle du mot « char » (0, 22, 0, 15). La métrique fréquemment utilisée pour comparer des embeddings de mots est la similarité cosinus :
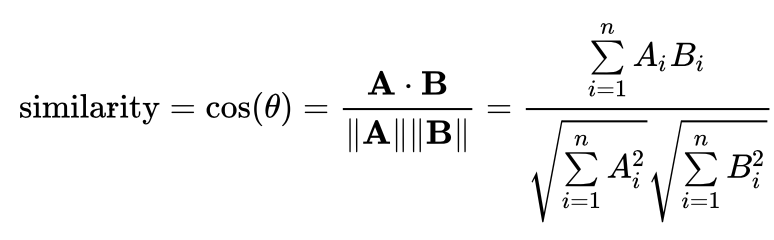
Résultat
On obtient les similarités cosinus suivantes (similarité élevée = mots proches) :
- Similarité chat/char : 0,02
- Similarité chat/félin : 0,98
- Similarité chat/tank : 0,05
- Similarité char/tank : 0,93
Avec cette métrique, les paires de mots présents dans les mêmes documents, telles que la paire (chat, félin) ou la paire (char, tank), apparaissent comme similaires.
Avantages de la méthode DocTerm
- Résultat conforme à l’intuition humaine
- Explicabilité du score de similarité (on sait que deux mots sont proches car ils apparaissent dans les mêmes documents)
- Pas de travail humain nécessaire
Limitations de la méthode DocTerm
- Dimension de la matrice DocTerm. Pour un corpus de 20 000 documents contenant 10 000 mots uniques, la matrice DocTerm sera de taille 20000×10000.
Cette dimensionnalité pose problème car la puissance de calcul requise est très élevé. - Performances généralement inférieures aux méthodes Word2Vec (voir paragraphe suivant).
Génération d’embeddings de mots en utilisant une méthode Word2Vec
Description
Comme la méthode DocTerm, la méthode Word2Vec permet de générer automatiquement une représentation vectorielle des mots en se basant sur un corpus de documents. Le corpus de phrases ci-dessous est utilisé comme exemple pour décrire la génération d’embedding avec une méthode de type Word2Vec.
Le chat attrape la souris
Le félin chasse la souris
Le chat aime le lait
Le félin boit du lait
Le char dispose d’un canon
Le tank possède un canon
On constate que le mot « chat » et le mot « félin » apparaissent tous les deux dans le voisinage des mots « lait » et « souris » alors que les mots « tank » et « char » apparaissent dans le voisinage du mot « canon ».
Les méthodes de type Word2Vec utilisent ainsi la notion de voisinage pour générer une représentation vectorielle des mots. Le détail de l’entraînement d’un modèle de type Word2Vec dépasse le périmètre de cet article mais on peut tout de même retenir que l’entraînement fait appel à un type d’algorithme d’intelligence artificielle appelé réseaux de neurones artificiels.
Représentation des mots
Comme pour la méthode DocTerm, les mots sont représentés par des vecteurs mais avec la méthode Word2Vec, la dimension du vecteur peut être contrôlée (le nombre de dimensions est un paramètre lors de l’entraînement d’un embedding Word2Vec).
Pour ceux qui se souviennent des cours de maths au lycée, les vecteurs peuvent être représentés par des flèches et on peut réaliser des opérations sur les vecteurs (vecteur A + vecteur B – vecteur C) en suivant simplement ces flèches. Ces opérations vectorielles fonctionnent également lorsque les vecteurs représentent des mots! Cette propriété permet de visualiser les notions abstraites « apprises » lors de l’entrainement d’un embedding, par exemple on peut illustrer la notion de capitale :
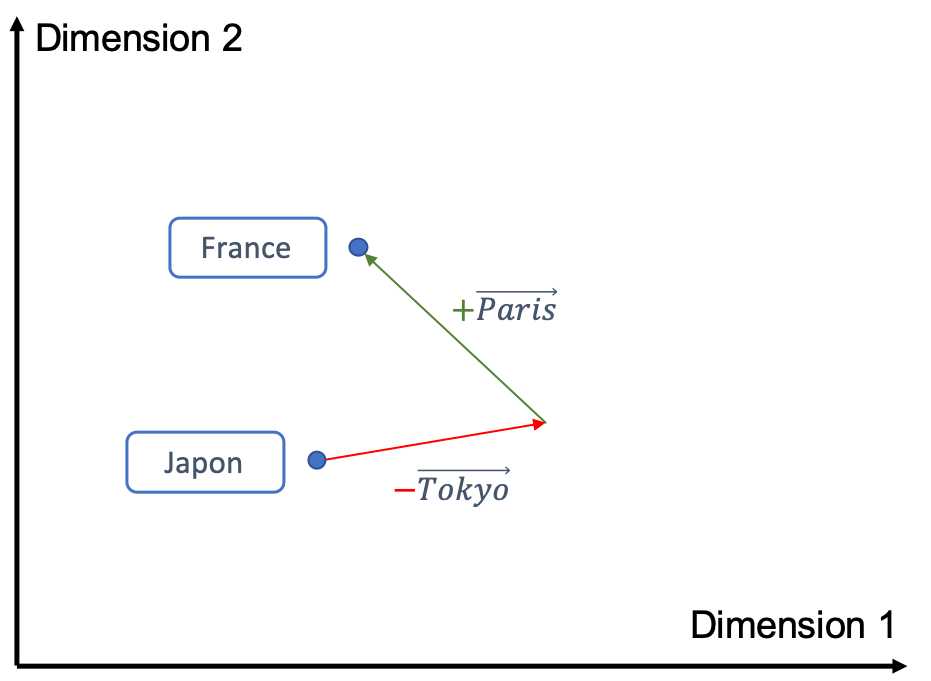
En partant du vecteur Japon puis en soustrayant le vecteur Tokyo et en ajoutant le vecteur Paris, on obtient le vecteur France! Cette opération est équivalente à l’analogie :
Tokyo est au Japon ce que Paris est à la France
ou encore :
Japon – Tokyo + Paris = France
Avantages de la méthode Word2Vec
La méthode Word2Vec est généralement plus capable « d’apprendre » des notions abstraites (capitale, masculin/féminin, lien de parenté) que la méthode DocTerm et les performances sur différentes applications de NLP sont souvent supérieures.
