

Le Pruning de réseaux de neurones en Computer Vision

A l’heure où les réseaux de neurones sont de plus en plus volumineux [1], peut-on réellement continuer de croire en la capacité de nos machines à les faire tourner ?
Les backbones généralement utilisés en Computer Vision ont une taille de l’ordre de ~100Mo (figure 1). Or, à un backbone il convient de connecter une ou plusieurs couches fully connected pour obtenir un réseau de neurones capable de traiter la tâche qui lui est impartie (classification, segmentation, détection d’objet). Pour une problématique d’Object Detection par exemple, le Region Proposal Network qui suit peut facilement donner un modèle dont la taille totale avoisine 1Go (comme RetinaNet).
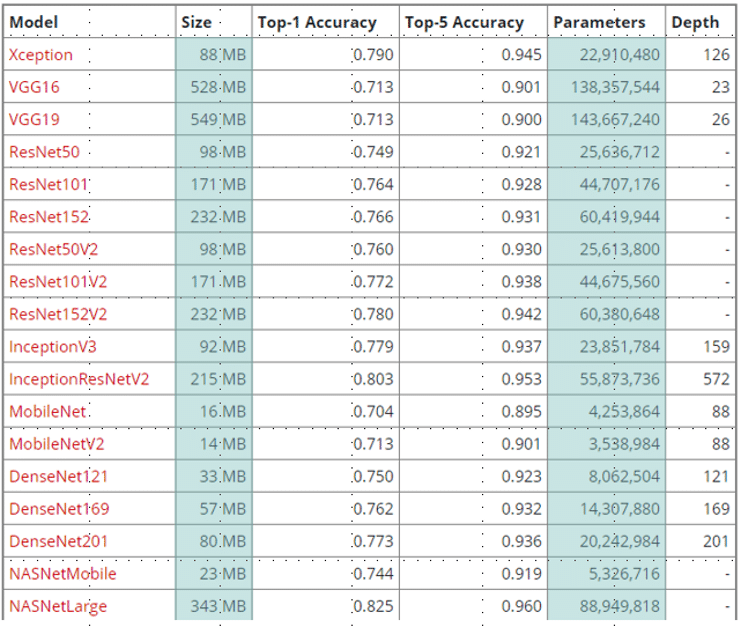 Quelques exemples de backbones pouvant être utilisés en Computer Vision
Quelques exemples de backbones pouvant être utilisés en Computer Vision
En quoi le taille d’un réseau peut poser problème
En 2017, Apple lance officiellement Face ID, son système de déverrouillage par reconnaissance faciale sur ses smartphones. Si des technologies de ce type existaient déjà sur le marché, la particularité de l’application Apple résidait ailleurs : pour la première fois un système de reconnaissance faciale sur mobile fonctionnait sans avoir besoin d’échanger des informations avec le Cloud.
Les systèmes de reconnaissance faciale reposent sur un (ou plusieurs) réseaux de neurones volumineux. L’inférence requiert donc de nombreux calculs, lesquels ne peuvent s’effectuer qu’à condition a priori de disposer d’une puissance de calcul qui excède largement celle d’un smartphone. Ainsi les solutions qui précédaient Face ID avaient pris le parti de déployer leurs algorithmes sur le Cloud, bénéficiant de ressources potentiellement illimitées et assurant à leurs utilisateurs un résultat rapide et performant, pourvu qu’ils disposent d’une connexion au réseau.
Seulement, avec toutes les IA que nous sommes destinés à utiliser dans l’avenir, peut-on réellement se permettre de compter sur le Cloud en toutes circonstances ?
Que se passe-t-il si le réseau n’est pas disponible ? Ou bien que l’IA soit exécutée par trop de personnes en même temps et qu’une latence se mettrait en place ?
Plusieurs questions pour lesquelles le problème disparaitrait si nous pouvions embarquer facilement nos IA.
Le Pruning de réseaux de neurones
L’intuition première face à un réseau trop « lourd » que l’on doit embarquer consiste tout simplement à l’alléger.
Définition
Le pruning, ou élagage en français, c’est l’idée de réduire la taille d’un réseau de neurones, tout en minimisant la perte de performance.
La performance étant définie par :
– Les métriques classiques en Machine Learning
– Le temps d’inférence
– Le nombre de paramètres du réseau
– Etc..
Méthodes pour y parvenir
(M1) Mettre à 0 certains paramètres
(M2) Mettre à 0 des neurones entiers
Stricto sensu, on ne « coupe » pas les branches comme le suggère la définition, seulement c’est la conséquence de la mise à 0 des paramètres qui donne une suppression in fine.
