

Comment Fine-tuner un modèle BERT pour une tâche de NER ?

Vous vous demandez comment marier une tâche NER avec un modèle BERT ? Nous vous expliquons dans cet article la démarche à mettre en place pour fine-tuner votre modèle Transformers de type BERT.
Vous trouverez le code source du projet sur le repository suivant : https://github.com/bcallonnec/ner_bert
La tâche en question est une tâche de NER (Name Entity Recognition) qui consiste à rechercher des objets textuels (c’est-à-dire un mot, ou un groupe de mots) catégorisables dans des classes telles que noms de personnes, noms d’organisations ou d’entreprises, noms de lieux, quantités, distances, valeurs, dates, etc. (Wikipédia).
Il s’agit donc d’une tâche de classification spéciale où l’on attribue une classe à chacun des mots présents dans le document plutôt qu’au document dans son ensemble. Une tâche de NER hérite des difficultés de la classification conventionnelle, mais entraine dans son sillage d’autres spécificités techniques que nous allons explorer dans cette article.
Également, puisque cet article est en français, le modèle Transformer pré-entrainé choisi est un CamemBERT. Plus précisément, le camembert-base est largement suffisant pour démontrer la faisabilité du projet.
Le modèle et le jeu d’entraînement sont téléchargés directement depuis HuggingFace 🤗.
Le framework de Machine Learning utilisé ici est PyTorch.
Nous allons découper l’analyse en plusieurs parties. Tout d’abord, nous nous intéresserons à la façon de construire un jeu d’entraînement pour une tâche de NER en utilisant le tokenizer CamemBERT. Puis, nous nous focaliserons sur la partie Model et sur la façon de construire notre réseau de neurones, d’initialiser les poids de notre modèle et de choisir notre fonction de coût. Par la suite viendra la partie sur l’entraînement de notre modèle et finalement la partie inférence du modèle.
Comment préparer votre Dataset pour votre tâche NER ?
Une partie compliquée dans la tâche de NER avec un modèle RoBERTa est que ce dernier utilise le Byte Pair Encoding lors de la tokenization des mots. Cela signifie qu’un mot peut être découpé en plusieurs sous-mots, appelés “bytes” par le tokenizer.
Par exemple le mot « antichambre » sera tokenizé comme « _anti » et « chambre ». Le mot antichambre génère donc deux tokens pour un seul et même mot. On note que certains mots ne sont pas découpés.
On comprend alors qu’il est primordial que les labels suivent les parties de mots également. Mais les parties de mots doivent-elles toutes se voir attribuer le même label ? Ou bien doit-on attribuer le label à la première partie du mot uniquement et ne pas considérer les autres parties du mot ?
On est ici face à un choix que le développeur devra prendre puisque les deux solutions sont envisageables. Il n’y a pas, à priori, de solution meilleur que l’autre. Dans un cas, le modèle doit être capable de prédire le bon label pour la première partie du mot tandis que dans l’autre, il doit prédire le bon label pour l’ensemble des parties du mot. A noter que dans le premier cas les autres parties du mot seront ignorés par la fonction du coût.
"""
Define Dataset objects used by pytorch models.
"""
from typing import Any, Dict, Sequence, Union
import torch
from torch import Tensor
from torch.utils.data import DataLoader, Dataset
from transformers import PreTrainedTokenizer
class NERDataset(Dataset):
"""Dataset designed for NER task"""
def __init__(
self,
texts: Sequence[Union[str, List[str]],
tokenizer: PreTrainedTokenizer,
max_len: int,
labels: Sequence[List[str]],
loss_ignore_index: int = -100,
propagate_label_to_word_pieces: bool = False,
) -> None:
"""
Init function
Parameters
----------
texts: Sequence[Union[str, List[str]]
List of tokenized text. The sentence is tokenized into a list of token.
