

EACL 2021 - Revue des dernières innovations en NLP

EACL 2021 – Revue des dernières innovations en NLP
Introduction – EACL2021
Nous avons assisté à la conférence EACL 2021, version Européenne de la conférence ACL (Association for Computational Linguistics) et lieu de présentation des dernières innovations et recherches dans le monde de la linguistique informatique et du NLP. Nous avons été passionnés par les différentes présentations et nos consultants ont choisi les interventions qui les ont marquées pour vous en proposer une rapide restitution sur notre blog !
N’hésitez pas à choisir directement les sections qui vous intéressent parmi les suivantes : les perspectives pour le traitement automatique du langage, les modèles de langue et la santé, la traduction vocale, les biais et les méthodes de contrôle pour la génération de texte, l’intelligibilité, le NLP et les réseaux sociaux, l’analyse syntaxique et pour finir les modèles de langue comme bases de connaissances !
Nous avons également présenté les travaux de la thèse NLP encadrée chez Quantmetry lors du student workshop de EACL. Il s’agit de travaux originaux sur les embeddings de phrases réalisés par Antoine Simoulin.
Spoiler alerte : On vous reparlera NLP très rapidement pour vous présenter TALN 2021 où nous présenterons notre modèle GPT-FR (nous travaillons actuellement pour le rendre disponible en Open-Source sur Hugging Face, ici !).
Perspectives pour le NLP
Présentation d’ouverture : Bridge the gap between computational and theoretical linguistic
Marco Baroni — research scientist at Facebook AI Research (FAIR)
Marco Baroni propose de prendre du recul et de réfléchir à la relation entre informatique et linguistique théorique. Il part de l’observation que les réseaux neuronaux profonds ont d’excellentes compétences grammaticales. Par exemple, GPT-2 génère des textes corrects, avec une gestion des accords (pluriels, etc.) même de longues distance, en dépit de toute connaissance linguistique préalable. Il observe que malgré ces succès, l’impact de l’apprentissage profond sur les publications linguistiques est très limité.
L’inverse est également vrai : contrairement à l’apprentissage profond, les méthodes linguistiques sont capables de faire des prédictions sur des modèles encore non observés. À cet égard, les méthodes statistiques sont médiocres car les modèles capturent des schémas linguistiques mais ne peuvent pas découvrir de nouveaux schémas non observés. Il nous manque une compréhension de la manière dont les modèles traitent le langage.
Présentation de fin : Why is AI harder than we think
Melanie Mitchell — Professor at the Santa Fe Institute
Melanie Mitchell énumère de multiples prédictions sur l’essor prochain de l’IA et observe qu’une grande partie d’entre elles n’ont pas encore été réalisées. Compte tenu de ces observations, elle conclut que l’IA est plus difficile que nous le pensons et énumère 5 raisons ou erreurs qui expliquent les difficultés à atteindre une IA générale :
Erreur n°1 : L’IA spécifique se situe sur un continuum avec l’IA générale. Les progrès de l’IA ne sont pas nécessairement continus et nos percées actuelles pourraient n’être que des étapes progressives vers une véritable intelligence informatique.
Erreur n°2 : les choses faciles sont faciles et les choses difficiles sont difficiles. Cette affirmation décrit le paradoxe de l’IA selon lequel les choses faciles pour nous ont tendance à être difficiles pour les machines et inversement.
Erreur n°3 : L’attrait de la « mnémotechnie à souhait ». Nous avons tendance à utiliser un vocabulaire humain pour décrire les machines. Nous prétendons qu’elles « comprennent » alors qu’en fait le processus mis en place est très différent de l’idée d’apprentissage au sens humain. Les machines n’apprennent pas les concepts généraux et ne sont pas capables de s’adapter à des situations très différentes.
Erreur n°4 : l’intelligence est dans le cerveau. L’IA n’est pas qu’une question de puissance de calcul. En effet, l’intelligence humaine ne peut être séparée de la façon dont nous faisons l’expérience du monde physique et de l’écoulement du temps.
Erreur n°5 : l’IA peut capturer une « intelligence pure », sans limites ni biais humains, et peut se voir assigner n’importe quel objectif. L’être humain ne se contente pas d’atteindre un objectif, quels qu’en soient les moyens et le coût. Nous ne réduirions pas la population humaine à zéro pour réduire la concentration de dioxyde de carbone, par exemple.
