

Le reinforcement learning et la conduite autonome : Nos essais sur AWS Deep racer

Nous vous proposons dans cet article une introduction au reinforcement learning. Nous illustrerons notre propos par un cas d’usage de conduite autonome par l’intermédiaire du service AWS Deep Racer. Ce service est un championnat mondial de voitures miniatures et autonomes. Il vise notamment à promouvoir l’accès à une branche du machine learning de plus en plus populaire : l’apprentissage par renforcement (Reinforcement Learning en anglais). Nous avons eu accès à une version bêta du service (à l’heure de l’écriture de ces lignes il n’est pas sorti en France) et pu soumettre un modèle lors de l’AWS Summit Paris.
Une introduction à l’apprentissage par renforcement
L’apprentissage par renforcement est défini comme l’apprentissage par un agent (un drone, Super Mario, une fourmis, etc) d’une séquence optimale d’actions dans un environnement totalement ou partiellement connu. Cette méthode s’attaque au problème de la planification (à la différence de la prédiction pour l’apprentissage supervisé classique).
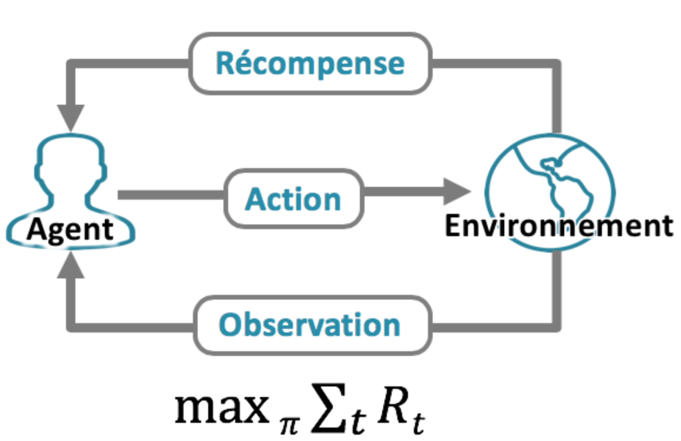
Illustration : Schéma de fonctionnement de l’apprentissage par renforcement. L’objectif est de maximiser la somme des récompenses obtenues au cours du temps
Cette réalisation d’une tâche séquentielle implique que l’on soit capable de simuler la réponse de l’environnement à des actions effectuées au cours du temps. Alors qu’un modèle de machine learning nécessite des données d’entrées statiques, un modèle d’apprentissage par renforcement a besoin d’un mécanisme permettant de générer de nouvelles données en fonction des actions choisies. Cette typologie de problème se distingue donc de l’apprentissage classique par l’existence d’une boucle de rétroaction entre un environnement et un agent implémentant le modèle (l’agent étant l’entité effectuant les actions dans l’environnement).
La récompense, concept central de l’apprentissage par renforcement
Comme énoncé précédemment un agent d’apprentissage par renforcement interagit avec un environnement pour réaliser une tâche. Cependant comment guider l’agent de manière à ce qu’il apprenne quelque chose ? Contrairement à l’apprentissage supervisé il n’y a pas de label stipulant qu’il fallait prendre telle ou telle action dans une situation donnée. En revanche on sait estimer si l’agent a réalisé la tâche qu’on lui a donné ou s’il s’est trompé. L’apprentissage par renforcement reflète donc un processus d’essais et d’erreurs qu’on applique naturellement dans l’apprentissage d’une tâche. Par exemple, tout le monde a appris à rouler à vélo après avoir souffert de chutes maladroites, ou en comprenant comment maîtriser l’équilibre avec l’accélération, tout en étant acclamé et encouragé par nos amis ou parents. On sait donc dire si une situation dans laquelle se trouve l’agent est bonne ou mauvaise sans avoir besoin de lui dire explicitement quelle action il aurait dû réaliser. Cette notion de bonne ou mauvaise situation est quantifiée par la fonction de récompense. En vérité la “vraie” quantité à optimiser est la somme des récompenses obtenues au cours du temps plutôt que la récompense instantanée. En effet une bonne action à court terme peut mener à une situation catastrophique (par exemple accélérer dans un virage si la récompense est la vitesse instantanée).
