

Domaine de validité – quels sont les indicateurs d’une IA de confiance ?

Cet article a été rédigé par Nicolas Girard, Philippe Neveux et Grégoire Martinon.
Dans de nombreux projets d’IA, les utilisateurs métiers ont besoin de prédictions fiables. Autrement, ils risquent de prendre des décisions aveugles ou de cesser d’utiliser le modèle en raison d’un manque de compréhension de son fonctionnement ainsi que de ses résultats. Par ailleurs, l’impressionnante capacité des algorithmes d’IA à prédire avec précision repose sur une phase d’apprentissage dans laquelle une grande quantité de données est utilisée. De fait, en l’absence de contrôles relatifs à la validité des données utilisées, cet atout peut soudainement devenir son talon d’Achille. Par conséquent, une IA digne de confiance devrait s’appuyer sur des algorithmes qui sont non seulement capables de fournir des prédictions précises, mais aussi explicables et fiables.
Dans cet article, nous présentons la notion de domaine de validité, qui regroupe une série de contrôles élémentaires et d’indicateurs de précaution pouvant guider la prise de décision d’un opérateur humain.
Comment définir le domaine de validité de l’IA ?
Tout cycle de vie d’un modèle de machine learning (ML) peut être résumé comme suit :
- Apprendre des tendances sur un jeu d’entraînement
- Mettre le modèle en production
- Prédire sur de nouvelles données
- Prendre une décision
- Attendre d’obtenir les labels véritables pour calculer les performances et enrichir le jeu d’entraînement
- Répéter tout depuis le début
Alors, où intervient le domaine de validité ?
Tout d’abord, à l’étape 3, il y a une question évidente :
« Comment s’assurer que les données d’entrée en production sont valides ? »
Autrement dit : comment s’assurer que l’hypothèse fondatrice i.i.d. (points de données indépendants et identiquement distribués) est vraiment satisfaite ?
Et puis à l’étape 4 :
« Comment faire confiance à la prédiction ? »
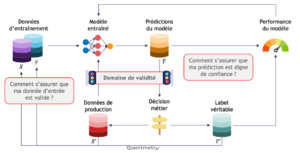
Figure 1 : Le domaine de validité dans le cycle de vie d’une IA. Deux questions se posent naturellement : « Comment s’assurer que les données d’entrée en production sont valides ? » et « Comment faire confiance à la prédiction ? ».
Le domaine de validité peut être abordé à travers trois concepts principaux :
- Auditabilité : décrire littéralement les données d’entraînement et les prédictions, comprendre et s’assurer de la reproductibilité de toutes les expériences, modèles entraînés et des prédictions obtenues.
- Validation métier : définir des critères d’acceptation métier pour les points de données et les prédictions des modèles.
- Validation technique : fournir des scores d’anomalie pour les points de données et des garanties mathématiques sur la précision de la prédiction.
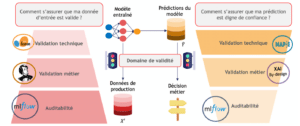
Figure 2 : Principaux concepts du domaine de validité. Chacune des deux questions peut être abordée avec trois niveaux de réponse : auditabilité, validation métier et validation technique. Plusieurs logos illustrent les outils soutenant les réponses.
Dans la suite de cet article, nous détaillons les 3 briques permettant de répondre aux 2 questions de la figure 2. Pour cela nous nous sommes appuyés sur certains outils open-source :
- MLflow pour la reproductibilité et l’auditabilité
- Great Expectations pour la validation des données métier
- Scikit-learn pour la détection d’anomalie
- MAPIE pour la quantification de l’incertitudes
En exploitant ces outils, nous avons pu produire des indicateurs graphiques qui sont finalement rassemblés dans un dashboard dit d’aide à la décision. Toutes les figures présentées par la suite sont issues de ce dashboard.
Étape 1 – Auditabilité
Vous êtes-vous déjà demandé d’où provenaient les données collectées ? Avez-vous clairement documenté le processus d’échantillonnage des données ou encore, le type de modèle utilisé ? Sinon, comment pouvez-vous convaincre une personne extérieure au projet de croire profondément en votre méthodologie ? Comment pouvez-vous l’encourager à réutiliser votre processus ou la mettre en garde contre une utilisation hors du champ d’application ? La documentation est le premier pas vers le domaine de validité.