Melanie Mitchell donne des indications sur le chemin qu’il nous reste à parcourir vers l’IA générale. Elle déclare que ce que nous accomplissons actuellement n’est pas vraiment une théorie scientifique de l’intelligence, mais plutôt une théorie alchimique de l’intelligence pour l’IA.
Les modèles de langue et la santé
Multilingual Negation Scope Resolution for Clinical Text (Haartman et al., 2021)
Cas d’usage : Identifier la portée d’une négation dans une phrase, clefs d’une bonne compréhension de données médicales.
Technologies : BERT multilingue et Zero-Shot Learning
Dans l’objectif d’identifier une négation, l’article utilise plusieurs jeux de données en espagnol et en français. La méthode fonctionne en deux étapes. Tout d’abord, le système identifie l’indice de négation en utilisant une méthode basée sur un dictionnaire. Ces indices peuvent être syntaxiques ou lexicaux : « Le patient est incapable de bouger sa main » ou encore « Le médicament n’a pas réussi à guérir l’asthme du patient ». Ensuite, un modèle BERT multilingue est utilisé pour identifier la portée de la négation en utilisant une méthode d’étiquetage de séquences.
Les auteurs utilisent ici plusieurs jeux de données dans des langues différentes, dans des domaines différents et sur des tâches différentes pour montrer que cela permet de pallier au manque de ressources que l’on est amené à rencontrer.
Et les résultats sont compétitifs ! Il est intéressant de noter que le fait de se fier uniquement aux indices et à la ponctuation conduit déjà à de bons résultats. En outre, l’article propose une application intéressante de transfert de domaine en adaptant leur modèle sur un corpus non médical.
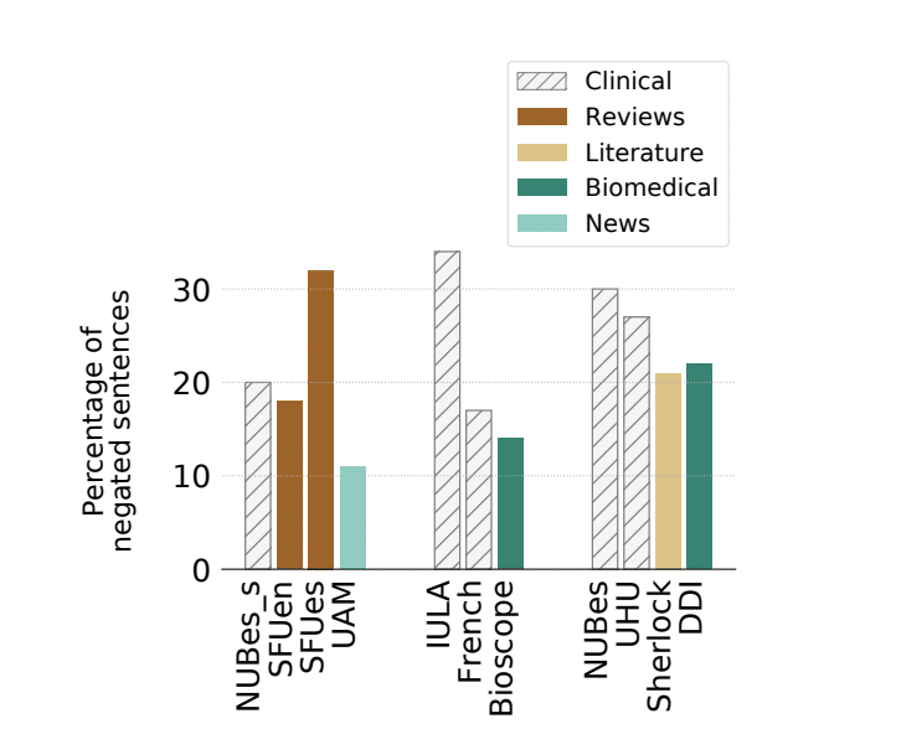
Pourcentage de phrases négatives dans les textes cliniques
et non-cliniques
Clinical Outcome Prediction from Admission Notes using Self-Supervised Knowledge Integration (Van Aken et al., 2021)
Cas d’usage : Prédiction de diagnostic, de la mortalité, de la durée du séjour et du service de traitement suite aux notes médicales d’admission
Technologies : BERT spécialisé sur un corpus médical réduit ce qui permet grâce aux bénéfices du modèle de langue de corriger les notes des médecins / comprendre les abréviations médicales / extraire des thématiques (facteurs de risques, symptômes, etc.)
