

Trois questions pour identifier son cycle de vie des modèles

✍ Grégoire Martinon / Temps de lecture : 20 minutes.
IA en production [1], ce n’est pas une mince affaire. Dans nos précédents articles, nous avons détaillé quels étaient les grands principes de l’industrialisation [2] et du cycle de vie des modèles en production [3]. En pratique, il existe cependant plusieurs manières de suivre cette feuille de route, en s’adaptant aux contraintes de chacun. Il n’y a donc pas un mais plusieurs cycles de vies. Comment choisir ? Quelles sont les questions à se poser pour identifier son cycle de vie ?
Quelles sont les questions à se poser pour identifier son cycle de vie ?
Non pas un, mais des cycles de vie
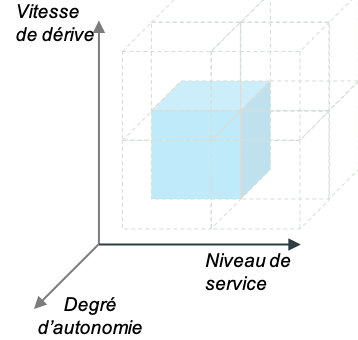
Le cycle de vie se structure autour de trois axes principaux, qui permettent de caractériser le besoin du processus métier visé : le niveau de service, la vitesse de dérive et le degré d’autonomie (voir Figure 1).
- Le niveau de service. C’est le Service Level Agreement (SLA) [4] du modèle. Il est d’autant plus élevé que la vitesse et le volume des prédictions sont élevés. Il est également d’autant plus élevé que le coût de l’indisponibilité du modèle est élevé.
- La vitesse de dérive. C’est la fréquence caractéristique de mise à jour nécessaire du modèle. Elle est d’autant plus élevée que les données et la cible de prédiction évoluent rapidement. Elle doit être comparée à la vitesse et au coût d’acquisition des labels pour savoir si l’adaptation est triviale ou non.
- Le degré d’autonomie. C’est la capacité du modèle à prendre les décisions seul. Il est d’autant plus élevé que la chaîne de décision est courte, peu bureaucratique et automatisée. Il est également lié à la capacité de l’humain à remplacer l’algorithme.
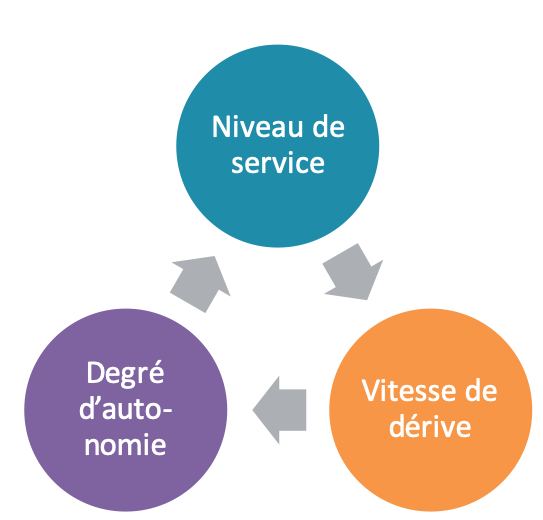
Figure 1 : les trois axes structurant le cycle de vie des modèles. Le niveau de service est lié au volume de prédictions, la vitesse de dérive à la volatilité des sources de données, et le degré d’autonomie à la complexité bureaucratique de la chaîne de décision.
Trois questions…
Afin de simplifier les choses, on peut sonder chacun de ces trois axes avec une question fermée (voir Figure 2). Pour chacune de ces questions il existe donc deux réponses possibles “oui” ou “non”. Ces questions se posent pour chaque couple entreprise – cas d’usage.