Également, le processus d’essais et d’erreurs est central en apprentissage par renforcement et est représenté par le “dilemme exploration/exploitation”. Ce dilemme stipule notamment que dans un environnement partiellement connu, on ne connaît pas avec certitude la meilleure action à effectuer et il faut donc quelquefois choisir une action dont le résultat est incertain et pas forcément celle qui amène à la récompense cumulée observée la plus grande.
Une illustration du dilemme exploration/exploitation (Source: UC Berkeley AI course slide, lecture 11.)
Les autres concepts prédominants
On vient de voir l’importance de la fonction de récompense pour le problème d’apprentissage par renforcement. Cependant d’autres quantités apparaissent naturellement pour traiter cette problématique :
-
- Les actions : Ensemble de ce que peut faire l’agent à chaque instant. Cet ensemble est souvent de taille finie pour des questions de simplification.
- Les états : Une “synthèse” de l’observation de l’environnement à un temps donné, utilisé par l’agent pour choisir une action.
- La stratégie : Ce qu’apprend l’agent, une fonction qui détermine l’action choisie en fonction de l’état observé.
- Episode : Il s’agit de l’ensemble des étapes ayant conduit à la réalisation d’une tâche par l’agent.
Pour plus d’informations sur le reinforcement learning, nous invitons le lecteur à lire cet article traitant du reinforcement learning dans les jeux-vidéos ainsi que cet article traitant de Alpha Zero, l’intelligence artificielle de Google Deepmind permettant de jouer à différents jeux de plateaux à un niveau inégalé (échecs, go et shogi).
Formalisation du problème d’apprentissage par renforcement pour Deep Racer
Maintenant que nous avons une meilleure compréhension de ce qu’est l’apprentissage par renforcement, essayons de transposer cette connaissance au cas d’usage “Deep Racer”.
L’objectif de la compétition est de faire le meilleur temps au tour sur un circuit. Il s’agit donc d’un contre la montre, ce qui rend le problème plus simple car il n’y a pas de voitures adverses à gérer. Le point clé de la compétition est la conception d’une fonction de récompense et la calibration des paramètres utilisés pour l’algorithme. La partie de Reinforcement Learning est gérée par l’environnement Amazon SageMaker tandis que la simulation de l’environnement est contenue dans le service Amazon RoboMaker. Les autres services utilisés sont S3 pour le stockage, et CloudWatch pour la visualisation et le stockage des logs et des métriques.
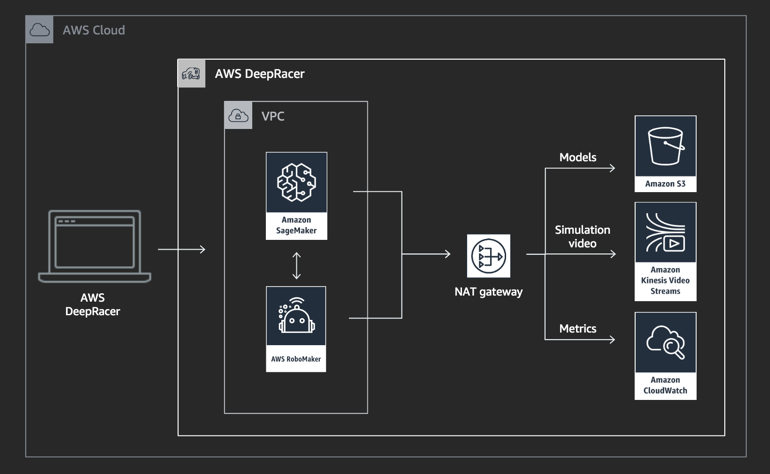
Architecture du service Deep Racer (source : AWS Deep racer)
Remarquons que la phase d’apprentissage est réalisé sur un simulateur (AWS “Robomaker”). La course en revanche est effectuée en condition réelle avec une vraie voiture miniature. Il existe donc en pratique une problématique de “domain adaptation” qui n’est pas traitée dans cet article.
