

Comment industrialiser une solution IA grâce à une interface web personnalisée ?

Nous avons été missionnés par un acteur industriel majeur pour créer un algorithme d’aide au diagnostic afin d’accélérer ses travaux de maintenance. Il s’agit d’un algorithme d’identification de la cause des pannes, basé sur un réseau Bayésien, permettant d’assister les techniciens dans leurs opérations quotidiennes.
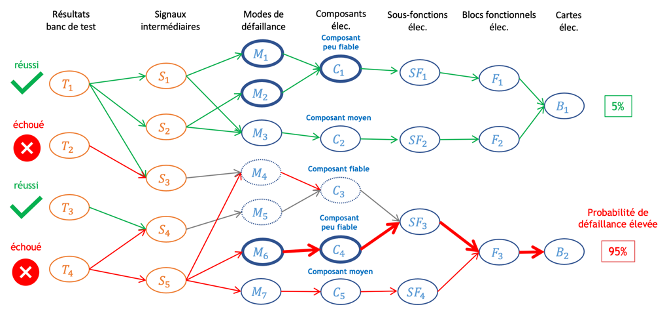
Ce projet a démarré en 2018 et a connu plusieurs phases successives d’exploration, mais n’avait jusque lors atteint la mise en production pour diverses raisons. Cette année, nous avons enfin franchi cette étape et mis l’application dans les mains des utilisateurs finaux, qui l’utilisent quotidiennement, démontrant chaque jour un peu plus sa valeur.
Nous allons vous présenter dans cet article les choix qui ont permis de lever les différents blocages et donc au projet d’aboutir.
I. Le contexte et les problèmes rencontrés
Au début de l’année, nous avions fini le POC : l’algorithme fonctionnait sur des cas tirés de la vie réelle, et une interface basique servait de prototype sur le réseau industriel du client. Plusieurs points bloquants empêchaient cependant le passage à l’échelle et l’utilisation quotidienne du produit.
Le déploiement de l’application représentait une première typologie de problèmes : l’algorithme n’était pas packagé, il devait être lancé depuis PyCharm et ne fonctionnait que sur un seul ordinateur présent dans l’atelier du client. Une série d’opérations « complexes » en lignes de commandes devait être réalisée à chaque lancement du produit par des utilisateurs sans background d’informaticien. De plus, le réseau du client n’était pas connecté à internet. Chaque mise à niveau du code impliquait un déplacement sur place et de multiples opérations manuelles avec un haut risque de régression. Nous avons décidé, dans notre nouvelle approche, de commencer l’industrialisation par un Sprint 0, prenant en charge tous ces aspects.
La cohérence architecturale et le choix des technologies formaient un second cluster d’éléments bloquants : la solution avait été implémentée en Python, incluant à la fois le front-end, le back-end et l’algorithme, le tout packagé par du Django. L’ensemble était assez monolithique : des fonctions très longues et complexes ainsi que des bases de données structurées mal designées contenant peu de tables avec trop d’informations sous différents formats. L’absence complète de tests unitaires faisait régulièrement apparaître des régressions et les rendaient difficiles à corriger. Enfin chaque membre de l’équipe initiale travaillait seul sur son périmètre, et la rotation des profils au fil des années freinait fortement l’industrialisation du projet. Nous avons donc décidé de ne garder que le code Python de l’algorithme et de refondre toute l’application.
Enfin, nous rencontrions également des problèmes avec l’interface graphique : le prototype présentait l’algorithme dans une interface web réalisée en Django. L’interface n’avait pas été suffisamment priorisée et souffrait d’une mauvaise ergonomie en plus d’un aspect graphique vieillissant et peu soigné. Le parcours utilisateur n’avait pas été challengé en détail par le client qui se satisfaisait d’une « solution qui marche ». Les templates HTML utilisés présentaient en outre d’énormes redondances et leur maintenance était coûteuse en plus d’être source d’erreurs. Nous avons donc décidé de partir d’une page blanche concernant l’IHM et de refaire celle-ci de zéro en Angular.
Dans les parties suivantes, nous allons nous concentrer sur ces trois choix de remédiation apportés au projet : le Sprint 0, l’APIsation du modèle et la refonte du front-end en Angular.
II. Sprint 0 et mise en production
Avant d’attaquer le développement des fonctionnalités, nous avons convenu avec le client que nous procéderions à un Sprint 0. Le but de ce sprint est de mettre en place toute l’architecture cible de la solution sur l’infrastructure du client. Nous avons donc créé une application vide en Angular et FastAPI. Le front-end ne contenait qu’un seul composant appelant l’unique route du back-end, connecté aux bases de données. En bref, nous affichions « base de données ok » dans une page blanche.
Nous en avons également profité pour mettre en place une chaîne d’intégration continue. Le code était donc testé unitairement, de façon automatique, et buildé en un docker unique contenant l’ensemble de l’application front et back. Le déploiement automatique n’était pas possible car le réseau industriel du client n’était pas connecté à internet. Le nouveau système de déploiement implique donc toujours une opération manuelle, réalisée à l’aide d’un script. Cela a fortement réduit les régressions lors des mises à niveau de la nouvelle application.
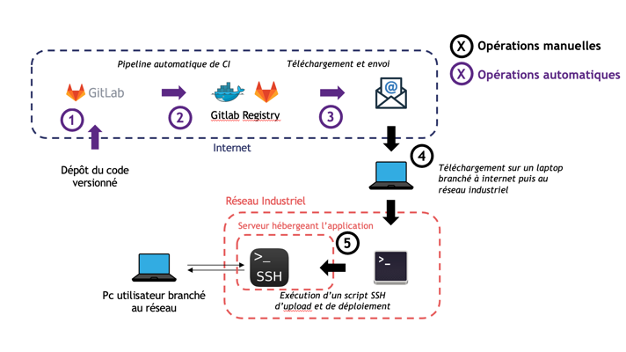
Nous avions prévu 4 semaines de Sprint 0, mais celui-ci s’est finalement étiré sur 8 semaines calendaires ; en effet les équipes du client, nécessaires pour effectuer certaines tâches sur l’infrastructure, n’avait pu obtenir suffisamment de disponibilité . Nous avons fait le choix de ne pas démarrer les développements avant d’avoir résolu les points de blocages structurants, identifiés pendant ce laps de temps. Ainsi, au début de la phase de Build, nous étions prêts à nous concentrer sur le développement des fonctionnalités. Le traitement de ces points bloquants au plus tôt du projet nous a sûrement évité de rencontrer des écueils critiques par la suite, facilitant énormément l’industrialisation.