Lorsqu’un patient arrive aux urgences, les médecins doivent rapidement établir un diagnostic à partir de “notes cliniques” d’admission, où les informations sont souvent éparses, abrégées, etc. Pour assister les médecins dans leur tâche, les chercheurs proposent un modèle qui ne nécessite qu’un millier de diagnostics et de procédures pour l’entraînement, et qui prédit les informations cliniques nécessaires à l’hospitalisation, telles que le diagnostic, les potentielles interventions ou procédures de soin, l’estimation de la durée du séjour, etc.
L’algorithme se compose d’un modèle BERT, qui est pré-entraîné une nouvelle fois, et de façon auto-supervisée, sur des données médicales, afin de le rendre apte à produire des représentations de résultats cliniques. Enfin, on ajoute une phase d’apprentissage supervisé pour apprendre au modèle à inférer sur les informations cliniques.
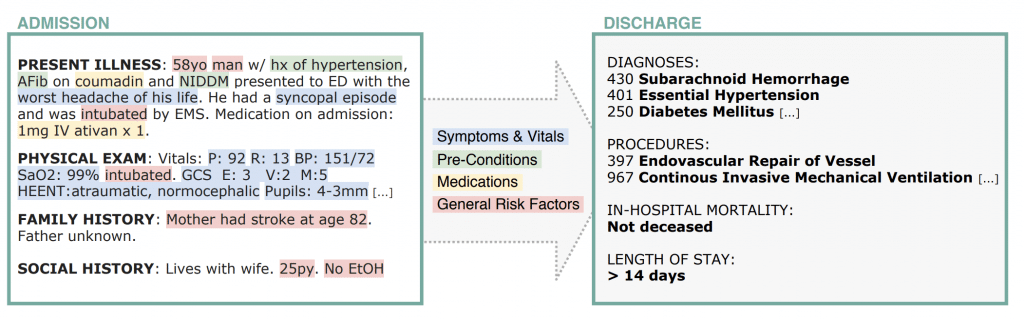
Un exemple d’admission et de résultat de la tâche de prédiction. Le modèle doit extraire les variables du patient et apprendre des relations complexes entre elles afin de prédire le résultat clinique.
Traduction vocale
End-to-End Speech Translation (Niehues et al., 2021)
Cas d’usage : Présenter l’évolution globale de la traduction vocale de bout en bout. Présentation des méthodes classiques et nouvelles utilisées dans ce domaine. Présentation de quelques domaines d’application.
Technologies : LSTM, ConvLSTM, Transformers, Encodeur Pyramidal, BPE, Traduction vocale multilingue, wav2vec + modèle pré-entraîné BART.
Ce tutoriel présente l’évolution de la traduction vocale depuis les années 80 jusqu’à aujourd’hui.
Tout d’abord, la traduction vocale est une tâche qui convertit automatiquement une entrée vocale dans une langue en une sortie dans une autre langue, qui peut être sous forme de texte ou de parole. L’approche traditionnelle de la traduction vocale était appelée « approche en cascade » et consistait à construire deux modèles distincts : un modèle de reconnaissance automatique de la parole (ASR) et un modèle de traduction automatique (MT). Cependant, les performances étaient généralement affectées par la suppression des minuscules, de la ponctuation, des disfluences (“um”, “uh”, répétition de mots, …) et des erreurs de sortie dans la partie ASR. C’est la raison pour laquelle nous nous sommes ensuite tournés vers des approches End-to-End qui n’ont pas de représentations discrètes intermédiaires.
L’approche présentée utilise le modèle seq2seq basé sur un encodeur et un décodeur. Ses avantages sont l’accès direct à l’audio pendant la traduction et l’absence de propagation des erreurs à travers les différentes étapes de l’approche en cascade. Aujourd’hui, certains travaux visant à remplacer la partie encodeur par des transformers ont été suggérés. Cependant, en raison de la complexité et des coûts de calcul élevés des transformers, les modèles basés sur les LSTM avec réduction de la dimensionnalité par des couches convolutionnelles ou un encodeur pyramidal restent souvent les meilleurs choix dans les cas de ressources faibles.
En outre, les auteurs démontrent comment les données disponibles en ASR et MT pourraient aider à augmenter les ressources de données faibles dans la traduction vocale de bout en bout via l’apprentissage multi-tâches et l’apprentissage par transfert (grand modèle pré-entraîné tel que l’encodeur wav2vec + décodeur BART).