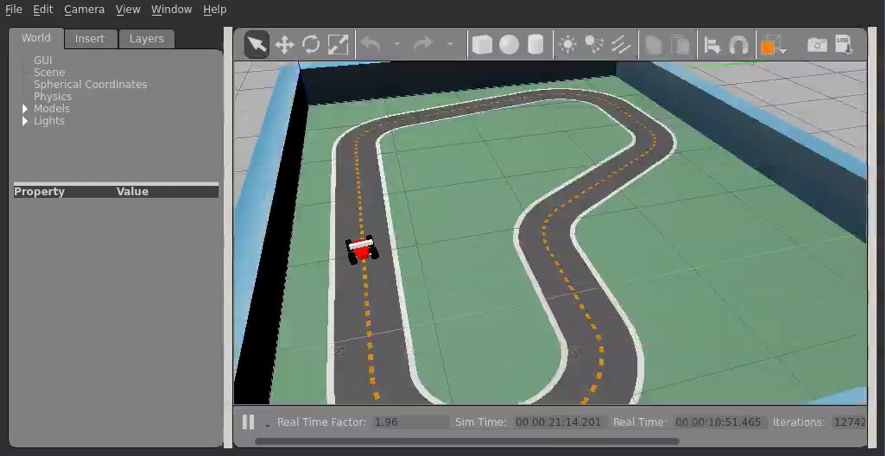
Illustration : Environnement d’apprentissage simulé par l’intermédiaire de AWS Robomaker
À chaque étape de la course, la caméra de la voiture capte une image de taille 160×120. Cela correspond à l’état de l’environnement. L’agent dispose d’un ensemble d’actions, e.g. virer à gauche ou à droite, donner une consigne de vitesse, avec lesquelles il peut interagir avec l’environnement, c’est-à-dire se déplacer. Dès qu’une action est faite l’agent passe à l’état suivant (la prochaine image de la caméra à l’instant t+1). L’agent continue sa suite d’états-actions appelée trajectoire jusqu’à atteindre un nombre maximal d’étapes (l’horizon) ou un état terminal représenté ici par une sortie de piste. Cela signe la fin d’un épisode et le début d’un autre.

Illustration : Exemple d’images captées par la caméra frontale de la voiture, entrée du modèle d’apprentissage par renforcement
Il s’agit d’un contre la montre. Il faut donc faire terminer à l’agent un tour complet de la piste le plus rapidement possible. Il faut donc inciter l’agent à produire ce comportement. Comment ? Grâce à la fonction de récompense bien entendu !
Création de la fonction de récompense pour Deep Racer
Le choix d’une bonne fonction de récompense est un des principaux leviers permettant la résolution d’une tâche. Celle-ci décrit comment l’agent devrait se comporter. Pour le cas de Deep Racer il s’agit d’un paramètre à définir par l’utilisateur.
Quelques critères permettent usuellement de guider le choix d’une bonne fonction de récompense :
- La récompense ne doit pas être trop “sparse” afin de faciliter l’apprentissage. Dans notre cas donner une récompense positive uniquement lorsque la voiture réussit à finir un tour est une mauvaise fonction de récompense, car la plupart du temps l’agent ne va rien recevoir et n’apprend donc pas efficacement.
- La récompense doit représenter réellement la tâche à accomplir. Il peut arriver qu’en optimisant le gain d’une récompense définie par l’utilisateur l’agent apprenne un comportement non souhaité. C’est ce qu’on appelle le phénomène de “Reward hacking”.
Un exemple drôle est celui du robot guépard qui apprend à courir retourné sur son dos (pour plus de détails voir ici). D’autres exemples célèbres de reward hacking peuvent être trouvés ici.
- Une récompense positive encourage l’agent à faire durer l’épisode le plus longtemps possible. A l’inverse une récompense négative encourage l’agent à terminer sa tâche le plus rapidement possible.
Nous avons privilégié l’utilisation d’une récompense plus encourageante que pénalisante. La seule récompense négative a été introduite dans le cas d’une sortie de piste, car il faut absolument l’éviter. Pour le reste nous nous sommes basé sur trois points principaux pour la récompense :
- Récompense positive quand la voiture reste à une distance bornée du centre de la piste.
- Récompense de plus en plus positive quand l’orientation de la voiture est parallèle à la direction de la piste. Nous avons aussi considéré l’option de récompenser la répétition de la même action pour éviter des comportements instables comme le zigzags ou des virages inattendus.
- Finalement nous multiplions le résultat par la vitesse afin de privilégier une allure rapide et ainsi obtenir un meilleur temps.

Illustration : heatmap de la récompense obtenue par l’agent pendant une simulation de 500 épisodes.
