

Synthétiser vos emails en quelques mots

✍Pierre-Jean Larpin, Antoine Simoulin / Temps de lecture 9 minutes
Une expérimentation de méthodes abstractives pour le résumé automatique
Alors que nous recevons chaque jours plus d’emails, Quantmetry mène de nombreuses expérimentations et projets pour faciliter et fluidifier leur gestion. Notamment avec la librairie Open Source Melusine qui permet de classifier des emails et d’en extraire des mots clés. Dans la continuité de ce travail, nous présentons ici une expérimentation visant à résumer automatiquement les emails, une tâche normalement opérée manuellement pour faciliter la gestion d’un échange et qui demande un temps significatif ! Nous nous concentrons ici sur des résumés “abstractifs” qui ne se limitent pas à extraire des passages saillants de l’email mais à le reformuler dans des termes et selon une formulation nouvelle et plus compacte.
Le résumé automatique
Le résumé constitue une épreuve à part entière de nombreux concours. Elle consiste à synthétiser un texte, en respectant un nombre imposé de mots, tout en retenant les informations essentielles. Cet exercice est difficile car il demande des capacités d’analyse, de réflexion et de restitution importantes.
Au delà d’une épreuve de langue, le résumé automatique représente une vraie opportunité pour de nombreux secteurs. En effet, une quantité considérable de données non structurées n’est pas exploitée par les entreprises car difficilement utilisable : par exemple, des rapports médicaux de patients, de longs rapports d’entretiens, des compte-rendus de réunions. La valorisation de ces données pourrait être rendue possible si des modèles pouvaient générer une synthèse des textes afin d’améliorer et faciliter leur traitement.
Les méthodes d’intelligence artificielle ont pendant longtemps échoué à imiter la capacité de synthèse de l’être humain mais les dernières avancées faites dans le traitement du langage permettent aujourd’hui des progrès spectaculaires dans ce domaine.
Convaincu par l’apport des nouvelles méthodes de Traitement Automatique du Langage (TAL ou NLP en anglais), Quantmetry investit du temps de ses consultants pour suivre et contribuer à l’état de l’art par le biais d’une équipe dédiée au NLP. Des travaux de recherche sur le résumé automatique de texte ont ainsi été menés en implémentant des méthodes à la pointe du NLP.
Modélisation
Il existe deux méthodes de résumé automatique détaillées ci-dessous. Dans la suite de l’article, nous étudierons la mise en place d’un modèle de résumé automatique par méthode abstractive.
La méthode extractive consiste à identifier des phrases complètes du texte original censées être les plus pertinentes et à les concaténer de façon à produire un extrait du document. Un des algorithmes par extraction le plus connu est l’algorithme TextRank, très similaire à PageRank. Cependant, cet algorithme présente des résultats limités quand les documents ne présentent pas suffisamment de phrases.
La méthode abstractive consiste à rédiger une synthèse en générant des phrases qui ne sont pas forcément contenues dans le document original. Cette méthode est plus difficile à mettre en place puisqu’elle suppose en un sens d’imiter le raisonnement de compréhension et de synthèse humain. Elle offre ainsi des perspectives d’usages plus intéressantes.
Evaluation des performances
Les modèles et techniques utilisés sont détaillés en dernière partie. Nous nous concentrons ici directement sur les résultats et leur analyse.
Quelques exemples
Sur la Table 1 ci-dessous, on peut observer des exemples de résumés générés par notre modèle après la phase d’entraînement. Ces résultats sont très cohérents et parfois même plus pertinents que les synthèses générées par l’humain ! Le modèle a appris à synthétiser des concepts par ses propres mots comme par exemple “attestation de location saisonnière” en “attestation villégiature”.