Enfin, ils ont présenté les multiples avantages d’un modèle de traduction multilingue de la parole, tels que la réduction des données d’entraînement nécessaires, la prise en charge de plusieurs langues dans un seul modèle, la traduction zéro-shot (traduction entre les langues sans données d’entraînement parallèles). Aujourd’hui, de nombreuses architectures ont été expérimentées : encodeur et décodeur individuel pour chaque langue Escolano et al, 2020 – encodeur et décodeur conjoint – Di Gangi et al, 2019).
Bonus : Aujourd’hui, les méthodes de Speech Translation SOTA peuvent être appliquées dans le monde réel avec par exemple de la génération automatique de sous-titres et de la traduction simultanée.
Biais et méthodes de contrôle pour la génération de texte
Changing the Mind of Transformers for Topically-Controllable Language Generation (Chang et al., 2021)
Cas d’usage : Développement d’une encyclopédie interactive à l’aide d’un chatbot, permettant d’approfondir un sujet au fur et à mesure en interagissant avec le chatbot. Une surcouche permettant de contrôler/cibler les thématiques de la réponse en fonction de la question.
Technologies : Clustering local pour proposer des topics pertinents en fonction de la question, et modèle GPT-2 pour la génération de texte en fonction de la thématique choisie.
Idée d’application : Moteur de recherche interactif dans une base de connaissances internes, ce qui permettrait d’aider les conseillers qui ont besoin d’informations provenant d’autres secteurs.
Il est fréquent de vouloir en apprendre sur une thématique, sans pour autant avoir une idée précise des informations que l’on cherche à obtenir sur ledit sujet. Les chercheurs proposent alors une encyclopédie interactive à l’aide d’un chatbot, qui suggère des sous-thématiques en lien avec la question de l’utilisateur, puis qui génère automatiquement des réponses adaptées aux sous-thématiques choisies par l’utilisateur, et qui itère ce procédé autant de fois que souhaité. Le programme permet donc d’approfondir un sujet en interagissant avec le chatbot, en contrôlant bien la pertinence des réponses apportées en fonction de la question initiale. Une telle application représente une mine d’or pour des conseillers qui voudraient obtenir des informations stockées en interne sur un produit ou protocole.
D’un point de vue technique, le modèle se compose de deux entités: d’abord un algorithme de clustering local pour proposer des sous-thématiques pertinentes en fonction de la question initiale posée par l’utilisateur; puis d’un modèle GPT2 pour la génération de texte qui constitue les réponses apportées en fonction des sous-thématiques choisies.
Étant donné un input, le modèle fournit des sujets potentiels. L’utilisateur peut alors guider le processus de génération en choisissant un sous-ensemble de sujets.
Debiasing Pre-trained Contextualised Embeddings (Kaneko et al., 2021)
Cas d’usage : Dé-biaiser des embeddings de mots contextualisés
Technologies : BERT et autres modèles de langue
Idée d’application : Utile pour tous les cas d’usages de classification si l’on souhaite dans un premier temps limiter des biais comme le biais de genre
La problématique est intéressante car ce type de méthode se concentrait jusqu’ici sur les embeddings non contextualisés. Ici, dans le but de dé-biaiser un modèle de langue et les embeddings qu’il produit, le modèle est affiné sur un jeu de données contenant des phrases dans lesquelles le pronom il/elle peut être utilisé indifféremment. Le modèle est ainsi entraîné à prédire indifféremment l’un des deux pronoms, réduisant ainsi le biais obtenus sur à la phase de pré-entraînement sur des corpus classiques.
Ensuite, le modèle est évalué sur un benchmark standard pour vérifier que le processus n’a pas trop altéré le pouvoir de prédiction.
Intelligibilité
Language modelling as a multi-tasking problem (Weber et al., 2021)
Cas d’usage : Utiliser les modèles multitâches et la linguistique pour comprendre comment les modèles de langues apprennent. L’idée vient du fait que lorsque nous apprenons à produire un langage acceptable, nous devons apprendre un grand nombre de petites règles de construction du langage.
Technologies : Apprenant multitâche entraîné sur des tâches de licence NPI – corpus de Warstadt et al. (2019). Modèles LSTM unidirectionnels
L’article vise à valider les 3 hypothèses suivantes. Premièrement, la modélisation du langage consiste en de nombreuses sous-tâches implicites telles que les règles de construction du langage qui sont optimisées en parallèle. Ceci est très similaire à l’apprentissage multitâche. Deuxièmement, les interactions de ces sous-tâches sont déterminées par leur similarité linguistique. Troisièmement, ces sous-tâches et la similarité peuvent être déduites par la théorie linguistique.