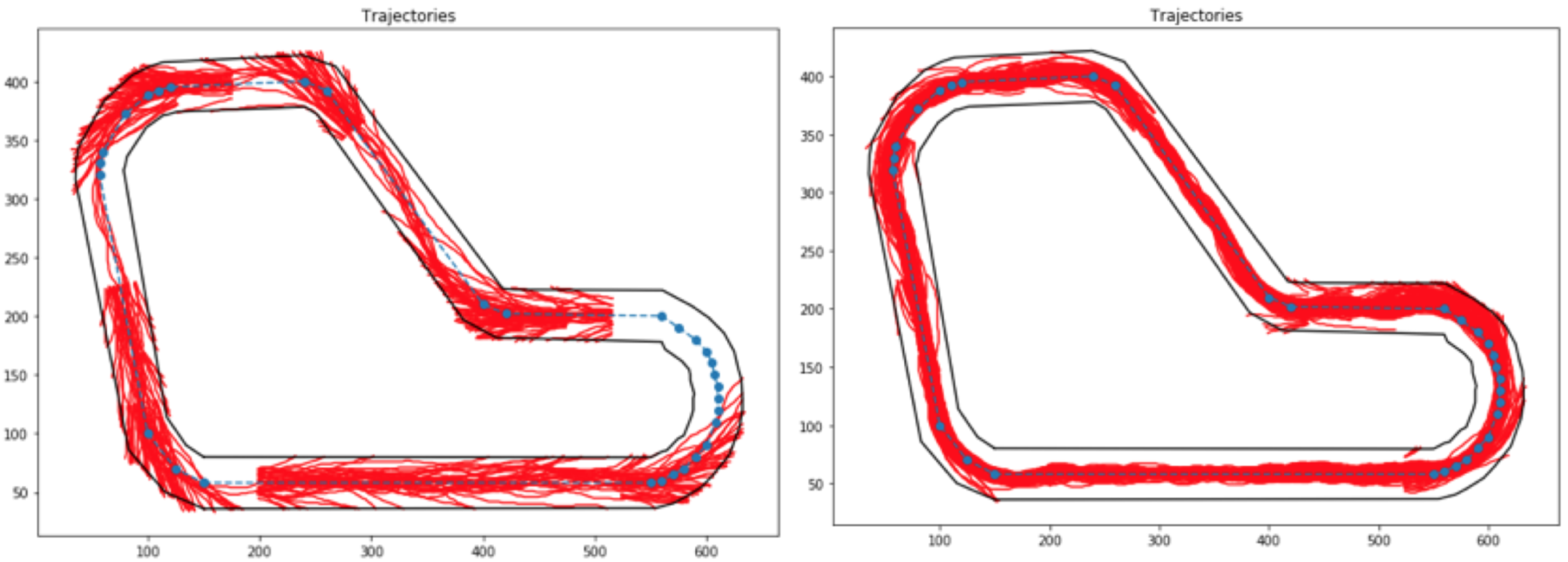
Illustration : trajectoires de l’agent au début de l’entraînement (gauche) et à la fin (droite).
Il apprend !!!
Il est important de remarquer qu’il existe des paramètres globaux connus par l’agent, comme la distance du centre de la piste, sa longueur, sa forme, etc. Nous avons calculé l’orientation optimale souhaitée pour la voiture dans certaines parties de la piste en utilisant une liste des points pivots appelés waypoints.
La fonction de récompense peut être encore améliorée en décalant la zone de la piste maximisant la récompense. En effet dans notre fonction de récompense elle est centrée par rapport au milieu de la piste mais elle pourrait plutôt suivre une trajectoire optimale. Par exemple elle pourrait être déplacée vers la gauche lorsque la voiture doit virer à gauche, et de même pour la droite. On peut aussi donner une récompense à l’agent lorsqu’il sort hors de cette zone mais essaye de remédier à cette situation en prenant des actions qui la font retourner dans la bande. Au niveau avancé on aurait pu construire un problème quasi supervisé en paramétrant chaque partie de la piste avec l’action idéale.