Pour aller plus loin
La représentation des mots est à la base du traitement du langage naturel. Cet article présente quelques notions de base telles que la représentation des mots par des vecteurs mais il existe de nombreuses autres techniques utilisées en NLP pour extraire des notions sémantiques à partir de données textuelles. Les paragraphes ci-dessous présentent brièvement quelque-unes de ces techniques pour satisfaire les lecteurs intéressés.
Représentation d’un mot dans son contexte
Les méthodes présentées jusqu’à maintenant se basent sur des représentations vectorielles des mots qui sont indépendantes du contexte dans lequel le mot est utilisé :
La représentation vectorielle du mot « nouvelle » dans l’expression « Nouvelle Zélande » est la même que dans l’expression « Bonne Nouvelle »
Comment prendre en compte le contexte dans lequel un mot est utilisé? Deux méthodes de prise en compte du contexte, sont présentées ci-dessous :
- L’utilisation d’un « Phraser »
- Les modèles de langage
Phraser
Le principe du Phraser est extrêmement simple! On transforme une expression composée de plusieurs mots en un mot unique.
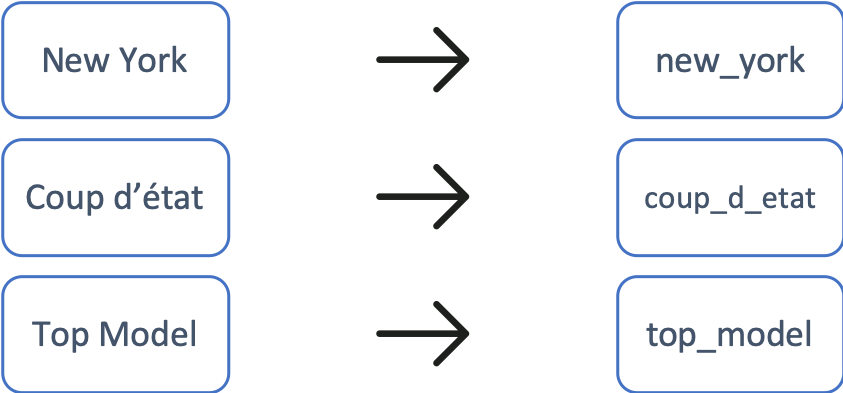
L’expression est transformée en un seul mot pouvant être représenté par un unique vecteur. Les représentations vectorielles des mots «bonne_nouvelle» et «nouvelle_zelande» sont donc différentes et le contexte dans lequel le mot « nouvelle » apparait est ainsi pris en compte.
Les modèles de langage
Les modèles de langages utilisent des techniques d’intelligence artificielle avancées (réseaux de neurones artificiels récurrents, mécanismes d’attention, etc) pour générer une représentation contextualisée des mots dans une phrase. Avec ces modèles, il n’existe plus de représentation vectorielle d’un mot et on ne peut donc pas comparer directement les mots « chat » et « char » ni réaliser des opérations arithmétiques telles que :
Roi – Homme + Femme = Reine
En revanche, les modèles de langage sont adaptés pour des applications NLP avancées telles que :
- le Question Answering : Rechercher dans un texte la réponse à une question
- la traduction de texte
- la génération de résumé automatique
Pour pouvoir utiliser un modèle de langage, une phase d’entraînement du modèle est nécessaire. Cette phase est généralement gourmande en temps et en puissance de calcul, et nécessite un large corpus de texte pour atteindre des performances satisfaisantes. Le lecteur intéressé peut se référer à l’article: BERT de Google AI sur le banc de test !
Conclusion
Cet article présente un concept fondamental pour le traitement automatique du texte : la représentation des mots. On montre que sans une représentation des mots intelligente, un ordinateur est incapable de trouver une similarité entre les mots « mère » et « maman » alors que cette tâche est triviale pour un humain de 3 ans.
Différentes méthodes de représentation des mots sont évoquées dans cette article et on constate que grâce aux méthodes de type Word2Vec, si un large corpus de documents est disponible, un ordinateur peut apprendre des notions abstraites telles que la notion de capitale ou la notion de lien de parenté (ex: la nièce est à la fille ce que le neveu est au fils).
La représentation des mots est un prérequis pour de nombreuses applications NLP (par exemple la classification de texte) mais on peut aussi utiliser directement la représentation vectorielle des mots pour visualiser dans un corpus de documents les groupes de mots similaires.
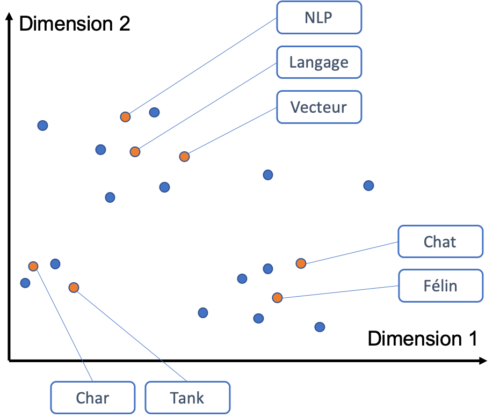
A vous de jouer : Utilisez un ordinateur pour calculer la similarité entre « chat » et « avion » !

Source d’image : https://www.suck.uk.com