tokenizer: PreTrainedTokenizer
Usually a pretrained tokenizer from HuggingFace
max_len: int
the max len of the list of tokens
labels: Sequence[List[str]]
The corresponding tag of each token
loss_ignore_index: int
Label index that will be ignore by the loss function
propagate_label_to_word_pieces: bool
Wether to propagate the label of the word to all of its word pieces or not
"""
# Convert str sentence to list of tokens
texts = [elem.split() if isinstance(elem, str) else elem for elem in texts]
# Set class attributes
self.texts: Sequence[List[str]] = texts
self.labels: Sequence[List[str]] = labels
self.tokenizer: PreTrainedTokenizer = tokenizer
self.max_len: int = max_len
self.loss_ignore_index: int = loss_ignore_index
self.propagate_label_to_word_pieces: bool = propagate_label_to_word_pieces
def __len__(self) -> int:
"""Get len of dataset"""
return len(self.texts)
def __getitem__(self, index: int) -> Dict[str, Tensor]:
"""Get item at index"""
text = self.texts[index]
tags = self.labels[index]
ids = []
target_tag = []
for idx, token in enumerate(text):
inputs = self.tokenizer(
token,
truncation=True,
max_length=self.max_len,
)
# remove special tokens <s> and </s>
ids_ = inputs["input_ids"][1:-1]
input_len = len(ids_)
ids.extend(ids_)
if self.propagate_label_to_word_pieces:
target_tag.extend([tags[idx]] * input_len)
else:
target_tag.append(tags[idx])
target_tag.extend([self.loss_ignore_index] * (input_len - 1))
ids = ids[: self.max_len - 2]
target_tag = target_tag[: self.max_len - 2]
# Reconstruct specials tokens at start and end
ids = [self.tokenizer.cls_token_id] + ids + [self.tokenizer.sep_token_id]
target_tag = [self.loss_ignore_index] + target_tag + [self.loss_ignore_index]
mask = [1] * len(ids)
token_type_ids = [0] * len(ids)
padding_len = self.max_len - len(ids)
ids = ids + ([0] * padding_len)
mask = mask + ([0] * padding_len)
token_type_ids = token_type_ids + ([0] * padding_len)
target_tag = target_tag + ([self.loss_ignore_index] * padding_len)
return {
"input_ids": torch.tensor(ids, dtype=torch.long),
"attention_mask": torch.tensor(mask, dtype=torch.long),
"token_type_ids": torch.tensor(token_type_ids, dtype=torch.long),
"targets": torch.tensor(target_tag, dtype=torch.long),
}
def get_data_loader(self, batch_size: int, shuffle: bool = True, num_workers: int = 0) -> DataLoader:
"""Get data loader from dataset"""
data_loader_params = {
"batch_size": batch_size,
"shuffle": shuffle,
"num_workers": num_workers,
}
return DataLoader(self, **data_loader_params)
Dans cet extrait de code nous pouvons observer que les labels suivent la tokenization en parties de mot du tokenizer. De plus, le paramètre propagate_label_to_word_pieces permet de choisir si le label est propagé à toutes les parties du mot ou s’applique uniquement à la première partie.
Enfin la méthode __get_item__(index) de notre objet dataset retourne les éléments suivants :
input_ids: encodage des tokens en identifiant numérique ;attention_mask: masque d’attention du transfomer. Nous remarquons que les tokens de paddings se voient attribuer un masque de valeur 0 ce qui signifie qu’ils seront ignorés par le modèle ;token_type_ids: non utile pour une tâche de NER ;targets: les labels attribués à chacun de nos tokens.
Voici un exemple illustré de ce que nous retourne la méthode __get_item__ pour le text suivant : “Je suis situé dans une antichambre parisienne” avec les labels associés: [1, 0, 0, 0, 0, 2, 3].






Dans cet exemple, la valeur maximale de la séquence est de 11 tokens. On observe que les valeurs du masque d’attention et des tokens type id ne varient pas selon que l’on propage les labels aux sous parties des mots ou non. L’unique différence réside dans la valeur du label qui prend la valeur -100 lorsqu’on choisit de ne pas le propager ce qui signifie qu’il sera ignoré lors du calcul de la fonction de coût.
On note qu’il existe également un format standard appelé IOB format pour labelliser les entités nommées dans un corpus. Il est cependant en dehors du cadre de cet article.
Comment construire votre Model ?