Répondre à une telle batterie de questions sur les données et les caractéristiques du modèle garantit que toute personne qui a contribué au projet d’une manière ou d’une autre peut comprendre correctement quelles sont les données utilisées, comment le modèle a été entraîné et validé, quelles mesures sont utilisées pour évaluer les performances des modèles, etc. Un élément clé d’une IA digne de confiance est la transparence. Précisément, la documentation permet d’être totalement transparent sur le processus de modélisation et de faciliter l’audit [1, 2].
Avez-vous déjà douté de pouvoir retrouver un ancien résultat de test ? La mise en place de la documentation et le suivi des expériences garantissent que vos résultats peuvent être facilement reproduits à tout moment, quel que soit l’environnement de développement utilisé. Le prétraitement et le nettoyage des données, l’entraînement, les prédictions, les mesures de performance ne devraient pas être des expériences magiques qui ne peuvent être systématiquement reproduites. Dans cette optique, nous pouvons suivre chaque traitement, jeu de données d’apprentissage, hyperparamètres avec certains outils de versioning comme MLFlow.
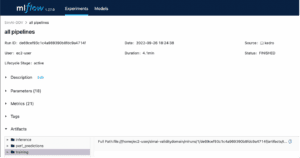
Figure 3 : Illustration de l’interface utilisateur MLflow. L’outil peut permettre la gestion des versions, la traçabilité et la reproductibilité de chaque expérience alimentant une conception de modèle, permettant aux auditeurs externes d’évaluer la validité de manière asynchrone.
Étape 2 – Validation métier
Validation de l’entrée
L’entraînement d’un algorithme d’IA nécessite de grandes quantités de données pour apprendre des tendances cachées. Mais finalement, comment peut-on s’assurer que les données d’entrée sont valides d’un point de vue métier ?
Pour répondre à cette question, nous pouvons utiliser Great Expectations, une bibliothèque open-source dédiée à la validation des données. Son fonctionnement est relativement simple, nous définissons un ensemble de règles attendues en matière de qualité des données – principalement basées sur les besoins de l’entreprise – et nous les enregistrons dans un document de synthèse clair. Il existe deux types d’attentes :
- Des attentes au niveau de la table, axées sur la structure globale du jeu de données (ordre des colonnes, nom des colonnes etc.)
- Des attentes sur des colonnes spécifiques
Ces attentes ouvrent la voie à ce que l’on appelle un « domaine de définition » du modèle. Par exemple, pour chaque caractéristique catégorielle, nous pouvons définir un ensemble de valeurs acceptables et un seuil de tolérance pour les valeurs manquantes. Ainsi, plus vous interagissez avec des personnes ayant des connaissances métiers, mieux vous répondrez aux attentes en matière de données. La figure 4, illustre trois règles élémentaires imposées à une caractéristique catégorielle.
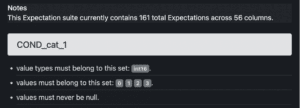
Figure 4: Document Great expectations récapitulatif des règles métiers attendues. Nous illustrons ici les règles attendues pour une catégorie donnée.
Au moment de la prédiction, il est fortement recommandé de valider les données de production avec les règles d’attente de qualité que vous venez de définir. Pour ce faire, nous pouvons simplement appliquer les règles attendues aux nouvelles données. La bibliothèque Great Expectations fournit un document de synthèse avec une liste des règles respectées et non respectées. Ainsi, nous pouvons observer spécifiquement dans quelle mesure les données utilisées pour la prédiction diffèrent de celles de l’entraînement, encore une fois d’un point de vue purement métier. Le traitement des instances qui enfreignent les règles dépend de votre interaction avec les utilisateurs finaux des prédictions. Par exemple, en raison de la nature du cas d’utilisation en question, vous pouvez traiter les points de données rebelles différemment et ainsi les conserver, les modifier ou les supprimer.