On peut également remarquer que les résumés générés par les conseillers sont très courts, ce qui va directement influencer le comportement de notre modèle, étant dans une approche supervisée.
| Mail Entrant | Résumé de référence écrit par un conseiller | Résumé généré |
| Comme convenu lors de mon appel je vous envoie l’acte de vente de l’appartement | Notification d’opposition | Acte de vente |
| J’ai besoin d’une attestation responsabilité civile pour le propriétaire de ma location saisonnière | Client demande attestation responsabilité civile | Attestation villégiature |
| J’ai de nombreux véhicules assurés chez vous et je n’ai pas de constat amiable dans chaque véhicule. Pouvez vous m’en faire parvenir ? | Véhicule | Demande de constat |
| Pouvez-vous m’envoyer un relevé d’information sur 36 mois ? merci de votre retour | Gestion contrat véhicule demande relevé d’information | Demande de relevé d’information |
| J’ai rejoint l’assurance aujourd’hui comme convenu par téléphone voici mon rib | Documents manquants relevé d’identité bancaire | Rib |
Table 1. Exemple de résumés générés par l’algorithme
Métriques d’évaluation manuelle
Afin d’étudier la cohérence des résumés générés sans être impacté par les limites des métriques automatiques décrites dans le paragraphe suivant, nous avons proposé à des conseillers d’évaluer un échantillon de 1000 résumés produits par notre algorithme et de les évaluer selon la grille proposée en Table 2. Les mails “parfaits” présentent un résumé syntaxiquement corrects qui résument de manière exhaustive l’email. La seconde catégorie regroupe les résumé syntaxiquement corrects mais qui ne présentent pas un compte rendu exhaustif du mail. Les résumés classifiés comme “faux” correspondent à soit des résumés dont la syntaxe n’est pas compréhensible, soit qui comportent une erreur sémantique manifeste.
Nous avons également filtré les emails avec un score de confiance élevé afin de voir si les résultats étaient meilleurs. On observe bien que les résumés avec un score de confiance élevé sont plus pertinents ce qui permet d’établir un seuil de confiance à partir duquel on considérera la prédiction comme fiable, ce seuil pouvant être défini suite à un retour métier.
| Evaluation |
Proportion sur les 1000 mails |
Proportion sur mails top scorés (score > 85%) |
| 😊 Parfait | 53% | 68% |
| 😕 Incomplet, pas complètement exact | 23% | 26% |
| 😱 Faux, inexploitable | 24% | 6% |
Table 2. Evaluation par les conseillers
Métriques d’évaluation automatique
Les papiers scientifiques ont tendance à comparer la performance de leurs modèle par rapport à la métrique Rouge. La métrique Rouge-N établit un score basé sur la proportion de mots ou groupes de mots, appelés N-grams, en commun entre une phrase cible et une phrase prédite par rapport au nombre de N-grams présents dans la phrase cible.
Les métriques les plus utilisés sont Rouge-1 et Rouge-2. La métrique Rouge-1 priorise le nombre de mots communs sans prendre en compte l’ordre des mots, la syntaxe ou encore les mots pouvant changer le sens de la phrase (par exemple la négation). La métrique Rouge-2 tend à conserver une cohérence syntaxique.
Nous comparons dans la Table 3 les métriques Rouge-1 et Rouge-2 de notre modèle avec celles présentées dans l’article original Get to The Point. Même si les résultats sont difficilement comparables car issus de deux corpus différents, les métriques du papier académique reflètent assez bien les meilleurs résultats qu’on peut trouver actuellement dans les papiers scientifiques.
On peut observer que les métriques R1 sont très similaires (~40), signifiant que l’on capture en moyenne 40% des mots des résumés cibles. Notre modèle présente aussi une métrique R2 bien supérieure à celle observée pour le jeu de donnée CNN Daily Mail, signifiant que, dans notre cas, nous proposons des résumés plus proches des résumés de références.