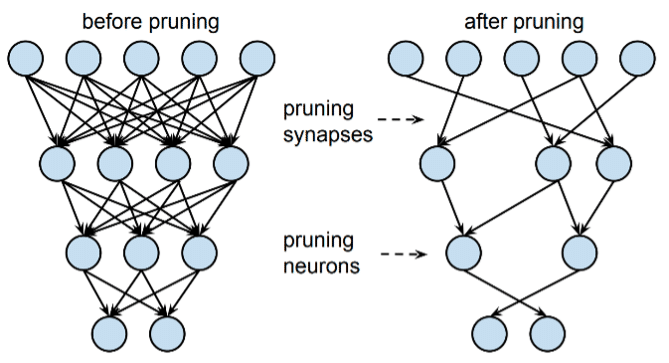
Illustration des deux méthodes de pruning
Attention : Mettre à 0 des neurones entier est différent du Drop Out
Le Drop Out est une méthode visant à diminuer l’overfitting et s’appliquant durant l’entraînement d’un réseau de neurones. Ainsi le Drop Out n’a aucun impact sur la structure du réseau en propre. De plus, le Drop Out agit aléatoirement, alors que la méthode (M2) sélectionne les neurones les moins importants.
Par la suite, nous allons présenter deux implémentations de pruning :
- L’API native de Keras [2] [3] – 2018
- MorphNet, projet de Google établi sur Tensorflow [4] [5] – 2019
Avant de présenter ces méthodes en détail, voici quelques intuitions que l’on peut avoir :
- Étant une étape supplémentaire dans la conception d’un modèle, il est logique de prévoir un coût au pruning.
- Les deux approches qui vont être introduites sont un pruning pendant l’entraînement. La durée d’entraînement en sera donc allongée.
Pour les exemples, on utilisera un problème de classification d’images, avec cifar10 par exemple (images 32×32). - Faisant appel à la méthode (M1) de pruning, les approches proposées par Keras et MorphNet mettent à 0 des paramètres. Avec un entraînement suffisamment poussé – et dénué d’overfitting -, un paramètre est au pire inutile dans un modèle. On peut donc s’attendre à ce que la performance (en termes de métriques de Machine Learning) du réseau élagué soit inférieure à celle du réseau de base. Mais nous verrons en réalité que ce n’est pas nécessairement le cas, et que cette inégalité supposée peut même s’inverser dans les faits.
Méthode 1 : API Keras
Fonctionnement
- Cette méthode creuse la matrice des paramètres du réseau c’est-à-dire annule certains de ses poids, et ce durant l’entraînement. La proportion de 0 est fonction d’un pourcentage qu’on lui a indiqué.
- Pour choisir les bons paramètres à nullifier, la méthode trie les paramètres par ordre d’importance.
Un paramètre est jugé important s’il induit souvent une activation. Cette méthode de sélection est la plus connue dans la littérature 1. - Pour appliquer cette mise à 0, l’API utilise des masques. C’est-à-dire des matrices booléennes (donc dont les coordonnées valent 0 ou 1) de mêmes tailles que l’objet que l’on veut traiter. Ici ce sont des matrices de paramètres. L’output des paramètres qui auront été déterminés comme inutiles est bloqué par le masque, et ceux-ci ne seront pas mis à jour lors de la back propagation, convergeant ainsi vers 0 par une normalisation L2.
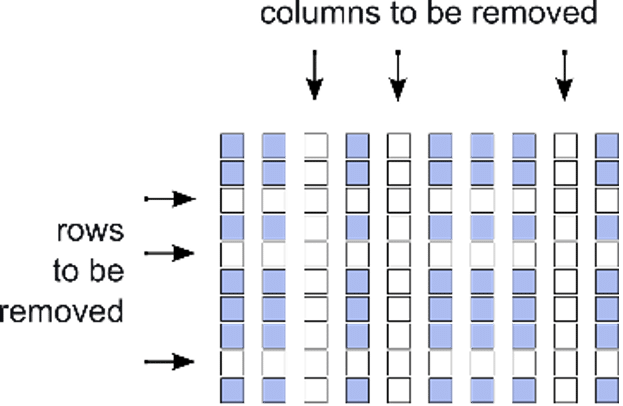
Illustration de l’issue d’un masking
Fonctionnement de l’API
- Pour appliquer les masques sur les couches, il faut les rendre « élagables ».