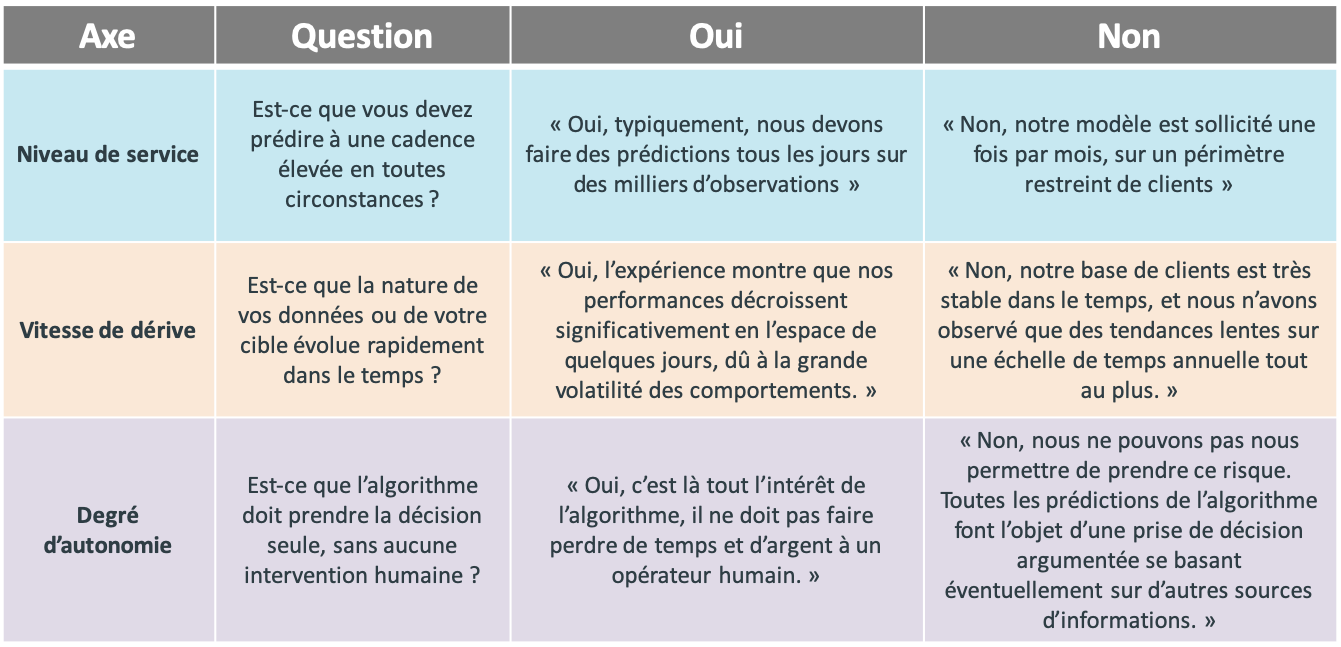
Figure 2 : les trois questions posées par le cycle de vie des modèles en production, avec des exemples de réponses possibles. Chaque question interroge l’un des trois axes décrits précédemment : niveau de service, vitesse de dérive et degré d’autonomie.
Pensez très fort à votre cas d’usage : êtes-vous capable de répondre à ces trois questions ?
C’est un exercice mental intéressant à faire en lisant cet article : penser à un cas d’usage dans votre entreprise et répondre aux trois questions de la figure 1 par oui ou par non :
- Devez-vous prédire à une cadence élevée en toutes circonstances ?
- Vos données ou votre cible sont-elles extrêmement volatiles dans le temps ?
- L’algorithme prend-il ses décisions seul ?
Faites le quizz maintenant en cliquant sur ce lien !
Question technique : à votre avis, en posant ces trois questions, combien de typologies de cycles de vie avons-nous défini ?
…Huit réponses
Bien vu ! Trois réponses binaires définissent huit possibilités (voir Figure 4 et Figure 5). Dans la suite de cet article, nous allons donner quelques éléments d’implémentation du cycle de vie des modèles propres à chacune de ces typologies avec des exemples de cas d’usage.