Une fois qu’une récompense a été définie pour chaque prise de décision on demande à l’agent de maximiser la quantité suivante, appelée retour (return) :
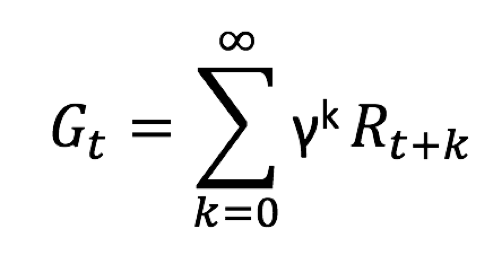
Fonction de retour au temps t, notée G
La quantité est définie avec un facteur d’actualisation (discount factor), noté γ qui permet de pondérer l’importance des actions futures. Précisément gamma peut varier dans l’intervalle [0,1].
- Si γ = 1 alors toutes les récompenses obtenues mêmes les plus lointaines ont autant d’importance. L’agent maximise le gain sur le long terme.
- Si γ = 0 alors seule la prochaine récompense est considérée, l’agent maximise le gain à court terme sans se soucier de l’impact de ses actions sur le futur.
Pour Deep racer, le choix de ce facteur d’actualisation est déterminant. Empiriquement on observe qu’un facteur d’actualisation autour de 0.95 nous semblait être optimal pour l’apprentissage. Cela correspond à une demi-vie d’environ 13 steps (ce qui signifie qu’une récompense obtenue après 13 steps a deux fois moins d’impact que la récompense suivant l’action).
Le modèle utilisé pour Deep racer : Proximal Policy Optimization
Il existe un très grand nombre d’algorithmes d’apprentissage par renforcement. L’objectif de cet article n’est pas de faire l’inventaire de ce qui existe. Cependant il faut comprendre quelques points clés qui permettent ici de choisir l’algorithme PPO (Proximal Policy Optimization) :
- L’espace des états est une image, l’espace des états est donc en quelque sorte “continu”
- Le nombre d’actions possibles est un nombre fini que nous fixons.
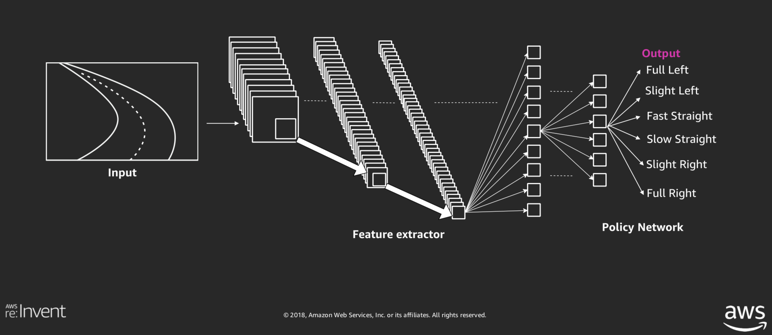 Architecture du modèle utilisé (Source AWS)
Architecture du modèle utilisé (Source AWS)
Le modèle prenant la décision en fonction de l’image reçue est représenté par un réseau de neurones profond. Des couches de convolutions y sont appliquées pour extraire les caractéristiques importantes de l’image. Finalement l’information est passée à une couche dense qui détermine en sortie l’action choisie.
Mais comment le réseau de neurones s’améliore ? Comment changent les probabilités des actions dans le temps ?
On démarre avec une stratégie aléatoire que l’on souhaite améliorer au fur et à mesure en analysant les expériences de l’agent.
Le modèle utilisé pour Deep Racer est le Proximal Policy Optimization (PPO) qui repose sur l’apprentissage d’un policy network (ici le réseau de neurones). Le modèle appartient à la catégorie des modèles de type Policy Gradient et vise à déterminer une stratégie (les poids du réseau de neurones dans notre cas) qui maximise l’espérance du retour :
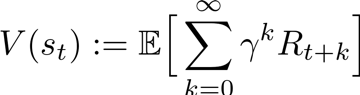
Comme c’est souvent le cas avec les réseaux de neurones, un algorithme de gradient ascent reposant sur la backpropagation est appliqué pour modifier les poids et ainsi encourager l’agent à exécuter les actions donnant un meilleur retour.
L’idée centrale de l’algorithme PPO est de prévenir des variations trop brusques dans la stratégie (et donc dans la variation des poids du policy network).