III. APIsation de l’algorithme
Notre nouvelle architecture applicative nous a permis de découper les responsabilités entre les modules. Nous en distinguions quatre : le front-end, le back-end, le modèle et les bases de données. Il nous a fallu redéfinir clairement les interfaçages entre les différents modules. Les interactions entre front-end et back-end en FastAPI ont été basées sur un contrat d’interface construit itérativement en début de chaque sprint.
Chaque fonctionnalité, comme le calcul d’une probabilité de défaillance, est implémentée à travers un endpoint HTTP via une architecture REST : elle est dotée d’une URL, d’une méthode d’appel, de paramètres et d’un contenu. Cette méthode permet d’interfacer différents langages, ici du Javascript avec du Python. Elle induit également une clarification des rôles et responsabilités entre front-end et back-end pour chaque fonctionnalité.
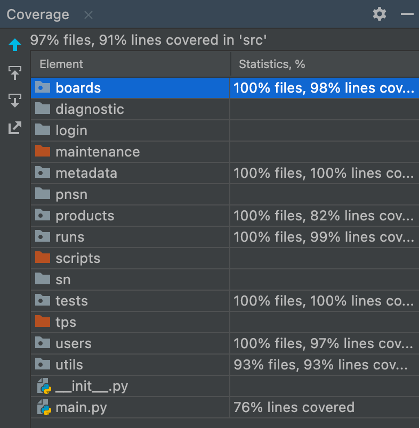
Les fonctions sont unitaires, limitées à une dizaine de lignes, et n’ayant pour la plupart qu’une seule responsabilité. Cela a facilité la mise en place de tests unitaires, avec une couverture de test supérieure à 90% sur le back-end. Pour mettre en place cette couverture nous avons utilisé le module unittest et le concept de mock pour garantir l’absence d’effet de bord. Le périmètre du modèle, hérité de l’ancienne version de l’application, n’a pas été testé et représente une dette technique identifiée.
En plus de ces tests, nous avons suivi quelques autres bonnes pratiques : typage via les modules typing et PyDantic, format PEP8 grâce au module black, décomposition des fichiers en une arborescence reflétant l’architecture REST. Suite à la mise en place de ces bonnes pratiques, nous n’avons observé aucune régression entre deux déploiements, toutes les anomalies étaient détectées durant la phase de développement.
IV. Refonte du front-end en Angular
Nous avons fait le choix de recoder entièrement le front-end en Typescript dans le framework Angular. L’inconvénient de ce choix est que ce langage est moins courant dans le domaine de la data science, mais a pour avantage d’être plus adapté au développement d’applications web. Malgré la barrière à l’entrée, Angular a permis d’améliorer l’ergonomie et de simplifier grandement le code.
Angular vient avec une bibliothèque de composants sur étagère, ergonomiques et rapidement utilisables. Il est également très facile de créer des composants personnalisés dérivés de ceux existants. La réutilisation des composants augmente l’homogénéité en termes d’interface et d’expérience utilisateur. L’ensemble de ces facteurs permet d’améliorer grandement l’ergonomie globale de l’application, et comme nous le verrons plus tard l’adhésion des utilisateurs.
Angular rend aussi le code plus modulaire, donc plus maintenable. En effet celui-ci repose sur le concept de composants qui peuvent être affichés sur les pages HTML de l’application et qui disposent d’un accès aux endpoints du back-end à travers des services. Cette structure en composants unitaires évite la duplication de code, ce qui était un problème majeur dans la version précédente du front-end implémentée via Django.