Ils ont réalisé des expériences en utilisant des contextes de licence NPI (negative polarity item) comme sous-tâches. Les NPI sont des expressions qui ne sont acceptables que lorsqu’elles apparaissent dans un certain contexte (contexte de licence NPI). Le travail consistait à entraîner des apprenants multi-tâches basés sur des LSTM unidirectionnels sur le corpus de Warstadt et al. (2019).
Les résultats ont montré que moins un contexte de licence est fréquent, moins le modèle a besoin d’exemples pour l’apprendre. Le modèle est en effet capable de transférer des connaissances à partir de connaissances acquises précédemment. De plus, un modèle entraîné avec le corpus de tous les contextes apprend plus rapidement et obtient de meilleures performances qu’un modèle entraîné avec des corpus de contextes isolés.
Enfin, ces expériences ont prouvé que le comportement d’apprentissage des modèles linguistiques est fortement basé sur l’utilisation de similitudes issues de la théorie linguistique et qu’ils les exploitent pour apprendre des constructions linguistiques similaires avec moins de données et pour atteindre une plus grande précision. Ce sont surtout les tâches les moins fréquentes qui bénéficient de cet effet.
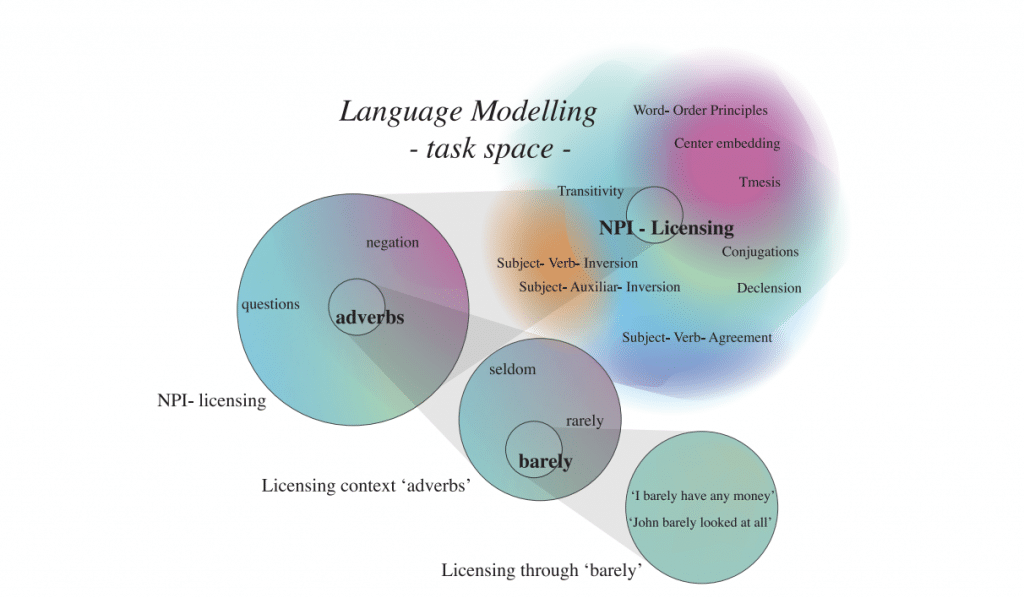
Une visualisation conceptuelle d’une hiérarchie de tâches de modélisation du langage, de la modélisation du langage dans son ensemble à des exemples uniques, avec des similitudes complexes entre les tâches. Les couleurs indiquent les similarités entre les tâches.
NLP et réseaux sociaux
Computational Social Choice and social media I beg to differ: A study of constructive disagreement in online conversations (De Kock et al., 2021)
Cas d’usage : Comprendre le point d’inflexion des conflits grâce à un modèle qui détecte un désaccord constructif dans les conversations en ligne.
Technologies : Réseaux d’attention hiérarchique, LSTM, modèle basé sur les caractéristiques, entraîné sur le jeu de données WikiDisputes.
Idée d’application : Utiliser un modèle de détection de désaccord constructif dans les messages de la boîte de réception du commerce électronique pour hiérarchiser les messages ou les incidents.