Le rapport entre la probabilité de choisir l’action at à l’état st sous la stratégie courante 𝜃 et sous l’ancienne stratégie 𝜃old est utilisé pour mesurer l’impact des actions :
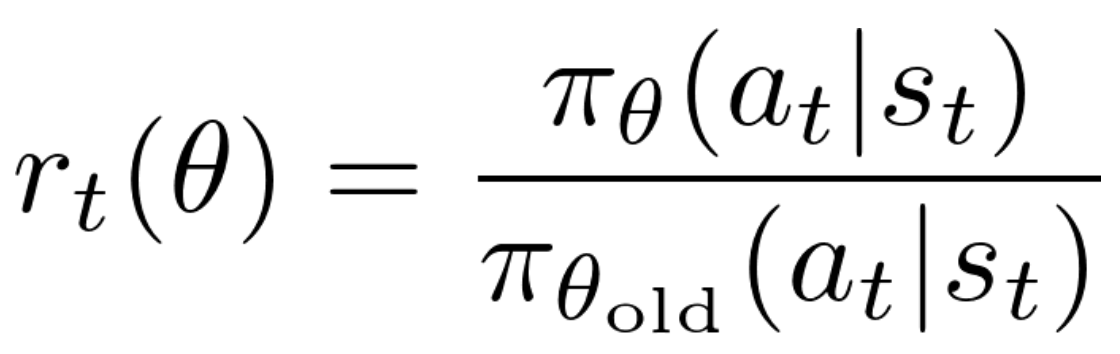
Cette quantité est multipliée par la fonction “avantage” :
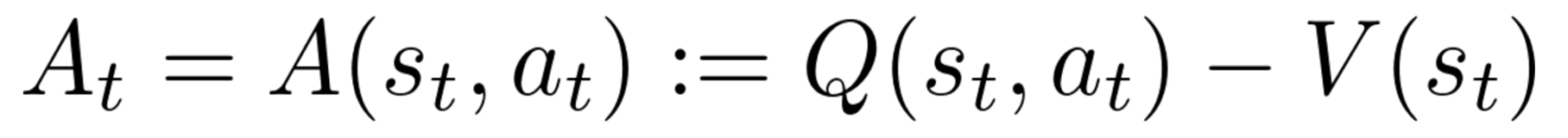
qui mesure l’amélioration apportée par l’action at par rapport au retour moyen espéré dans l’état st en suivant la stratégie actuelle. Un At>0 signifie que l’action at est meilleure que la moyenne de toutes les autres actions à l’état st.
La fonction objectif à maximiser via gradient ascent est donc l’espérance de rt(𝜃)At afin de pousser l’agent à choisir des actions qui apportent une meilleure récompense.
La principale innovation du PPO est de restreindre le rapport entre la nouvelle et la vieille policy rt(𝜃) à varier dans un intervalle de clipping [1-ε, 1+ε], où normalement ε est égal à 0.2. Ceci prévient des actualisations excessivement grandes de la nouvelle policy par rapport à la vieille et augmente la stabilité de l’algorithme.
Cet article ou cet article sont des bonnes sources pour comprendre plus en détail le fonctionnement du PPO.
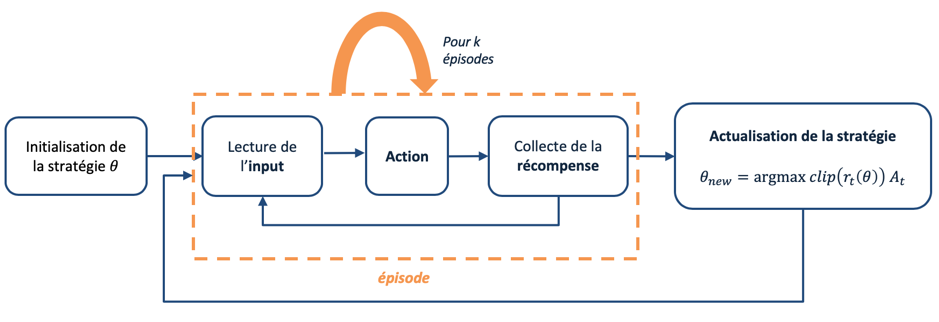
Résumé du processus de mise à jour de la stratégie pour PPO.
Hyperparamètres du modèle :
Le choix des hyperparamètres s’avère important pour le PPO. Voici les paramètres choisis pour Deep racer :
- Discount: γ = 0.95 prend en compte jusqu’à ~100 étapes pour le calcul du reward.