Toutefois, ces deux métriques ne sont pas idéales car elles vont fortement pénaliser un résumé au sens proche mais qui n’utilise pas le même vocabulaire. Elles ne font guère sens dans l’approche abstractive d’un résumé mais elles sont actuellement les métriques sur lesquelles on juge la pertinence d’un modèle.
| Dataset | R1 | R2 |
| CNN Daily Mail | 39.53 | 17.28 |
| Corpus Mail | 40.12 | 35.34 |
Table 3. Comparaison des métriques automatiques sur le corpus CNN Daily Mail, un corpus de référence pour cette tâche et pour notre jeu de données
Architecture du modèle
Seq2Seq
Nous avons implémenté le modèle Get To The Point: Summarization with Pointer-Generator Networks, publié à la conférence ACL en 2017. L’architecture repose sur une architecture Seq2Seq classique illustré en Figure 1. agrémentée d’un mécanisme d’attention et de pointeurs. Ce modèle permet de prendre une phrase en entrée et d’en générer une nouvelle en sortie. Ces modèles peuvent être utilisés pour de nombreuses applications. Pour la traduction par exemple, on propose une phrase en anglais au modèle et on compare la phrase traduite à la phrase de référence en français. Pour notre cas d’usage de résumé automatique, nous allons présenter au modèle des exemples d’emails et l’entraîner à générer le résumé de référence, il s’agit donc d’un entraînement supervisé. Un avantage de ce modèle est sa capacité à pouvoir traiter une séquence d’entrée de taille différente de la séquence de sortie.
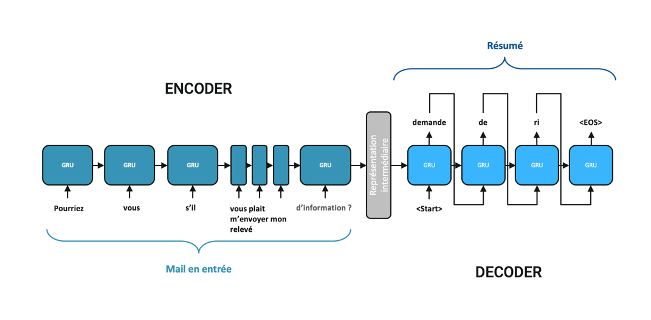
Figure 1. modèle Seq2Seq sans mécanisme d’attention ou de mécanisme de pointeurs
Comme illustré en Figure 1. Le réseau est structuré en deux parties. Dans un premier temps, l’encodeur condense l’information de la séquence d’entrée dans un vecteur. Pour ce faire, l’email en entrée est pré-traité et les mots sont représentés par des embeddings comme illustré dans cet article. Dans le cas des emails, nous nous appuyons sur la librairie Open-Source Melusine développée par Quantmetry et la MAIF. Les embeddings du mail en entrée passent ensuite séquentiellement dans une couche de RNN bidirectionnel composée par exemple de cellules GRU. Il est important de souligner qu’à chaque étape d’encoding, la cellule GRU reçoit l’embedding du mot courant mais également la sortie de celui encodé précédemment. C’est cette dépendance séquentielle qui permet la propagation de l’information jusqu’au dernier mot et permet à la fin d’obtenir un vecteur portant l’information de la séquence d’entrée en sortie de l’encodeur (partie Encoder outputs, en bleu clair sur la Figure 2.)
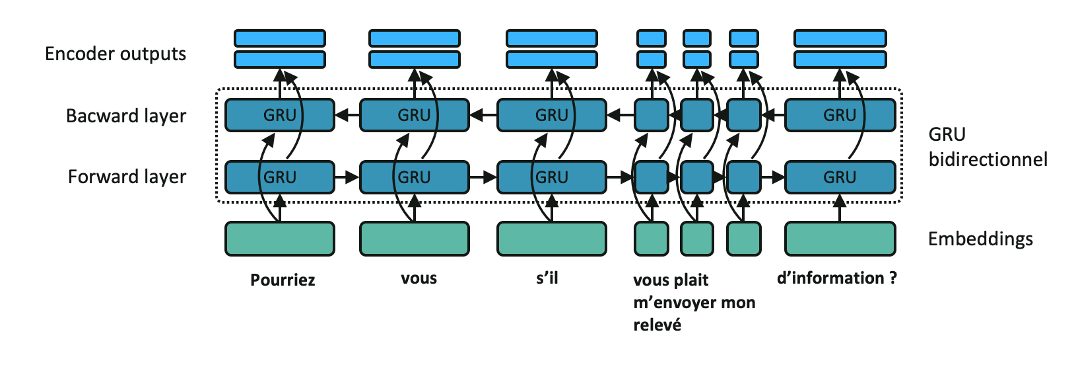
Figure 2. Encodeur avec cellule GRU bidirectionnelle
Une fois la séquence d’entrée encodée, le décodeur prédit mot à mot la séquence de sortie.