Dans Wikipédia, toute personne peut éditer un article. Cependant, il peut y avoir des désaccords entre les rédacteurs. Ces conversations en ligne sur les désaccords sont disponibles sous la forme d’un ensemble de données : WikiDisputes. En fait, dans Wikipédia, chaque article a une page d’édition avec une étiquette « dispute » pour indiquer aux lecteurs que certains contenus sont contestés.
L’article propose d’entraîner un modèle prédisant si la dispute sera escaladée ou modérée par un médiateur avec WikiDisputes. Ils ont utilisé des modèles basés sur des caractéristiques (toxicité, sentiment, politesse, …) et des réseaux neuronaux (Glove, LSTM, Hierarchical Attention Networks) pour former un modèle de prédiction d’escalade. Ce sont les réseaux d’attention hiérarchique qui ont obtenu les meilleurs résultats.
Ils ont également utilisé les prédictions des modèles pour identifier les points d’inflexion des conflits et comprendre comment les prédictions des modèles changent tout au long de la conversation ; s’il est possible de prédire le résultat dès le début, ou s’il y a souvent un point d’inflexion dans une conversation qui change le résultat. Les résultats ont montré que lorsque la totalité de la conversation a été observée, les signaux situés plus tard dans la conversation sont souvent importants pour prédire le résultat.
Ce type de modèle pourrait être appliqué aux messages de la boîte de réception du commerce électronique afin de hiérarchiser les messages auxquels les vendeurs ou les opérateurs de la place de marché doivent répondre. La détection automatique des escalades aidera probablement à comprendre quand et ce qui rend les clients mécontents en étudiant les points d’inflexion.
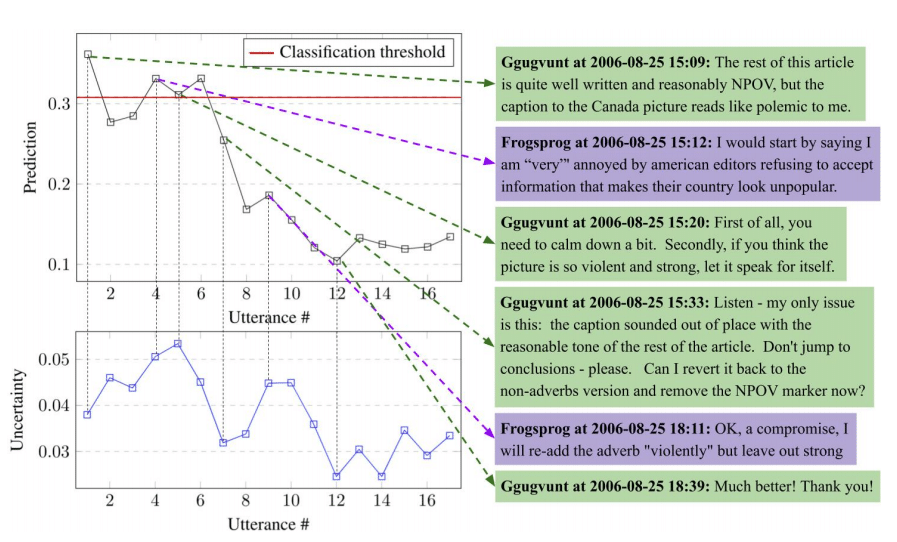
Prédictions du modèle et incertitude tout au long d’une conversation issue de WikiDisputes.
L’analyse syntaxique
Unsupervised Natural Language Parsing (Introductory Tutorial) (Tu et al., 2021)
Cas d’usage : De nombreuses tâches nécessitent une analyse syntaxique d’un texte, des relations sémantiques, de la structure du texte, etc. Ces tâches profiteraient d’un modèle performant non supervisée, sans nécessité d’entraînement sur de grands corpus annotés difficiles à produire.
Technologies : Modèle d‘analyse syntaxique non supervisée, approches générative et discriminative
L’analyse syntaxique non supervisée vise à identifier la structure syntaxique d’une phrase. Il s’agit d’un élément clé du pipeline NLU. Cependant, dans le domaine de l’apprentissage profond, l’analyse syntaxique perd de son influence en raison de l’émergence des modèles séquentiels et d’attention, qui ne nécessitent pas de structure externe. Néanmoins, certaines tâches telles que l’étiquetage des rôles sémantiques ou la méthode de distillation des connaissances du RNNG reposent toujours sur ces méthodes.