- Clipping : epsilon de l’intervalle de clip = 0.1 ou 0.2
- Entropie: On rappelle qu’une policy a une grande entropie si tous les actions ont des probabilités similaires d’être prises, tandis que l’entropie baisse si une des actions est plus probable que les autres. Dans le PPO un coefficient d’entropie est multiplié à l’entropie maximale possible et ajouté à la fonction objectif. Ceci contribue à la régularisation en prévenant une convergence prématurée vers une action de probabilité élevée. Notre choix : 0.01 ou 0.001
- Learning rate: 0.003 optimale
PPO recueille des trajectoires pour le nombre d’étapes ou épisodes fixé, puis performe un stochastic gradient ascent de taille batchsize sur toutes ces trajectoires pour le nombre spécifié d’époques pour mettre à jour la policy.
- Training set de trajectoires: 20-40 épisodes pour le début de l’entraînement, puis 10.
- Époques et batchsize : 10 et 64.
Exploration
On explique l’importance de l’exploration avec les deux options qu’on a pu tester : catégorique et epsilon greedy. Avec l’exploration catégorique l’agent choisit toujours l’action plus probable selon la policy courante. Par contre dans certaines situations il est important de pouvoir sortir de certains schémas et dédier du temps à l’exploration de nouvelles trajectoires qui potentiellement pourraient apporter des meilleures récompenses.
Cela est fait notamment avec l’exploration epsilon greedy : l’agent choisit avec probabilité epsilon de prendre une action au hasard, autrement il choisit l’action qu’il a estimé comme étant la meilleure. Cette méthode est souvent accompagnée avec une décroissance du epsilon dans le temps. Ainsi, prendre des actions aléatoirement devient de moins en moins probable avec le temps.
Preprocessing et segmentation de l’image d’entrée
Une autre tentative d’accélération de l’apprentissage a été faite en intervenant sur le preprocessing de l’image de la caméra en input. Un filtre pour détecter seulement les bords de la piste et la ligne pointillée du centre a été appliqué sans avoir un effet considérable sur la vitesse d’apprentissage.
Itérations et résultats sur le modèle
Après plusieurs heures d’entraînement et sur plusieurs paramètres de modèles différents on a constaté que la voiture apprenait à peine à faire quelques virages et ne terminait jamais un tour.
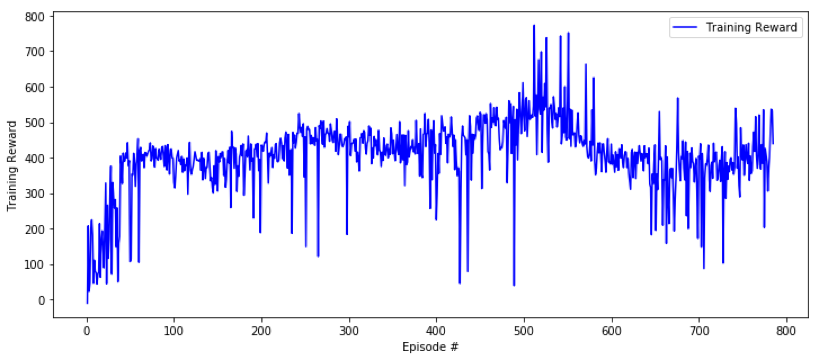
Illustration : Courbe d’apprentissage de notre premier modèle : l’apprentissage est instable et lent (1 tour ~ 1000 de training reward). Un résultat décevant !
Un remarquable progrès pour l’apprentissage a été obtenu lorsque nous avons mis en place une stratégie de positionnement aléatoire de la voiture au démarrage de chaque épisode. A chaque épisode la voiture voit ainsi une portion différente du circuit, ce qui permet d’éviter que l’agent fasse du sur-apprentissage sur le début de la piste. Également puisque la piste contenait seulement un virage à droite, on a renforcé l’apprentissage de l’action de virage à droite en favorisant légèrement la probabilité de commencer avant ce type de virage. Cette astuce a permis d’obtenir un modèle performant.
