

Google & IA Responsable : Avancée ou formalité ?

Introduction
Un grand pouvoir implique de grandes responsabilités. De nos jours, l’intelligence artificielle joue un rôle majeur dans la quasi-totalité de nos industries. Elle les transforme, les aide à se développer et répond à différentes problématiques historiques. En effet, l’automatisation de certains processus – parfois même dans des domaines sensibles – pose la question de notre dépendance à l’égard de ces nouvelles technologies qui peuvent parfois nous dépasser ou simplement reproduire des erreurs commises par les agents humains. C’est dans ce cadre-là que l’Artificial Intelligence Act est en pleine réflexion par l’Union Européenne afin de proposer de nouvelles règlementations pour encadrer l’intelligence artificielle.
Les principes de Google en termes d’IA
Certaines entreprises développent leur propre conception de ce qu’est l’intelligence artificielle de confiance afin de donner l’impression de se conformer à la réglementation de plus en plus exigeante. Dans ce contexte, Google a présenté en juin 2018 ses principes pour caractériser une IA éthique :
I. Selon Google, l’IA doit :
- Être socialement bénéfique
- Éviter l’apprentissage d’un biais non équitable (éviter des partis pris injustes, racistes ou sexistes)
- Être conçu et testé pour la sécurité.
- Être responsable pour les personnes (rendre les modèles moins opaques pour faciliter les contrôles humains)
- Inclure les principes de privacy design.
- Respecter des normes élevées d’excellence scientifique. Ce point reste assez contradictoire avec l’objectif de maitrise bénéfices/risques. En effet la recherche de performance pure d’une IA ne prend pas forcément en compte les conséquences de celle-ci, est-ce que c’est la voiture la plus rapide qui est la plus sûre ?
- Être mis à disposition pour des utilisations conformes à ces principes. (Mise en place de contrôles internes)
II. L’IA ne doit pas :
- Être susceptible de causer un préjudice global.
- Créer des armes ou n’importe quelle entité qui causerait des blessures directes.
- Aider à de la surveillance violant les normes internationales.
- Avoir des buts contraires au droit international et aux droits de l’homme
Les règlementations européennes sont bien plus précises au sujet de ce que l’IA ne peut pas « être ». Pour avoir le droit d’être présent sur le marché européen, Google devra respecter des règles bien moins floues, en accord avec l’Article 5 de la Section II sur les pratiques interdites d’intelligence artificielle.
Il est important de ne pas se laisser séduire par les efforts de compliance des géants étrangers dès lors qu’ils reposent sur une conception remodelée par leurs soins de l’IA de confiance. Pour reprendre la sémantique du numérique, c’est un cheval de Troie pour mieux imposer leur propre conception au détriment de celle que nous essayons de construire au sein de l’UE et d’imposer sur la scène internationale.
Pratiques et outils
Google répartit ses outils sous quatre axes principaux : l’équité, l’interprétabilité, la vie privée et la sécurité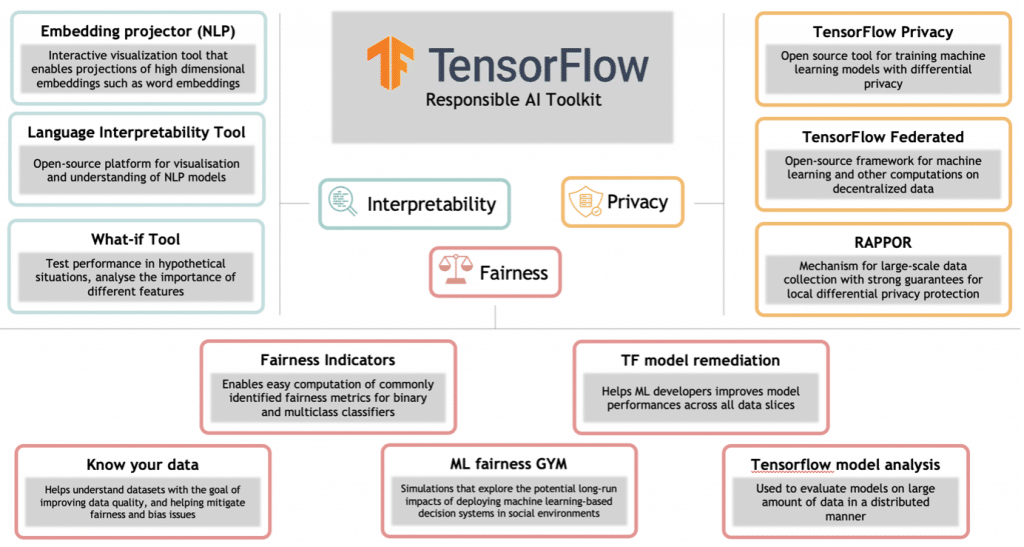
I. Equité (Fairness)
Il s’agit d’un ensemble d’outils destinés à détecter, prévenir et corriger certains problèmes de biais – préjudice en faveur ou à l’encontre d’une personne ou d’un groupe. Principalement ce sont les indicateurs d’équité qui sont fournis par Google. Il s’agit de calcul de métriques d’équité dans le cadre d’une classification binaire qui permet d’identifier assez clairement un biais. Malgré tout il s’agit de métriques d’évaluation classiques, contrairement à la librairie équivalente d’IBM (AI Fairness). Outre cela, Google propose ses outils de visualisation existants comme Know your data, Facets ou encore What-if ayant pour but de vérifier la qualité des données et mieux comprendre le jeu de données sur lequel reposera notre futur modèle.