Dans cette partie les éléments abordés sont la fonction de forward, l’architecture du réseau de neurone et la fonction de coût utilisée.
def training_step(self, batch: Dict[str, Tensor], num_labels: Optional[int] = None) -> Tensor:
"""Training step for pytorch lightning Trainer"""
for key, var in batch.items():
batch[key] = var.to(self.device)
targets = batch.pop("targets")
self.optimizer.zero_grad()
outputs = self(**batch)
loss = self.loss_fn(outputs, targets, num_labels=num_labels, **batch)
loss.backward()
self.optimizer.step()
self.scheduler.step()
return loss
def forward(self, **inputs: Dict[str, Tensor]) -> Tensor:
"""Apply torch forward algorithm"""
# Get embeddings data
output = self.pretrained_model(**inputs)
# Dense net
output = self.dense_net(output[self.transformers_output])
# Output net that give prediction
output = self.output_net(output)
return output
Dans cet extrait de code et plus particulièrement dans la méthode forward, nous pouvons voir que notre réseau de neurones se compose de notre transformer pré-entrainé suivi d’une architecture dense et d’une architecture de sortie.
Le but est de récupérer l’embedding de chacun de nos tokens puis de les faire passer au travers des couches dense et de sortie. Cela donne ainsi une prédiction pour chacun des tokens présents dans notre phrase.
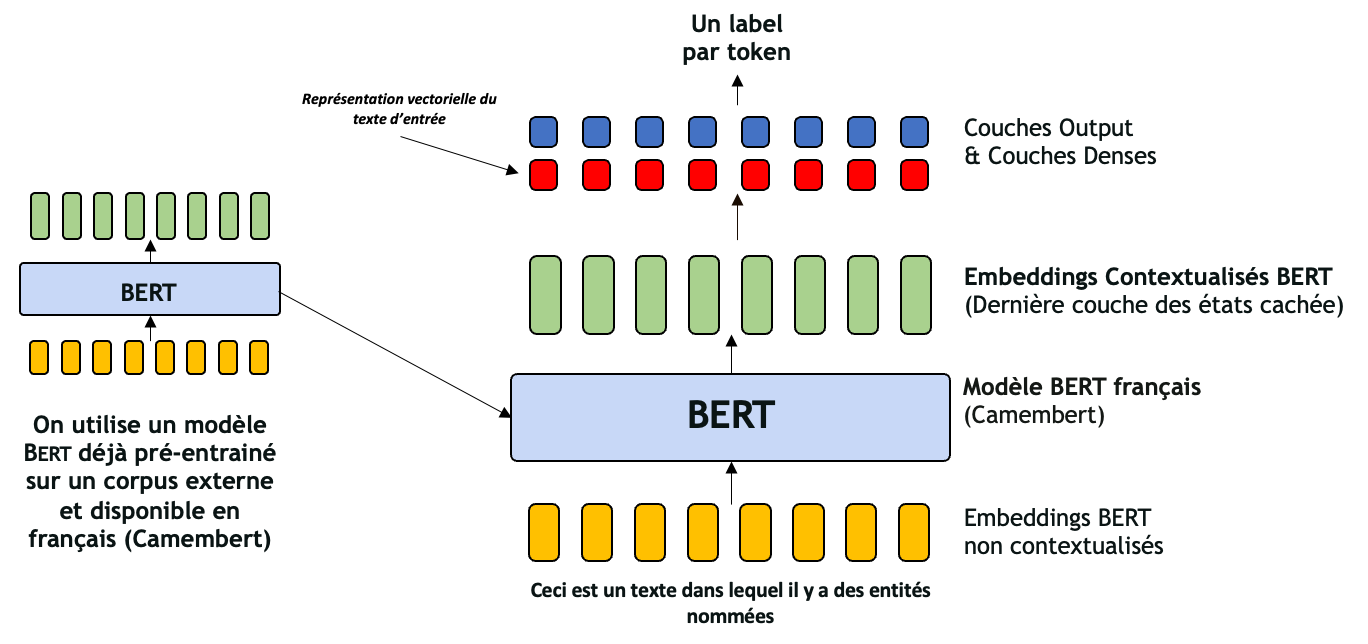
Les réseaux dense et de sortie sont deux réseaux relativement simples et sont uniquement des réseaux Multi Layer Perceptron. Nous suivons la pratique par défaut dans Hugging Face en utilisant un réseau de neurones à deux couches avec une activation non linéaire tanh. Le réseau dense contient la première couche ainsi que l’activation non linéaire tanh, tandis que le réseau de sortie contient la dernière couche du classificateur.