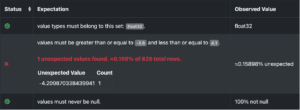
Figure 5 : Illustration de la validation par GreatExpectations des données d’entrée. La règle métier est claire sur les limites attendues pour les valeurs numériques, et il s’avère que dans cet exemple, un point de données est en dehors du domaine de définition. Il doit donc être considéré avec suspicion par les experts métiers.
Explicabilité des prédictions
Pourquoi le modèle prédit-il cette sortie ? C’est une question naturelle que vous pourriez vous poser au moment de prendre la décision. Ci-après, nous considérons les prédicteurs linéaires, qui peuvent fournir des explications à la fois globales et locales tout au long du cycle de vie.
D’une part, au moment de l’entraînement, une plus grande transparence sur l’importance des caractéristiques – le poids de chaque coefficient – pourrait guider la prise de décision de l’opérateur. Avec de la connaissance métier, l’importance des caractéristiques inhabituelles pourrait alerter quant au fonctionnement interne du modèle.
D’autre part, au moment de la prédiction, nous pouvons observer localement chaque contribution d’une caractéristique en multipliant simplement le poids de son coefficient par la valeur prise par la donnée pour cette caractéristique [3].
Avec de la connaissance métier, une combinaison impossible de contributions peut être identifiée et corrigée dans le modèle ou dans les données. Dans le graphique ci-dessous, nous sélectionnons un point de données et analysons la contribution de chaque caractéristique par rapport à celle de tous les autres points de données testés. Cela permet de visualiser facilement les contributions anormales pour un point de données donné.
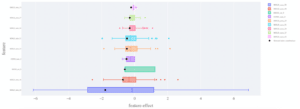
Figure 6 : Graphique de contribution locale. La contribution des caractéristiques d’un point de données sélectionné est représentée par des points noirs, tandis que la contribution des caractéristiques pour l’ensemble du jeu de test est affichée sous forme de diagrammes en boîte à moustaches.
Étape 3 – Validation technique
Détection d’anomalie
Parieriez-vous sur une prédiction basée sur des données incorrectes ou simplement obsolètes ? Vous savez sûrement que la donnée peut être imparfaite à la fois en termes de qualité et de quantité. Ainsi, vous devez être prudent même si l’impact de données de mauvaise qualité peut ne pas être immédiatement perceptible. Une approbation technique des données devrait garantir que les observations ne sont pas trop éloignées des observations historiques. Par exemple, l’altération des données peut aussi bien être le résultat de capteurs endommagés que d’un biais introduit par l’humain dans les données d’entrée.
Dans le domaine de validité, la détection des anomalies joue un rôle central. Il faut peu de mises en œuvre techniques, mais quelques connaissances métiers pour identifier la proportion de valeurs aberrantes dans l’ensemble d’entraînement afin d’ajuster seuil de détection. En appliquant ce modèle aux données utilisées, vous disposerez d’indicateurs techniques sur la distance entre l’observation et l’ensemble d’apprentissage.
Dans le graphique ci-dessous, tous les points de données à gauche de la ligne noire verticale sont considérés comme des anomalies, selon le seuil défini par l’entreprise. Le point de données sélectionné présente un score d’anomalie en rouge assez éloigné de cette frontière. En outre, nous constatons que 1,4% de l’ensemble des données de test sont signalées comme des valeurs aberrantes. Il faut garder à l’esprit que tous les cas d’utilisation ne permettent pas la même tolérance sur les valeurs aberrantes. Avec l’aide des métiers, ce nombre de valeurs aberrantes peut être ajusté de manière itérative.
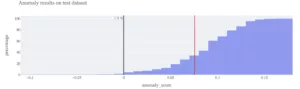
Figure 7 : Score d’anomalie d’un point du jeu de test sélectionné en rouge par rapport à la distribution du score d’anomalie sur l’ensemble des données de test. Les scores sont fournis par une forêt d’isolement entraînée sur l’ensemble d’entraînement.