Enfin, Google travaille également sur un outil nommé ML Fairness Gym destiné à explorer de potentiels impacts long terme sur la société et l’équité après le déploiement d’un modèle de Machine Learning.
II. Interpretabilité (Interpretability)
Google propose également des outils capables de rendre les modèles de Machine Learning plus compréhensibles, plus transparents. En effet, certains types de modèles comme ceux entrainés avec des réseaux de neurones sont difficilement explicables car le modèle va détecter des règles et propriétés ‘cachées’ dans les données. Le framework Explainable AI (faisant partie de la console Google Cloud, il est disponible en version Beta au moment où nous écrivons cet article), a pour but d’aider les Data Scientists à mieux interpréter leur modèle. Principalement, cette fonction permet de récupérer un score de contribution de chaque variable après que le modèle a réalisé une prédiction.
Ensuite Google propose des outils spécifiques au NLP comme Embedding Projector ou Language Interpretability Tool qui permettent par exemple de faire des projections d’embeddings – représentation numérique de langage naturel – en grande dimension pour mieux comprendre un embedding entrainé, par exemple.
III. Vie privée et sécurité (Privacy)
Pour la sécurité et s’assurer que les données restent privées, Google propose deux outils (Tensorflow Privacy et Tensorflow Federated).
Tensorflow Privacy est un outil permettant d’entraîner des modèles avec intimité. En effet, lorsque l’on entraine un modèle destiné au public sur des données privées, il y a une fine possibilité que le modèle mémorise certaines données spécifiques dans le jeu de données d’entrainement et que certaines de celles-ci ne soient plus privées en fonction de l’output renvoyé par le modèle sur certaines inférences. Il existe donc des techniques de Differential Privacy qui permettent de mesurer l’intimité garantie après un entrainement de modèle.
Enfin, Google propose également ce que l’on appelle un entraînement sur des données décentralisées. C’est-à-dire qu’un modèle global peut être partagé et entrainé sur des données en local. Aucune donnée sensible n’est donc partagée.
Conclusion
L’outil que Google propose pour rendre l’IA responsable est incomplet. En effet, dans les grandes lignes, le sujet a été étudié et développé par Google. Cependant, les outils mis en place sont parfois très classiques, certains existent déjà depuis plusieurs années et ont seulement été orientés à des fins éthiques.
Certains sujets comme l’incertitude, l’interpretabilité (dans des domaines hors du NLP), la qualification des données (anomalies, incomplétudes) et bien d’autres ont été totalement oubliés. Quid également de l’empreinte environnemental qui impactera inexorablement l’IA dans les prochaines années.
De plus, leur utilisation n’est pas facilitée par la stratégie de Google qui souhaite vouloir pousser jusqu’au bout l’API Tensorflow. Un réel casse-tête lorsqu’on a l’habitude de travailler avec une API standard comme scikit-learn.
Une bonne nouvelle est que d’autres grands acteurs commencent à proposer ces types d’outils (comme IBM avec l’AI Fairness 360). Mais il semble pour le moment que les outils proposés ne répondent pas forcément aux attentes, ces acteurs sachant pertinemment qu’ils n’auront bientôt plus le choix de traiter ce sujet !
Un certain nombre d’outils sont encore en phase de recherche et d’améliorations, Google mise sur la collaboration et le partage. A voir comment cela évolue par la suite…