Pour se faire, il reçoit à chaque étape le vecteur portant l’information de la séquence d’entrée et de la portion de la séquence de sortie traduite jusqu’ici, et établit une distribution de probabilité du mot suivant.
Le mot alors prédit est celui :
- dont la probabilité est la plus élevée (greedy search)
- dont le choix mène à la séquence de sortie la plus probable (beam search). Pour ce faire, on garde en mémoire les N séquences les plus probables à chaque étape du décodage.
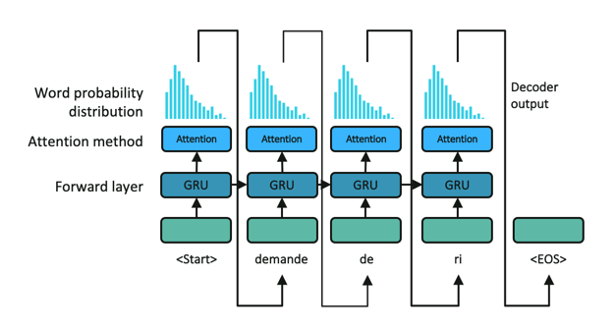
Figure 3. Décodeur avec cellule GRU unidirectionnelle
La séquence de sortie étant une succession de mots auxquels on a assigné une probabilité, il est alors possible de définir un score de confiance pour chaque prédiction. Cette propriété sera très importante pour la suite car elle nous permettra d’identifier un seuil à partir duquel nos prédictions seront considérées comme fiables.
Mécanisme d’Attention
Les modèles SeqSeq reposent sur un postulat fort. En effet pour que ce modèle fonctionne, il est nécessaire d’être capable de concentrer toute l’information de la séquence d’entrée en un vecteur de taille fixe, en l’occurrence l’Encoder Outputs du dernier token sur la figure 2. Néanmoins ceci est loin d’être vrai, d’autant plus lorsque la séquence d’entrée est longue. Une nouvelle architecture Seq2Seq, introduite dans Attention is all you need publié à NIPS en 2017, propose une solution. L’intuition derrière cette méthode est de se concentrer sur des parties différentes de la phrase à chaque étape du décodage. Cette méthode s’appelle le mécanisme d’attention et est illustré en Figure 4.
Le mécanisme d’attention intervient lors de la phase de décodage. À chaque étape du décodage, on propose un vecteur de représentation de la phrase d’entrée différent, appelé le vecteur de contexte. Ce vecteur est une somme pondérée de toutes les sorties de l’encodeur. Par conséquent au lieu de recevoir le même vecteur portant l’information condensée de la séquence d’entrée, le décodeur recevra un vecteur de contexte adapté à chaque étape du décodage lui permettant de se concentrer sur les bonnes parties de la séquence d’entrée pour prédire le mot suivant.
Les poids associés à chaque sortie de l’encodeur ne sont pas fixes et dépendent ainsi de l’étape de décodage dans laquelle l’algorithme se trouve. Le calcul des poids est illustré en Figure 4. mais nous ne rentrons pas ici dans le détail de l’implémentation.