Quantification de l’incertitude
Comment évaluer le risque associé à une prédiction ? Les intervalles de prédiction sont indispensables pour toute prédiction fiable d’un algorithme IA. En effet, ils sont étroitement liés à l’évaluation des risques et à la théorie de la décision. Pour cela, nous avons utilisé MAPIE, un package open-source hébergé sur scikit-learn-contrib. MAPIE s’appuie sur l’inférence conforme et calcule les intervalles de prédiction avec un paramètre de confiance spécifié par l’utilisateur pour tout modèle prédictif [4].
Par exemple, dans le graphique ci-dessous, vous pouvez voir les prédictions du modèle sur le jeu de données de test avec une prédiction surlignée en rouge. La prédiction rouge a un intervalle de prédiction dans lequel la vérité tombe dans 80% des cas. En plus d’un indicateur solide sur la fiabilité d’une prédiction, il peut être directement exploité par les décideurs pour évaluer la valeur de la prédiction ou non, compte tenu de l’incertitude du résultat.
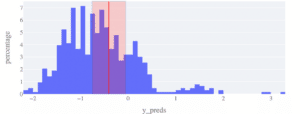
Figure 8 : Quantification de l’incertitude. La ligne verticale rouge est la prédiction sur un point de données choisi, enveloppée par une plage d’incertitude, contenant la vérité avec un niveau de confiance de 80%. Ceci peut être comparé à la plage de toutes les autres prédictions sur l’ensemble de test (histogramme bleu).
Pour donner plus de contexte à une incertitude de prédiction donnée, il peut être utile de considérer l’incertitude de toutes les autres prédictions du jeu considéré. Cela permet de juger de l’incertitude d’un point de données particulier par rapport à d’autres prédictions. Dans le graphique ci-dessous, nous montrons comment notre point de données en noir se compare à l’ensemble des intervalles de prédiction. Toutes les prédictions présentant des incertitudes exceptionnellement importantes pourraient être rejetées par les utilisateurs finaux, les jugeant trop risquées.
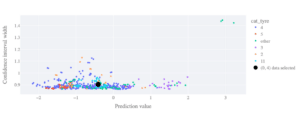
Figure 9 : Largeurs des intervalles de prédiction (confiance de 90 %) en fonction de la valeur prédite. Différentes couleurs indiquent différentes valeurs d’une variable catégorielle d’intérêt. Le point noir met en évidence un point particulier en cours d’étude. Nous pouvons voir directement quelles observations sont soumises à des intervalles de prédiction anormalement grands.
À retenir
Dans cet article, nous avons présenté une méthodologie appelée domaine de validité. Celui-ci est crucial pour construire un modèle de confiance et aider les entreprises à être sereines face aux prédictions d’un modèle. Les deux problématiques soulevées sont les suivantes :
- « Comment s’assurer que les données d’entrée en production sont valides ? »
- « Comment faire confiance à la prédiction ? »
Avec quelques outils simples, nous avons présenté la notion de domaine de validité, qui s’articule autour de trois aspects clés :
- Auditabilité : comprendre l’ensemble d’entraînement avec une documentation adéquate et être capable de reproduire toutes les étapes du processus de modélisation.
- Validation métier : valider que chaque nouveau point de données est conforme aux exigences élémentaires de l’entreprise et être capable d’interpréter correctement le résultat, avec un œil critique.
- Validation technique : évaluer la normalité d’un point de données avant de prendre une décision et quantifier l’incertitude de la prédiction.