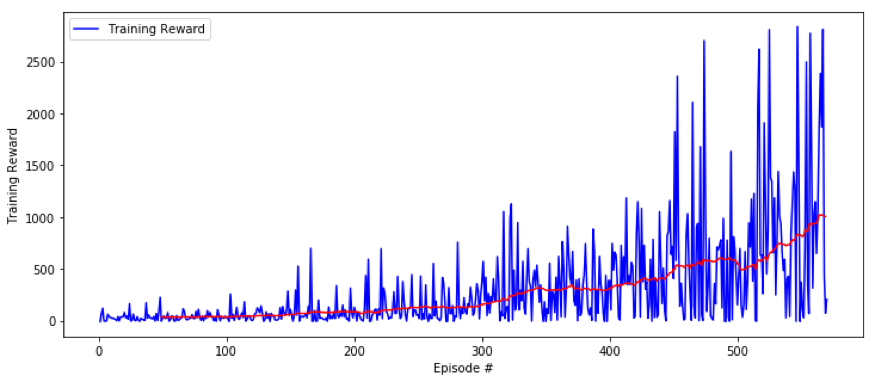
Illustration : Apprentissage du dernier modèle, le gain moyen (en rouge) augmente de manière stable
Après un certain nombre d’épisodes la récompense accumulée par épisode devient stable.
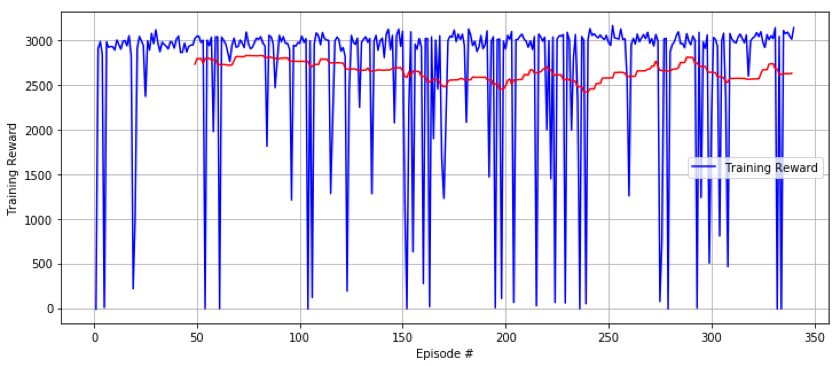
Illustration : Fin de l’entraînement du modèle, le gain moyen (en rouge) n’augmente plus et reste stable autour de 2700 (Training reward ~ 3000 signifie que la voiture a bien réalisée 3 tours)
On remarque des chutes de la récompense sur certains épisodes, partiellement dues à la stratégie d’exploration choisie, à la complexité de l’environnement ou encore au “catastrophic forgetting”. Ce dernier est courant en apprentissage par renforcement et provoqué par la trop grande importance accordée aux événements récents observés par l’agent. Il s’agit donc d’une forme d’overfitting sur les données les plus récentes. La prévention du catastrophic forgetting est d’ailleurs un sujet très investigué aujourd’hui. Un des points forts du PPO (L’algorithme utilisé) est justement de mettre en place une stratégie de mise à jour de la policy qui lutte contre le catastrophic forgetting.
Une autre solution intéressante, appelée Elastic Weight Consolidation (EWC), a été introduite dans cet article pour résoudre une série de tâches séquentielles sans oublier celles ayant été apprises en premier.
Une vidéo des résultats de notre modèle final sur le simulateur
Une vidéo à la première personnes des résultats du modèle sur simulateur
D’autres calibrations ont été effectuées pour optimiser le modèle. Notamment le choix du discount factor de 0.95 a été important à la fois en terme de vitesse d’apprentissage et de robustesse de l’apprentissage.
Conclusion
Après avoir entraîné notre agent pendant plusieurs heures sur le simulateur nous avons chargé notre modèle sur une clé USB et nous nous sommes lancés dans la vraie compétition au summit AWS de Paris. Malheureusement la voiture est sortie de la piste plusieurs fois lors de notre essai en conditions réelles et nous n’avons donc pas été en mesure d’enregistrer notre temps lors de la compétition. Ceci illustre assez bien le problème du “domain adaptation”. Nous nous étions uniquement entraînés avec les données d’un simulateur et ce modèle était plutôt robuste dans ces conditions (à peu près une sortie de piste tous les 20 tours). Cependant le modèle n’a pas résisté au changement de la source des données d’entrées (vraie image à la place d’une image issue du simulateur) ainsi qu’au changement du modèle physique. C’est un point sur lequel nous souhaitons travailler à l’avenir car le sujet est commun à de nombreux problèmes de reinforcement learning. Cependant cette expérience montre que le développement d’un modèle de reinforcement learning pour la conduite autonome sur simulateur est accessible.