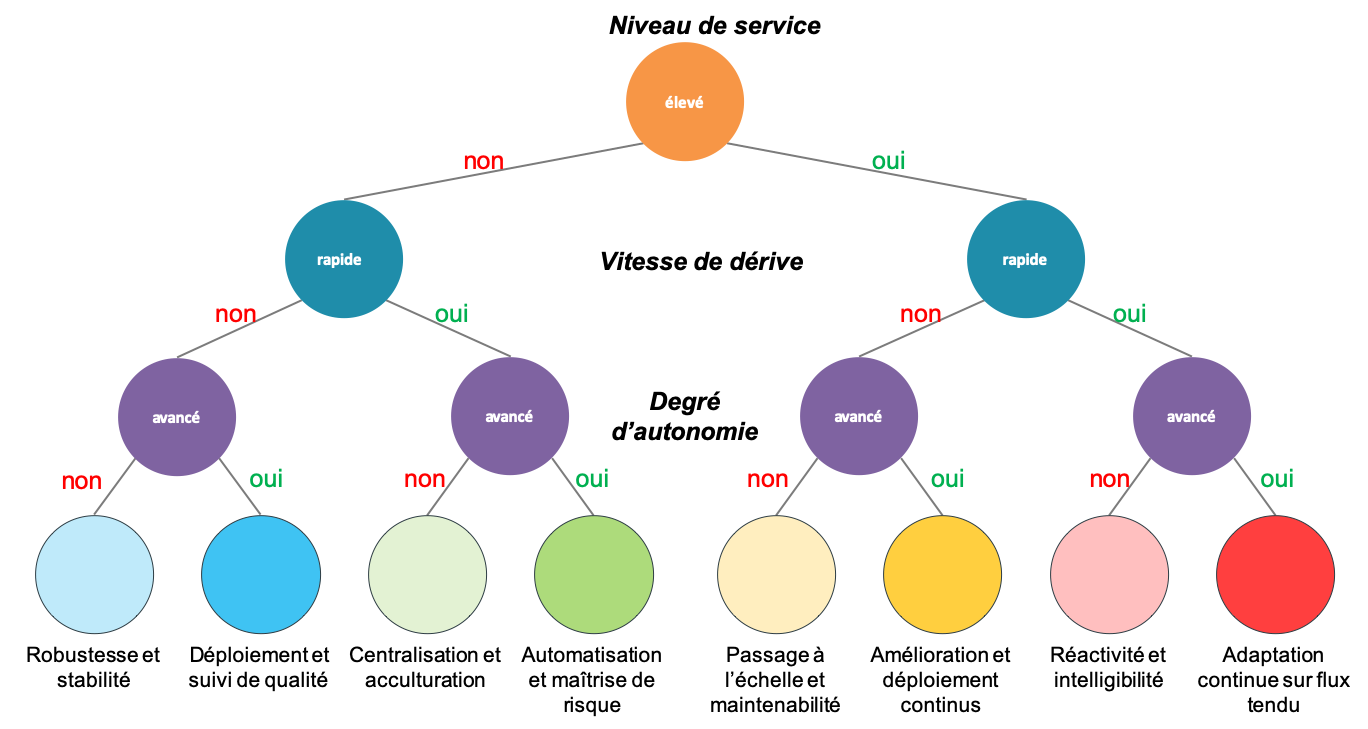
Figure 3 : trois questions, huit réponses. En réalité, c’est simplement un arbre de décision qui permet d’identifier huit typologies de cycle de vie des modèles, que nous allons détailler par la suite.
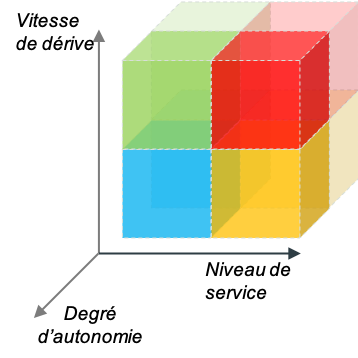
Figure 4 : Visualisation alternative de l’arbre de décision cycle de vie des modèles. On a représenté les trois axes structurants : niveau de service, vitesse de dérive et degré d’autonomie. L’arbre de décision n’est rien d’autre qu’une partition de l’espace. Le code couleur est le même que sur la figure 3.
Non, non et non : l’exemple de l’octroi de crédit

Vous êtes par exemple une banque qui met en production des modèles d’octroi de crédit immobilier. Les prédictions sont sporadiques mais avec des enjeux financiers énormes.
D’un point de vue organisationnel, c’est tout le model risk management [5] qui va permettre de faire passer à vos modèles un vrai contrôle technique, avec une séparation des compétences en (1) une équipe de modélisation, qui doit optimiser la performance, et (2) une équipe de validation, qui doit optimiser la robustesse. L’optimisation jointe de ces deux objectifs antagonistes permet de maximiser le pouvoir prédictif tout en minimisant les risques.