Cela se fait simplement comme suit par exemple :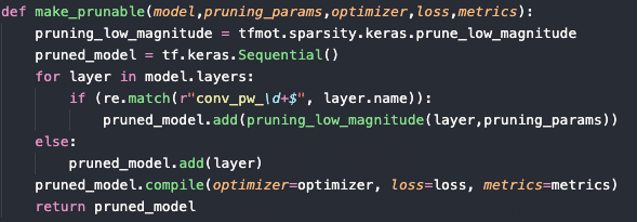
Code pour rendre toutes ses couches de convolutions « élagables »
- C’est la fonction pruning_low_magnitude de l’API qui est au cœur du processus. C’est elle qui applique les masques et détecte les paramètres moins importants.
Finetuning
Le pruning s’effectue à travers un pruning schedule, soit :
- Une proportion de 0 par laquelle commencer
- Une proportion de 0 à laquelle vous voulez finir
- A quelle epoch on souhaite enclencher le pruning

Le pruning schedule
Finalement
Le modèle finalement obtenu est dit « sparse », c’est-à-dire que la proportion de paramètres non nuls est devenue beaucoup plus faible. Cela permet alors de compresser le modèle.
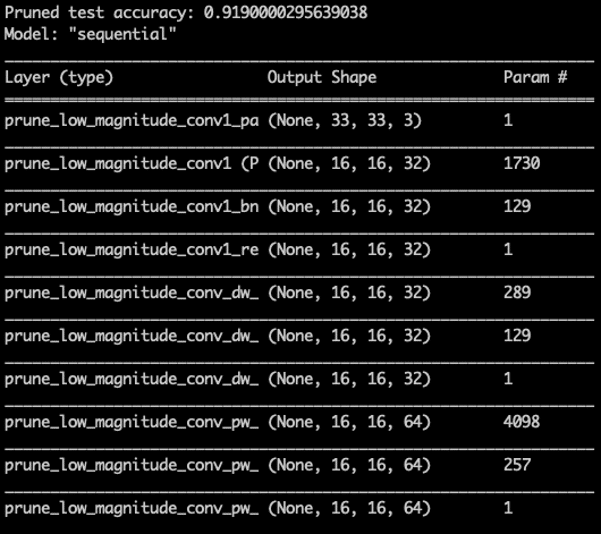
Allure d’un MobileNet après application des masques par l’API Keras
Résultats
Les résultas de ce pruning sont plutôt satisfaisants.
Pour des pruning de ~70% la perte de précision est quasi nulle sur la plupart des problématiques classiques.
On obtient donc facilement des modèles 3x plus petits, mais tout aussi précis !
![]()
Poids d’un MobileNet avant et après pruning
Méthode 2 : MorphNet
Similarité avec la méthode Native de Keras
- Cette méthode creuse également la matrice des paramètres durant l’entraînement.
- Cependant pour ce faire, cette méthode fait appel à une régularisation Lasso Group ajoutée dans la fonction de loss du modèle. Le Lasso Group opère une régularisation par la norme L1 sur des partitions de paramètres, évaluant ainsi l’importance de groupes de paramètres côte à côte, et non les paramètres seul à seul. L’avantage de cette méthode est que lorsqu’un groupe est mis à 0, pour peu que le groupe soit d’assez grande taille, cela peut être l’input tout entier d’un filtre qui sera élagué, et donc le filtre lui-même par extension.
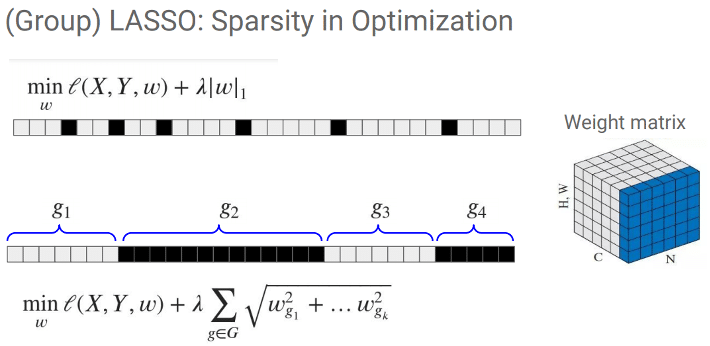
Illustration de la régularisation employée par MorphNet [4]
Différences
- Pour l’instant, MorphNet est axé sur les couches de convolutions
- A l’inverse de l’autre méthode : MorphNet complexifie la Loss du modèle (durant l’entraînement) en ajoutant un paramètre de régularisation comme on a vu.