L’analyse syntaxique non supervisée vise à apprendre un analyseur syntaxique sans données annotées. On peut distinguer deux classes d’approches. Les approches génératives modélisent la probabilité conjointe de la phrase et de l’arbre d’analyse correspondant. Ces méthodes comprennent l’apprentissage de structure et l’apprentissage de paramètres. Les approches discriminatives modélisent la probabilité conditionnelle ou le score de l’arbre d’analyse en fonction de la phrase. Cela inclut l’auto-encodeur et le VAE.
Modèles de langage comme bases de connaissances : représentations d’entités, détections de thématiques et moteur de recherche Q&A
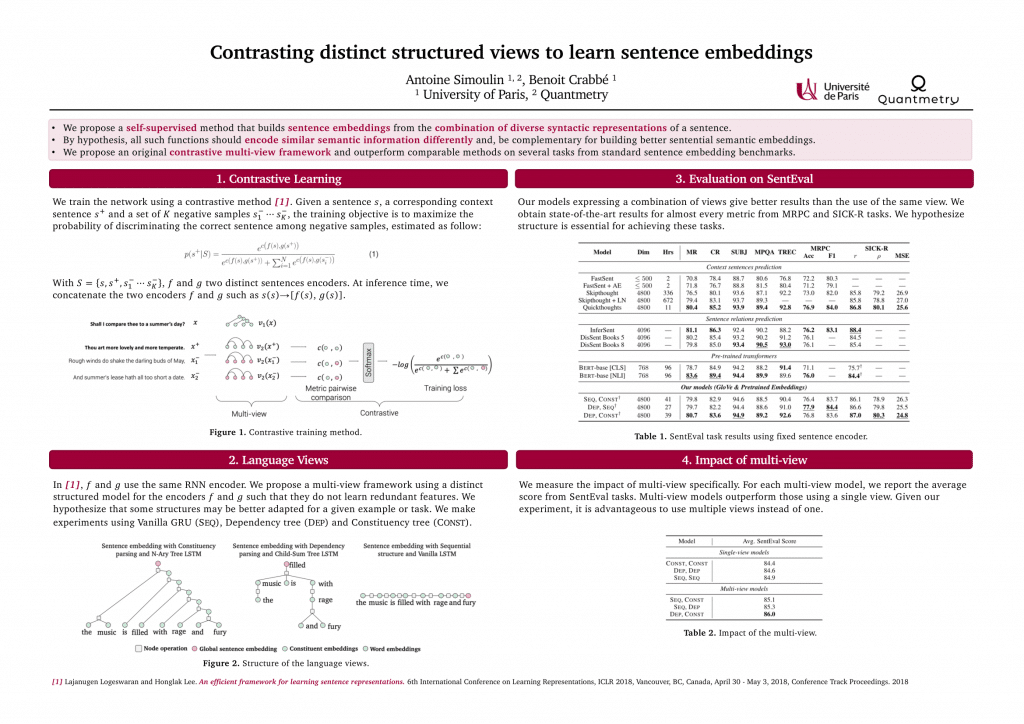
Contrasting distinct structured views to learn sentence embeddings (Simoulin et al., 2021)
Cas d’usage : Moteur de recherche, exploration de données
Technologies: LSTM et TreeLSTM
Nous avons présenté notre article au workshop étudiant de EACL. Nous proposons une méthode auto-supervisée qui construit des embeddings de phrases à partir de la combinaison de diverses représentations syntaxiques dans le but d’obtenir de meilleures représentations.
Par hypothèse, toutes ces fonctions devraient encoder des informations sémantiques similaires et être complémentaires pour construire de meilleurs embeddings sémantiques. Nous proposons une méthode originale s’appuyant sur l’apprentissage par discrimination et avec plusieurs vues. Nous obtenons des résultats à l’état de l’art sur plusieurs tâches des benchmarks standards d’évaluation des embeddings de phrases.
Adaptive Mixed Component LDA for Low Resource Topic Modeling (Sia et al., 2021)
Cas d’utilisation : Détection de sujets ou de thèmes abordés dans un corpus de documents, lorsque le corpus contient peu de documents.
Technologies : Latent Dirichlet Allocation (LDA) et embeddings
Lorsqu’un corpus contient peu de documents, il est difficile d’en extraire les thématiques abordées dans ces documents, car certains mots déterminants de ces thématiques apparaissent trop peu dans le corpus pour être pris en compte par les algorithmes. Or, l’extraction automatique des thématiques abordées dans un corpus de documents possède de très nombreuses applications. Dans un service après-vente, il est très important de pouvoir déterminer les différentes critiques qu’émettent les usagers dans leurs commentaires pour réagir au plus vite.