La fonction de coût est une Categorical Cross Entropy, fonction usuellement utilisée pour des problèmes de classification. On notera que les tokens dont la valeur du masque d’attention est à 0 seront ignorés par la fonction coût puisqu’un filtre est appliqué pour ne pas les considérer. De plus, on rappel que les labels dont la valeur est -100 seront également ignorés par notre fonction de coût et ceci est le comportement propre à cette fonction.
Pour finir, nous observons qu’il n’y pas de fonction d’activation dans notre réseau output puisque la Categorical Cross Entropy proposée par PyTorch applique d’elle-même une LogSoftmax avant de calculer la Negative Log Likelihood.
Entraînement et inférence
Avec notre model optimisé pour une tâche de NER et notre dataset, nous pouvons maintenant réaliser l’entrainement de notre modèle.
Pour cela nous utilisons ici Hydra qui permet de gérer les fichiers de configuration de façon dynamique afin de faire figurer dans la configuration le plus d’éléments possibles.
Hydra est ici très utile puisque l’on peut rapidement avoir un aperçu du modèle, du tokenizer et du dataset directement depuis le fichier de configuration. De plus, le fait de pouvoir instancier dynamiquement ces objets réduit drastiquement le nombre de lignes de code dans le script d’entraînement.
Nous utilisons également Mlflow et Tensorboard pour logger les métriques de notre modèle et tous les paramètres et hyper paramètres choisis lors de l’entrainement.
Les méthodes d’entraînement et de validation du modèle ont été sorties de notre objet NERModel puisqu’elles sont inutiles pour l’inférence. Elles amènent également avec elles beaucoup de paramètres décorrélés du modèle comme la fonction de coût ou bien les métriques de performance choisies.
Une fois notre modèle entrainé et sauvegardé, il ne nous reste plus qu’à le charger et appeler sa méthode predict.
On notera ici que les paramètres du dataset comme la longueur maximale de la séquence (seq_max) ou la loss_ignore_index n’ont pas été sauvegardés suite à l’entraînement du modèle. En effet, le but de cet article est uniquement de démontrer la faisabilité de fine tuner un transformer à une tâche de NER. Implémenter un objet qui prendrait en attribut le modèle ainsi que les paramètres du dataset est une solution pour palier à ce problème.
Finalement l’implémentation des méthodes d’entrainement, de validation et de prédiction sont similaires aux implémentations pour n’importe quelle autre tâche de Machine Learning.
Ce qu’il faut retenir
Nous avons pu voir dans cet article que fine-tuner un modèle transformer de type BERT pour une tâche de NER peut être réalisé de façon relativement succincte.
Les points d’attention de cet article sont :
- La construction du dataset et notamment faire attention à bien reporter les labels aux parties de mots fournies par le tokenizer en propageant ou non ces derniers.
- L’astuce d’ignorer les tokens dont le masque d’attention est égal à 0 lors du calcul de la fonction de coût.
- Récupérer les embeddings de chacun de nos tokens en sortie de la méthode
forwarddu transformer pré entrainé.
Références
Le code source de ce projet
https://github.com/bcallonnec/ner_bert
L’implémentation de ce modèle a été inspiré du repository mis à disposition par Abhishek Thakur.
https://github.com/abhishekkrthakur/bert-entity-extraction
Le modèle pré entrainé et le jeu d’entraînement ont été pris directement depuis Hugging face.
https://huggingface.co/
Le modèle camembert-base utilisé.
https://huggingface.co/camembert-base?text=Paris+est+la+%3Cmask%3E+de+la+France.
Le dataset utilisé.
https://huggingface.co/datasets/wikiann
Mention spéciale à Mélusine qui proposera bientôt la possibilité d’instancier des modèles transformer optimisés pour une tâche de NER. Stay Tuned !
https://github.com/MAIF/melusine
Les membres de l’expertise NLP exploitent le potentiel des données textuelles à l’aide de solutions d’IA à forte valeur ajoutée grâce à la maîtrise des technologies à l’état de l’art (modèles de deep-learning « pré-entrainés » BERT, ELMo, GPT-2 ou FlauBERT).

Data Scientist chez Quantmetry
Passionné par le Deep Learning, je me suis très vite spécialisé vers le domaine du NLP après avoir obtenu un master en Systèmes d'Information & Big Data suivi d'un mastère spécialisé en Stratégie, Conseil & Organisation.