- Il est nécessaire aussi de choisir une métrique sur laquelle cette régularisation va s’établir en évaluant les couches de paramètres :
- Les FLOPs (nombre d’opérations)
- La taille du modèle (nombre de paramètres)
- La latence, combinaison des FLOPs et de la taille du modèle, et fonction du hardware
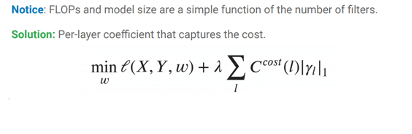
Formule de la loss dans MorphNet [5]
Plus-value et mode d’emploi
- Alors que les filtres moins importants subissent un pruning, les filtres importants sont eux multipliés, réallouant alors de la mémoire pour gagner en précision.
- Par conséquent, MorphNet est une succession de suppressions et de créations de filtres.
- A chaque fin d’itération, une architecture élaguée est sauvegardée.
- Elle doit alors subir un entraînement from scratch, car la loss de la régularisation MorphNet n’est pas la loss associée à l’entraînement du réseau, étant donné qu’on y ajoute une terme de pénalisation pour la régularisation.
- Enfin, si le pruning n’est pas stable (explosion du nombre de filtres, suppressions de tous les filtres), il faut calibrer le paramètre de régularisation regularizer_threshold de MorphNet et le learning rate très certainement.
Jeu de paramètres utilisés pour une exécution de MorphNet
Exemple de Résultat de pruning MobileNet par MorphNet
- Les résultats d’itérations sont très progressifs et très stables. La régularisation est presque parfaitement calibrée puisqu’on peut récupérer notre modèle à de très nombreuses étapes de pruning tant l’élagage est stable (et pouvant durer assez indéfiniment)
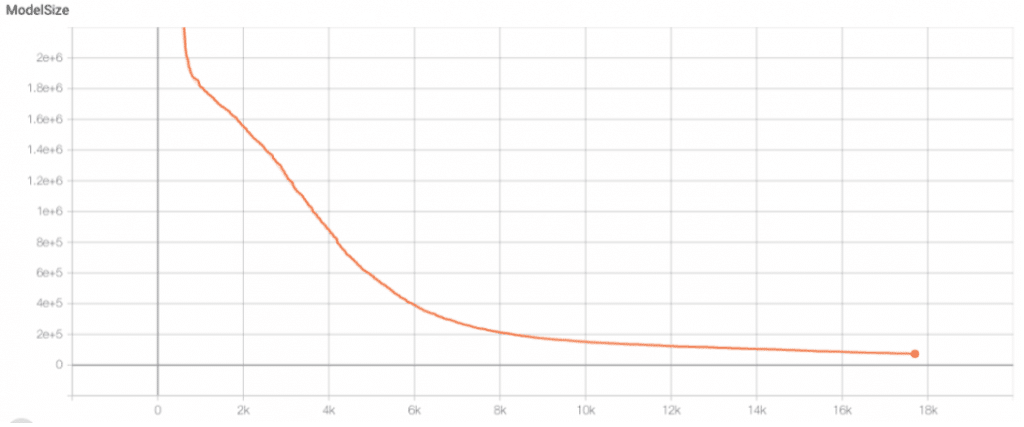
Évolution de la taille du modèle en fonction du nombre d’epochs
Étude des couches élaguées d’un MobileNet
Prenons un MobileNet (c’est un backbone classique en Computer Vision) et appliquons lui MorphNet dans le cadre d’une classification.
MorphNet élague de manière très graduelle et progressive les couches de convolutions. Ici à la 300eme epoch, il reste beaucoup de paramètres au MobileNet de base et on aurait encore pu poursuivre le pruning.
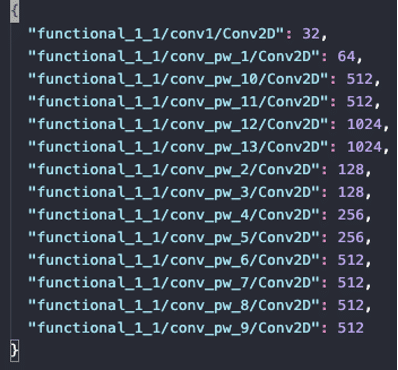
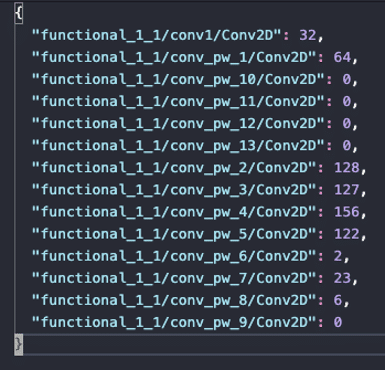
Évolution des filtres par couche entre l’original (à gauche) et l’élagué par MorphNet (à droite)
Études d’un autre cas : VGG16
Les résultats obtenus sont ici plus abrupts. Il y a fort à parier que le calibrage des hyper paramètres n’est pas parfait : il faudrait sans doute ajuster le learning rate. Le pruning opère de manière plutôt correcte néanmoins car la taille du modèle est bien décroissante. On remarque une stabilité autour des 900ème-1000ème itérations, puis un seuil nul atteint après 2500 itérations de pruning sur les couches de convolution.