D’un point de vue scientifique, c’est la notion d’incertitude [6], de biais et de robustesse qui va monopoliser votre savoir-faire. Vous allez privilégier des modèles simples, faciles à maintenir, stables dans le temps et intelligibles [1]. L’objectif est d’anticiper et de quantifier les risques longtemps à l’avance afin de provisionner le budget qui permet de répondre au pire scénario.
D’un point de vue technologique, et en réponse au processus de validation interne, vous devez être capable d’auditer vos modèles passés, et de revenir à la version précédente de modélisation en conditions identiques (données, code, modèle, infrastructure). Au-delà de la robustesse de votre modèle, la robustesse de votre chaîne de traitement est garantie par l’utilisation de tests unitaires [7] sur la qualité de la donnée [8], du modèle et du code.
Non, non et oui : l’exemple du marketing digital

Vous êtes par exemple une assurance, avec un nombre limité et stable d’offres à vendre. Vous cherchez par exemple à calculer un score d’appétence qui débouchera sur l’envoi d’une newsletter ou d’une publicité. Le cycle de vie est sporadique, et les enjeux sont suffisamment faibles pour automatiser le processus rapidement.
D’un point de vue organisationnel, c’est le métier qui doit piloter le modèle. Les itérations de modèles se font sur la base des retours terrains et de la politique commerciale. En l’occurrence, le modèle donne aussi un retour sur l’appétence de la clientèle, c’est un sondage.
D’un point de vue scientifique, le monitoring du modèle se fait par décompte des ouvertures de mails ou de temps passé devant la publicité. L’intelligibilité du modèle va vous permettre de mieux comprendre les populations ciblées par le modèle et d’itérer avec l’expertise métier au rythme des campagnes publicitaires. L’apprentissage par renforcement, combiné à une segmentation client, permet d’identifier rapidement des groupes de répondants réagissant positivement à certaines sollicitations.
D’un point de vue technologique, le marketing digital se prête naturellement bien aux séquences d’A/B testing [9]. Le monitoring gagne en efficacité s’il est automatisé à l’aide d’un dashboard de suivi qui permet d’analyser et de segmenter les résultats de manière dynamique.
Non, oui et non : l’exemple de la rétention client

Vous êtes orienté Business To Customer (B2C) ou Business To Business (B2B) et vous voulez réaliser des campagnes de rétention (offres promotionnelles, rendez-vous avec des conseillers) pour empêcher vos clients de partir. Vous avez un fort enjeu de connaissance client et devez faire face à la volatilité du marché, directement influencé par vos concurrents et par des événements imprévisibles (mode, politique).
D’un point de vue organisationnel, c’est la data gouvernance [10] qui va vous permettre d’agréger toute la connaissance client disséminée dans vos systèmes d’information. De plus, l’expertise métier est centrale dans la mesure où c’est elle qui va vous renseigner sur les scénarios d’attrition client, c’est donc le métier qui doit porter le projet. Il y a également un réel enjeu d’acculturation du métier à la donnée, afin d’améliorer la qualité des données saisies la plupart du temps à la main.
D’un point de vue scientifique, vous devez traduire les scénarios métiers en variables explicatives via du feature engineering. Il y a un premier enjeu d’intelligibilité [1] du modèle et donc de sélection de variables pertinentes et parlantes au métier, l’objectif étant de convertir les prédictions du modèle en un argumentaire actionnable par le métier. Il y a un deuxième enjeu de stabilité du modèle, qui doit être réévalué régulièrement sur un historique récent qui colle à l’actualité et au dynamisme du secteur d’activité.
D’un point de vue technologique, il y a un enjeu très fort de centralisation des données et d’évaluation de la qualité de la donnée [8], qui peut être réalisé sur un DataLake ou directement sur le cloud. Il s’agit également de rendre accessibles les prédictions du modèle à tous les acteurs métiers, via un dashboard partagé de restitution des résultats.
Non, oui et oui : l’exemple de la réponse automatique de mails

Vous êtes une mutuelle ou une compagnie d’assurance, et vous devez gérer des pics de mails à certaines périodes de l’année. Par exemple à la rentrée scolaire, beaucoup de clients vous réclament des attestations scolaires, et vous voudriez automatiser la réponse à ces mails spécifiques. Par contre, les mails de ce type s’estompent avec le temps.
