

TALN 2023 - Revue des dernières innovations en NLP

Nous avons eu l’opportunité d’assister cette année à la conférence TALN 2023, évènement majeur dans le domaine de NLP Français, qui offre un espace dédié à la présentation des avancées récentes et des recherches en linguistique informatique et en traitement automatique du langage naturel (TALN). Plusieurs formats de restitution sont disponibles lors de l’événement : conférences, tutoriels, ateliers et sessions d’affiches, donnant ainsi un aperçu du futur du NLP dans le domaine de la recherche ou à travers des retours d’expériences concrets en entreprise. Les différentes présentations ont suscité un vif intérêt, et une sélection des interventions les plus marquantes a été faite pour en proposer une restitution succincte.
Conférenciers invités :
Les conférenciers invités lors de TALN 2023 sont tous des leaders dans le domaine du NLP. Massimo Poesio, de l’Université d’Oxford, a donné une conférence sur l’avenir de la traduction automatique. Rada Mihalcea, de l’Université du Michigan, a parlé de l’utilisation du NLP pour l’analyse des médias sociaux. Et Hinrich Schütze, de Google Research, a abordé les défis de la mise à l’échelle des modèles NLP sur de grands ensembles de données.
Ces interventions ont permis aux participants de réfléchir aux usages actuels et futurs du NLP et ont fourni un aperçu des dernières avancées dans ce domaine passionnant.
Commençons notre exploration des différentes présentations que nous avons suivies lors de cet événement passionnant par la section :
Modèle de langue et santé
CamemBERT-bio : Un modèle de langue français savoureux et meilleur pour la santé (Touchent et al., 2023)
Introduction
La disponibilité croissante des données cliniques dans les hôpitaux offre de nouvelles opportunités de recherche, mais ces données sont souvent non structurées, nécessitant une extraction précise des informations à partir des comptes-rendus médicaux. Bien que les modèles de langage tels que BERT, comme CamemBERT, aient permis des avancées significatives dans la reconnaissance des entités nommées, ils sont principalement entraînés sur le langage courant et présentent des limitations sur les données biomédicales.
Contribution
Pour combler cette lacune, les auteurs ont créé un nouveau jeu de données biomédicales en français et ont poursuivi l’entraînement préalable de CamemBERT sur ces données spécifiques. Cette approche a donné naissance à CamemBERT-bio, une version spécialisée du modèle CamemBERT pour le domaine biomédical français. La méthodologie impliquait donc l’utilisation du transfert d’apprentissage pour adapter le modèle de langue aux données biomédicales.
Les résultats obtenus ont montré une amélioration moyenne de 2,54 points de F-mesure dans la reconnaissance des entités nommées biomédicales, par rapport aux modèles de langue généraux tels que CamemBERT. Cette amélioration est significative et démontre l’efficacité de CamemBERT-bio dans le traitement des données biomédicales en français.