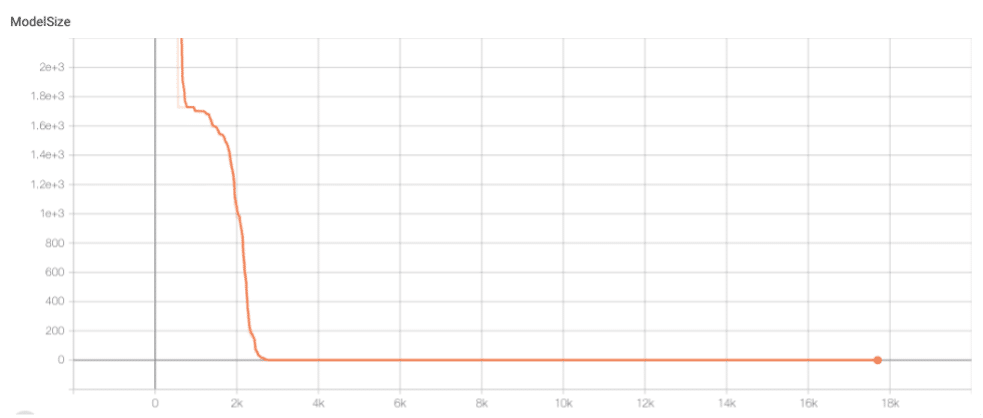
Évolution de la taille du VGG16 au cours de l’exécution de MorphNet
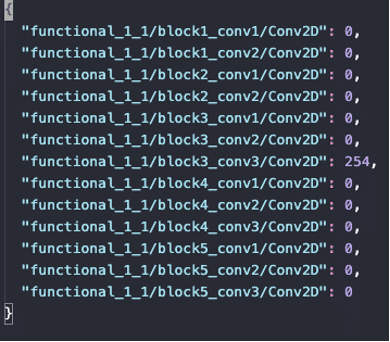
Couches d’un VGG16 après pruning
On constate finalement au niveau des couches que d’après MorphNet seule une couche de convolution suffisait à résoudre le problème de prédiction sur le dataset de cifar10. Cela peut paraître étonnant, mais ça ne l’est pas nécessairement : le problème de classification cifar10 n’est pas si ambitieux que cela et des réseaux de neurones peu profonds permettent d’obtenir déjà d’assez bonnes performances.
Résultats
Les résultats de ce pruning sont là aussi satisfaisants.
Pour des problématiques simplistes, MorphNet a bien formalisé l’inutilité d’autant de couches de convolutions et n’en laisse qu’une à la fin.
Une fois le réseau reconstruit en suivant le nombre de filtres indiqué par le pruning MorphNet, on obtient un modèle de 2Mo au lieu de 12Mo.
Conclusion
Quelle méthode adopter et quand ?
- Native Keras
- Les +
- Applicabilité : N’importe quel réseau pour peu qu’il soit construit via l’API Keras.
- Qualité du pruning : Très satisfaisant puisqu’on atteint bien la réduction souhaitée du poids du réseau, avec quasi aucune perte de précision.
- Implémentation : Facile
- Les –
- Fine-tuning : Facile d’accès mais peut être fastidieux.
- Les +
- MorphNet
- Les +
- Qualité du pruning : Plutôt satisfaisant. De plus MorphNet cherche le réseau idéal, avec choix du critère possible, et la condition d’arrêt n’existe pas vraiment.
- Fine-tuning : Facile d’accès.
- Les –
- Applicabilité : Nombre limité d’architectures. Ne prend pas en compte les architectures de détections d’objets par exemple.
- Implémentation : Difficile. Projet encore trop jeune, difficilement modulable et ne peut pas être installé via pip.
- En bonus : Sur le papier MorphNet est très prometteur, il combine le pruning et l’augmentation de la précision.
- Les +
Conclusion
En attendant que MorphNet atteigne un bon niveau de maturité et soit plus accessible, l’API Keras semble donc propice à une utilisation efficace.
Références
[1] Like a Bull in a China Shop… Or How to Run Neural Networks on Embedded Systems
[2] TensorFlow Pruning Comprehensive Guide
[3] TensorFlow Model Optimization Toolkit — Pruning API
[4] MorphNet GitHub
[5] MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