D’un point de vue organisationnel, vous devez définir précisément quels sont les mails concernés par la réponse automatique, et quelle est la tolérance aux erreurs (faux positifs et faux négatifs). Le risque le plus élevé est d’ignorer certains mails et de générer de la friction client.
D’un point de vue scientifique, vous devez définir un mécanisme d’abstention de réponse automatique en cas de doute ou en cas d’intention multiple (demande d’attestation et de remboursement par exemple). L’incertitude du modèle permet alors de nourrir ce mécanisme. Par ailleurs, les types de mails peuvent évoluer d’une année sur l’autre, ou d’un périmètre à un autre, avec des volumes de données labellisés insuffisants. L’adaptation de domaine [11] permet d’ajuster votre modèle à différents segments aux labels inégaux (langue, période de l’année). Le monitoring doit se faire sur la base des relances émises par les clients.
D’un point de vue technologique, le modèle doit pouvoir répondre en temps réel à des mails qui arrivent au compte-goutte. Cela nécessite donc de packager le modèle et de le déployer sur un serveur, par exemple avec MLflow [12]. Qui plus est, l’automatisation rend indispensable la mise en œuvre des bonnes pratiques de CI/CD [13], que ce soit sur le prétraitement des mails ou sur le code de déploiement du modèle.
Oui, non et non : l’exemple de la prévision de demande
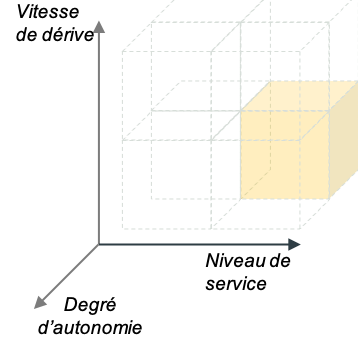

Vous êtes une entreprise de prêt-à-porter et vous devez prévoir jour après jour la quantité de vêtements à stocker dans vos entrepôts disséminés sur tout le continent. Les prévisions du modèle impactent directement les stocks et donc le chiffre d’affaires. Dans votre stratégie, vous avez un réseau de validation et d’ajustement manuel des prédictions à la maille locale qui prend en compte des considérations spécifiques de transport, de prestataire, de territoire.
D’un point de vue organisationnel, le rythme soutenu de production déplace la responsabilité du modèle vers la DSI. La mixité des équipes tant sur le plan Data Science que Data Engineering va vous permettre d’être réactif et d’assurer une bonne réactivité en toutes circonstances. Les prédictions de vos modèles sont fréquentes mais doivent systématiquement être validées par un expert. Cela va vous permettre de construire votre base de données labellisées – un véritable trésor pour la modélisation – qui doit être stockée méthodiquement et exploitée facilement.
D’un point de vue scientifique, la temporalité et la saisonnalité des données sont modélisables via des approches en séries temporelles [14]. C’est plutôt la diversité géographique et de périmètres qui devra être affinée, avec plusieurs modèles spécialisés à maintenir. La difficulté de maintenance s’en trouve alors augmentée, et les techniques d’arbre de défaillance [15] vous aideront à accélérer la détection et la résolution des problèmes. Les modèles simples, robustes et intelligibles [1] vous faciliteront grandement la vie.
D’un point de vue technologique, la multiplicité des sources de données, de modèles et de leurs prétraitements doit rendre évidente la bonne mise en place des méthodes CI/CD [13]. Cela concerne notamment le versioning [12] de modèles et les tests unitaires [7]. L’impact business étant important, il est difficile de faire l’économie d’un A/B testing [9], qui s’applique particulièrement bien au cas des séries temporelles (shadow deployment).
Oui, non et oui : l’exemple de la censure automatique d’images
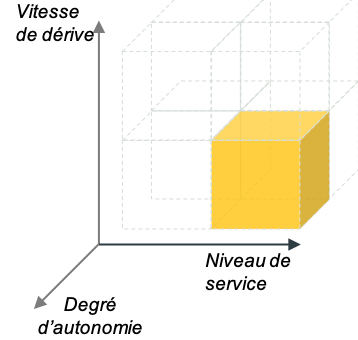

Vous êtes une entreprise du web spécialisée dans la modération de contenu photographique (ou même textuel). Vous devez censurer ou retarder la publication de contenu sur les réseaux sociaux ou sur des boutiques en ligne en temps réel et sur des grands volumes. Les concepts censurés sont cependant bien identifiés et stables dans le temps (pornographie, violence).