A l’image du back-end, la mise en place unitaire de fonctions et de tests a permis d’éviter les régressions et de faciliter le développement de nouvelles fonctionnalités. Suite à cette expérience, nous recommandons fortement l’usage d’un langage adapté (React, VueJS, Angular, …) pour le développement d’applications web.
V. Retours utilisateurs
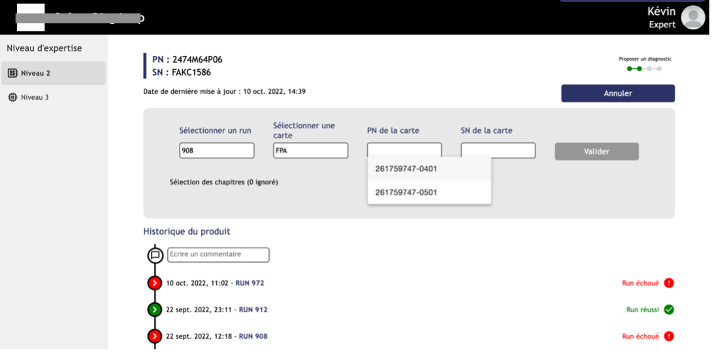
Notre approche vise à mettre dans les mains de l’utilisateur final une application utile le plus tôt possible dans le projet, l’enjeu étant de rendre service à l’utilisateur en lui apportant des services utiles à son quotidien pour qu’il puisse à son tour nous rendre service grâce à des retours pertinents et personnels. Nous avons livré la première version en production de l’application au bout de trois mois de projet, puis avons effectué une série de trois sprints de développement directement basés sur les retours en condition réelle de nos utilisateurs.
Cela permet d’intégrer les tests de l’application au quotidien des équipes et ainsi de limiter le coût en temps de cette phase de recette. L’autre intérêt des conditions réelles est de permettre une plus grande immersion des utilisateurs finaux : l’application s’insère naturellement dans leurs process quotidiens, ce qui permet plus facilement des retours porteurs de valeurs pour le métier. Enfin cela nous garantit également d’éviter des fonctionnalités qui se seraient avérées inutiles à l’usage.
Comme pour chaque projet, nous avions un sponsor / utilisateur clé porteur de l’application. Dans les phases précédentes, nous nous étions concentrés sur son usage sans réussir à atteindre les autres techniciens sur site. Grâce aux décisions de remédiations évoquées plus tôt, nous avons réussi dès le début de la phase de run à impliquer quatre personnes dans leurs activités quotidiennes. La forte adhésion des utilisateurs a été un accélérateur important pour le sujet du projet : ils sont nos meilleurs ambassadeurs auprès des instances décisionnelles du client.
Conclusion
S’il n’y avait qu’une chose à retenir, c’est qu’il est crucial de savoir dire non à l’impératif de résultats à court terme. Ainsi on se permet de mettre en place des fondations saines et de se concentrer sur les fonctionnalités importantes pour le métier : à iso-budget, il vaut mieux faire moins mais mieux.
Les membres de l’expertise AI Product conçoivent, développent et industrialisent des produits IA de plus en plus complexes (Web et mobile apps, API, etc.) en s’appuyant sur une approche « ROIste ».

Head of AI Product
Fullstack developper et data scientist, je mets mon expérience software au service de la data. Je promeus des méthodes agiles et centrées sur l'utilisateur final auprès de mes équipes pour apporter toujours plus de valeurs à mes clients.

Expert Time Series
Docteur en mathématiques appliquées à la physique statistiques, j’aborde aujourd’hui les problématiques de data science sous les angles scientifiques, techniques et métiers. J’ai un faible pour les modèles Bayésiens, les séries temporelles et l’IA de confiance !