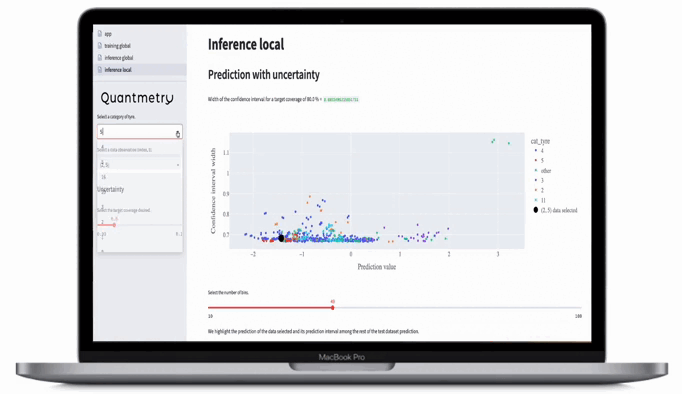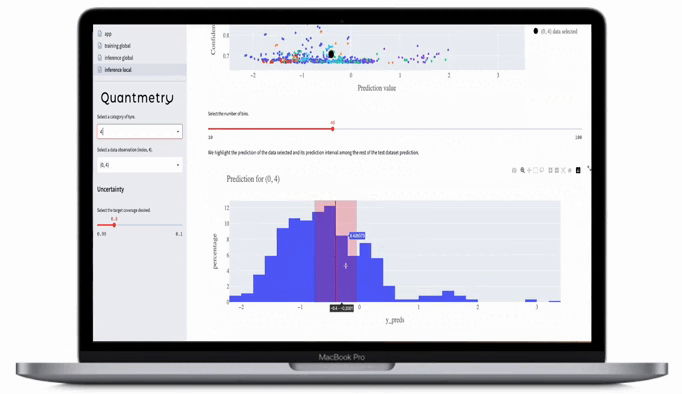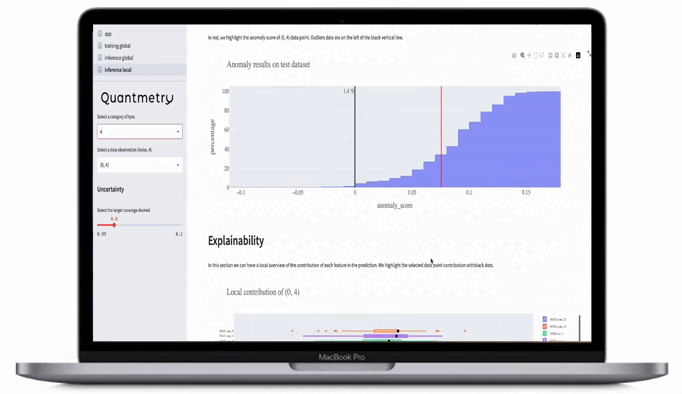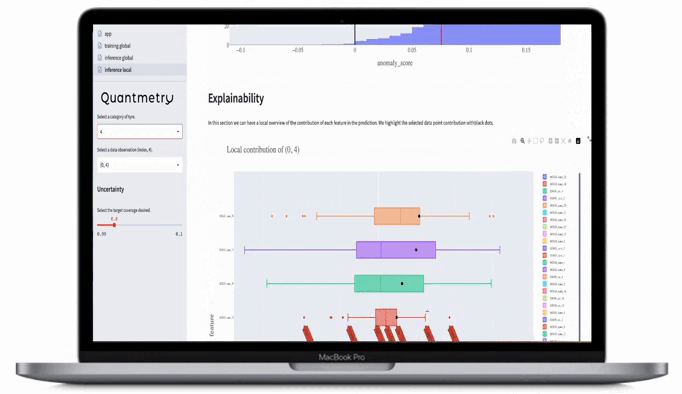
Figure 10 : Illustration d’un tableau de bord du domaine de validité présentant les indicateurs de confiance décrits dans cet article.
[1] Gebru et al. 2018, Datasheets for Datasets, arXiv 1803.09010
[2] Mitchell et al. 2018, Model Cards for Model Reporting, arXiv 1810.03993
[3] Molnar 2022, Interpretable Machine Learning
Les membres de l’expertise Reliable AI développent des modèles performants, fiables et maîtrisés, sur l’ensemble du cycle de vie, pour une IA de confiance.

Data Scientist junior
Nicolas a récemment accompagné l’expertise Reliable AI afin de développer le démonstrateur de faisabilité scientifique et technologique du concept domaine de validité.

Data Scientist confirmé
Philippe est également un artisan de l’expertise Reliable AI. Il a abordé de nombreux projets sous le prisme IA de confiance et devient formateur sur des thématiques comme l’équité et les biais algorithmiques.

Expert de l'expertise Reliable AI
Grégoire dirige les orientations scientifiques sur le thème IA de confiance, comprenant l’intelligibilité, la robustesse, l’équité et la frugalité des algorithmes.