D’un point de vue organisationnel, vous êtes en train de minimiser votre risque réputationnel ou celui de votre client. Votre retour sur investissement va se mesurer directement au nombre de faux positifs (censure injustifiée, friction client) et de faux négatifs (contenu interdit non censuré, scandale [16]). Mais la quantification en euros de ce risque n’est pas triviale et va résulter d’un effet d’accumulation sur du long terme. La possibilité de désactiver l’utilisation du modèle IA et de basculer sur un fonctionnement manuel peut représenter un filet de sécurité. Là encore, le niveau de service élevé plaide pour une mixité réelle entre les équipes de modélisation, de mise en production et métier.
D’un point de vue scientifique, vous allez devoir jouer sur la taille de votre jeu de données (dans les limites imposées par votre infrastructure de calcul) et sur le débiaisage [17] de vos sources (biais ethniques, culturels, sexistes). L’intelligibilité [1] et l’analyse manuelle d’erreurs vous permettront de nuancer et rééquilibrer votre jeu de données, en ajoutant éventuellement une surcouche de détection de cas particuliers pour traiter certains cas spécifiques (art). Par ailleurs, la diversité des modes de prises photographiques incite à réaliser une adaptation de domaine [11] pour certains supports (par exemple écart de qualité entre jeu d’entraînement web et données de prédiction sur mobiles).
D’un point de vue technologique, vous avez tous les éléments pour réaliser des campagnes d’A/B testing [9] de qualité. La gestion du risque réputationnel vous impose de pouvoir réaliser un rollback [12] de votre modèle très rapidement en cas de scandale issu d’une mise à jour hasardeuse.
Oui, oui et non : l’exemple de la détection de fraude
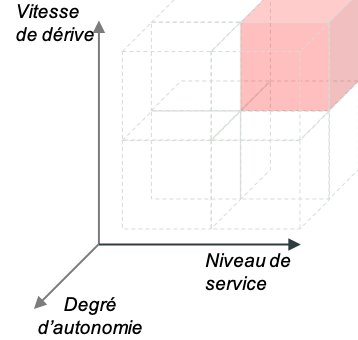

Vous êtes une banque et vous devez détecter des fraudes [18] sur les transactions de vente à distance en très grand volume. Vous avez une contrainte de réactivité très forte (inférieure à 10 millisecondes) pour bloquer une transaction suspecte. Les fraudeurs sont dynamiques et adaptent sans cesse leur stratégie pour contourner le modèle de fraude. Pour éviter les récidives, vous avez déployé une équipe d’experts en sécurité chargés d’enquêter sur les transactions bloquées : en interrogeant les clients concernés, ils peuvent procéder à un blocage de la carte bleue.
D’un point de vue organisationnel, ce sont les experts en sécurité qui ont une compréhension fine des scénarios de fraude et ce sont eux qui ont la responsabilité du modèle de détection. Ce sont donc eux les porteurs du projet. Le frein principal au cycle d’adaptation du modèle est l’acquisition de données labellisées, nécessairement en nombre limité au vu du volume de transactions. La sollicitation automatique du client par SMS dès qu’une transaction sur sa carte bancaire est bloquée permet de faire remonter plus de labels plus rapidement, le tout avec une gêne client négligeable par rapport à la gêne occasionnée par la fraude.
D’un point de vue scientifique, il y a un double enjeu d’adaptation rapide d’une part, et d’intelligibilité d’autre part. L’adaptation peut être réalisée par des techniques d’apprentissage adaptatif [19] issues du stream mining [20], et leur efficacité va être conditionnée au délai d’acquisition de la donnée labellisée. L’intelligibilité [1] va permettre d’identifier et de recouper des scénarios de fraude et de faciliter les investigations des experts sécurité.
D’un point de vue technologique, il s’agit de bien roder la mécanique de feature engineering online [7] (par exemple l’agrégation de données de transaction). En effet, le code de feature engineering sur le jeu d’entraînement (en batch) est nécessairement différent du code de feature engineering de déploiement (en stream), et pourtant les deux codes doivent calculer exactement la même chose. Par ailleurs, il est nécessaire de réaliser un versioning [12] exhaustif des modèles employés pour nourrir une banque de modèles potentiels et être capable de s’adapter aux stratégies de fraudes récurrentes (mais imprévisibles).