Les chercheurs apportent alors une solution pour gérer les petits corpus de documents. Le modèle utilisé est une adaptation de la LDA. Rappelons que la LDA est un modèle probabiliste qui infère sur la probabilité qu’un mot appartienne à un thème donné, et qui utilise pour cela essentiellement deux probabilités discrètes (estimées par comptage empirique) : celle de tirer le mot sachant qu’on est dans un thème donné, et celle de tirer le thème sachant qu’on est dans un document donné. Lorsqu’on dispose de peu de documents, certains mots sont très rares, et la première probabilité est alors très faible.
L’idée est alors la suivante : si le mot est rare dans le corpus, on remplace cette première probabilité par une probabilité, continue cette fois, qui est gaussienne sachant certains paramètres. L’introduction d’une probabilité continue, plutôt que d’utiliser la fréquence empirique du mot dans le corpus, permet d’utiliser la représentation sous forme d’embeddings (depuis un modèle pré-entraîné) du mot, ce qui aidera à classer le mot dans un thème. Au contraire, si le mot est fréquent, on garde le modèle classique de la LDA pour inférer sur sa probabilité d’appartenance à un thème.
On pallie donc le manque d’information sur un mot dû à la petitesse du corpus par un apport d’information extérieure sur ce mot, obtenu par un modèle pré-entraîné.
NLQuAD: A Non-Factoid Long Question Answering Data Set (Soleimani et al., 2021)
Cas d’utilisation : Extraire d’un texte des informations complexes, qui répondent à des questions auxquelles il n’est pas possible de répondre seulement avec de courts fragments du texte.
Technologies: Un jeu de données (NLQuAD) inédit pour de la génération automatique de réponses à des questions sur un texte, dans le cas où les questions nécessitent de longues réponses (plusieurs phrases et développements d’opinions), qui peuvent provenir de passages différents dans le texte. Également, une comparaison des modèles (BERT, RoBERTa et Longformer) entraînés sur ce jeu de données, ce qui permet de bien meilleurs résultats qu’avec d’autres jeux de données.
Idée d’utilisation: presse (connaître l’opinion de quelqu’un à partir d’un texte qu’il a écrit); service client (réponses à des problèmes concernant un mode d’emploi)
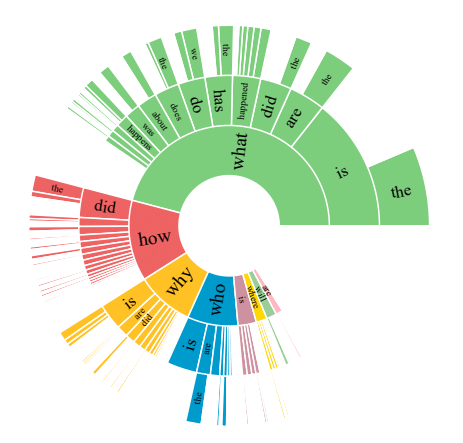
Distribution des types de questions présentes dans NLQuAD.
La génération automatique de réponses à des questions posées sur un texte est une branche très importante du NLP car elle permet d’extraire de l’information d’un texte sans être obligé de le lire en entier. Toutefois, les modèles existants n’ont pas été entraînés pour répondre à des questions complexes. En effet, ces modèles se contentent d’extraire des fragments de phrases dans le texte en guise de réponse, ce qui les rend incapables de répondre à des questions qui nécessitent de longues réponses (plusieurs phrases, développements d’opinions, etc.). En particulier, la réponse à une question complexe sur un texte peut se composer de plusieurs phrases qui proviennent de différents passages au sein du texte, parfois très éloignées les unes des autres , que les modèles actuels ne parviennent pas à rapprocher pour les extraire.
Les chercheurs fournissent alors un jeu de données (NLQuAD) pour que les modèles NLP actuels puissent apprendre à répondre à des questions complexes, et qui entend pallier toutes les limites évoquées. Les chercheurs fournissent également une comparaison des performances des modèles BERT, RoBERTa et Longformer, tous entraînés avec ce jeu de données. Longformer est celui qui performe le mieux, mais chacun des modèles est bien meilleur que les modèles précédents pour répondre à des questions complexes.

Prédiction et résultat attendu. Le rouge montre les mots qui se chevauchent avec la cible, articles (a, an, the) et ponctuations exclus.