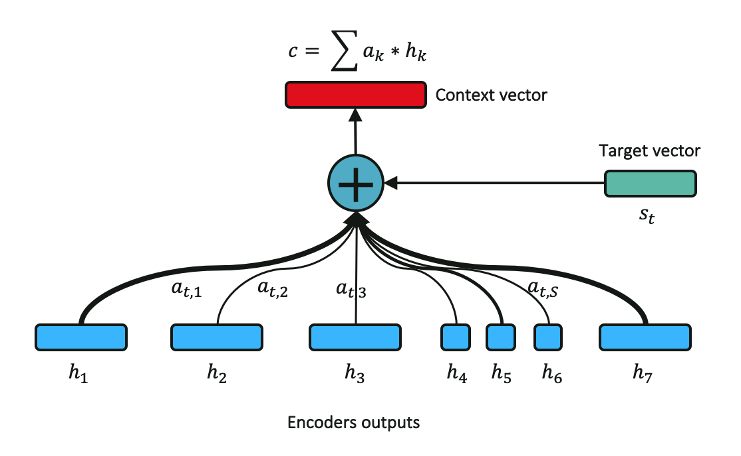
Figure 4. Mécanisme d’Attention simplifié
Finalement, l’architecture globale de l’Encodeur-Décodeur avec mécanisme d’attention et ses interactions sont représentées ci-dessous :
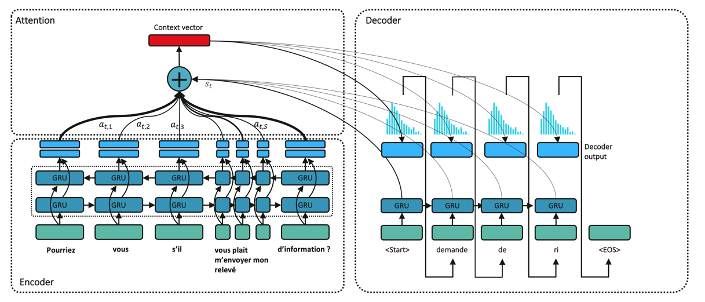
Figure 5. Architecture globale du modèle
Pointer Network
Lors de l’étape de décodage, la distribution de probabilité des mots est déterminée par une couche d’activation appelée Softmax, dont le temps de calcul augmente à mesure que la taille du vocabulaire est élevée. De ce fait, il est courant de réduire la taille du vocabulaire du modèle en gardant seulement les N mots les plus représentés dans notre corpus d’emails et de résumés. Les mots des emails et des résumés non présents dans le vocabulaire seront alors remplacés par un token artificiel _UNK pour unknown.
Le Pointer Network consiste à enrichir le mécanisme d’attention afin de permettre d’extraire un mot de la séquence d’entrée non présents dans le vocabulaire. En effet le vocabulaire étant de taille limitée, certains mots de la séquence d’entrée portant beaucoup d’informations sont remplacés par le token _UNK comme des numéros de téléphone, une adresse mail ou des prénoms.
Le mécanisme de pointeur a pour rôle, à chaque étape du décodage, d’attribuer un poids à chaque mot de la séquence d’entrée, y compris les mots non présents dans le vocabulaire. Par conséquent, notre modèle peut apprendre à extraire des mots de la séquence d’entrée non présents dans le vocabulaire lorsque cela est nécessaire.
Conclusion
Les résultats obtenus par notre modèle sont très satisfaisants et nous ont permis d’acquérir des convictions sur l’utilisation des méthodes à l’état de l’art de résumé abstractif en français. Notre modèle s’est avéré performant avec un temps d’entraînement relativement court (~2 heures) et un temps d’inférence court (75 ms), ceci s’expliquant notamment par la taille relativement petite des emails entrants et des résumés associés. Aussi notre modèle étant capable d’associer un score de confiance à une prédiction, il est possible de filtrer les prédictions selon un contexte métier.
Enfin, ce modèle a été développé en mai 2019 et est l’un des premiers modèles de résumé automatique en français. De nouveaux modèles ont aujourd’hui vu le jour, s’appuyant sur les méthodes d’attention. Ces modèles dérivés de Bert et autres réseaux pré-entrainés ouvrent des perspectives prometteuses dans ce domaine.