Oui, oui et oui : l’exemple des enchères publicitaires en ligne
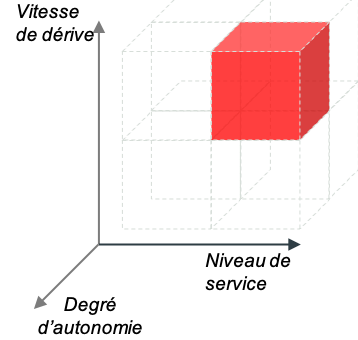

Vous êtes une entreprise du web spécialisée dans la publication de bannières publicitaires en ligne ou sur les applications de smartphones. Vous avez un fort enjeu de réactivité par rapport au temps de chargement de la page (inférieur à 20 millisecondes). Les publicités évoluent en permanence et vous luttez sans cesse contre l’effet d’accoutumance. La publicité est poussée sur la page sans aucune validation humaine.
D’un point de vue organisationnel, vous devez réactualiser sans cesse vos modèles et les redéployer immédiatement. Pour gagner en fluidité, vous abattez la frontière entre Data Scientistet Data Engineer et ne vous entourez que de profils pluridisciplinaires [21]. De plus, vous devez nécessairement envisager un système d’astreinte pour limiter les pertes financières en cas de problème.
D’un point de vue scientifique, vous ne pouvez faire l’économie de modèles adaptatifs [20]. Autrement dit, vous devez coupler monitoring de performance et ré-entraînement de modèles de manière automatique. L’adaptation va consister à optimiser votre jeu d’entraînement et votre expérience passée pour trouver le meilleur modèle à l’instant t. De même, vous avez tout intérêt à maintenir une banque de modèles et à les mettre en compétition permanente dans un processus d’A/B testing [8] généralisé et automatisé.
D’un point de vue technologique, vous pouvez miser sur un déploiement mondial facilité par une infrastructure cloud. 80% de vos problèmes sont dus à un manque de robustesse de votre chaîne de traitement. Votre modèle économique consiste à capitaliser sur tous les problèmes rencontrés [22] pendant le cycle de vie et à automatiser leur détection et leur résolution pour réduire le coût de maintenance. A ce titre, vous êtes intransigeant sur les bonnes pratiques CI/CD[13] et sur les tests unitaires [7] de qualité de données [8], de code, de modèle et surtout d’infrastructure.
Et ensuite ?
Le cycle de vie organise une multiplicité de solutions technologiques et scientifiques en un processus d’entreprise orienté production.
Bravo ! Vous avez identifié votre cycle de vie des modèles ! Si vous êtes capable de répondre à ces trois questions pour votre cas d’usage, vous avez déjà fait la moitié du travail [23] ! En pratique, vous pouvez d’ores et déjà réfléchir à l’organisation de votre cycle de vie [2] et à son implémentation technique [3].
En définitive, il n’existe pas de solution unique et universelle au cycle de vie des modèles. Il existe cependant des pratiques et des technologies qui permettent d’en aborder les points saillants. Le cycle de vie se définit alors comme l’organisation d’une multiplicité de solutions technologiques et scientifiques en un processus d’entreprise spécifique.
Quantmetry sort son nouveau livre blanc, IA en production [1], disponible gratuitement.
Références
[1] Livre blanc IA en production, par Quantmetry
[2] Projet IA : votre kit de survie pour la mise en production
[3] En route vers le cycle de vie des modèles !
[5] Targeted Review of Internal Models (TRIM)
[6] Embrace Randomness in Machine Learning
[7] The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
[9] Six Strategies for Application Deployment
[10] La gouvernance de la data, cette aventure humaine
[11] An introduction to domain adaptation and transfer learning
[13] Continuous Delivery for Machine Learning
[14] Les prévisions probabilistes avec DeepAR
[16] Facebook censure La Liberté guidant le peuple
[17] Quand l’intelligence artificielle s’attaque à la fraude : le problème des biais de sélection
[18] Comment s’adapter à l’évolution de la fraude ?
[19] Why Machine Learning Models Crash And Burn In Production
[20] A survey on concept drift adaptation
[22] Ongoing Model Maintenance
[23] Building machine learning products: a problem well-defined is a problem half-solved