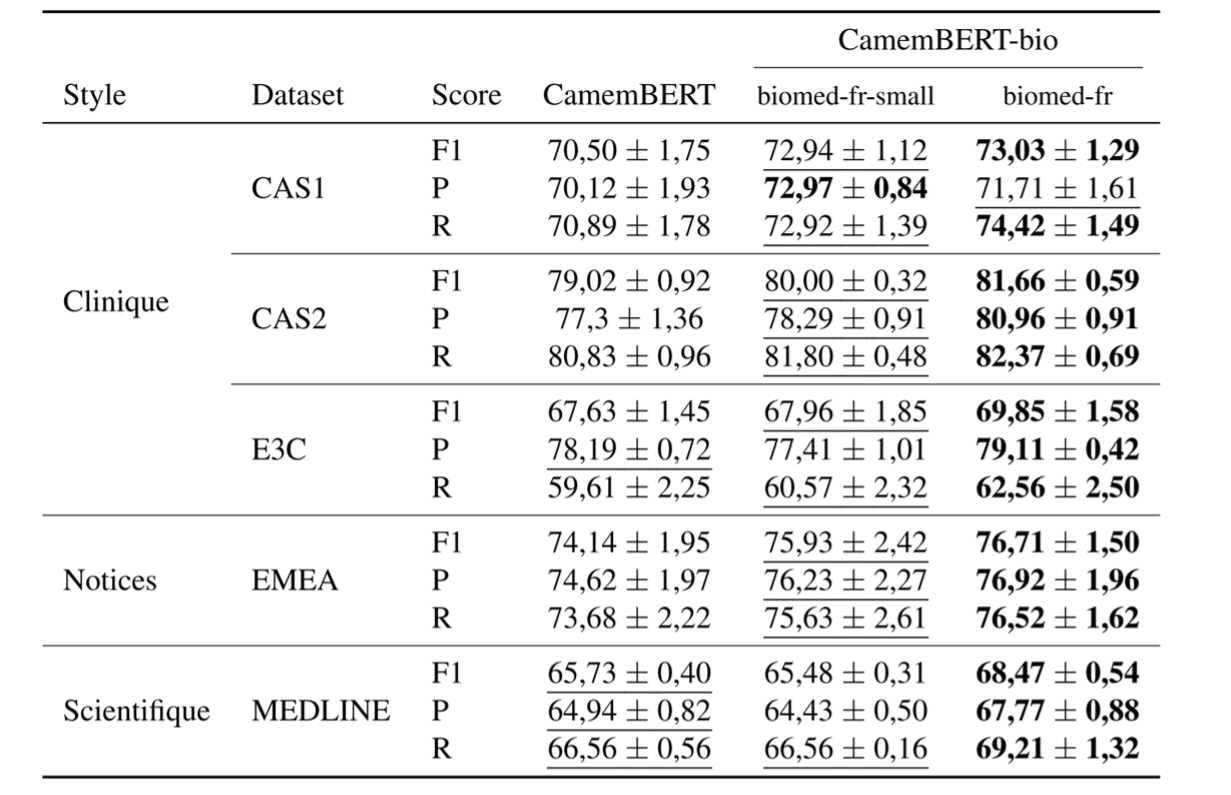
Moyenne sur 10 évaluations des F-mesures sur différents jeux biomédicaux de reconnaissance d’entités nommées
Avantages
- Amélioration significative des performances dans la reconnaissance des entités nommées biomédicales en français.
- Utilisation du transfert d’apprentissage pour adapter le modèle de langue aux données biomédicales spécifiques.
- Ouverture de nouvelles perspectives pour la recherche médicale et la prise de décision clinique en français.
Conclusion
CamemBERT-bio représente une avancée majeure dans le domaine de l’analyse des données biomédicales en français. Grâce à son entraînement spécialisé sur des données biomédicales, ce modèle de langue offre de meilleures performances dans la reconnaissance des entités nommées. Cela ouvre de nouvelles perspectives pour la recherche médicale et la prise de décision clinique en français.
Traduction
L’évaluation de la traduction automatique du caractère au document : un état de l’art (Nakhlé et al., 2023)
Introduction
L’évaluation de la traduction automatique (TA) est un domaine de recherche actif depuis de nombreuses années. Les méthodes d’évaluation traditionnelles, telles que le score BLEU, s’avèrent souvent peu fiables pour les systèmes de TA modernes, qui sont basés sur des modèles neuronaux. Le score COMET est une nouvelle méthode d’évaluation qui est plus prometteuse, mais elle est encore en développement.
Contribution
Dans cet article, les auteurs abordent les défis et les avancées dans le domaine de l’évaluation de la TA. Ils soulignent l’importance du contexte dans le processus de traduction et soutiennent que de nombreuses erreurs de traduction peuvent être négligées sans une compréhension exhaustive du contexte. Ils développent également des approches qui ciblent les phénomènes linguistiques dépendant du contexte.
Enfin, ils identifient un défi majeur dans le domaine de l’évaluation de la TA : sélectionner la méthode la plus efficace et fiable. Ce domaine est encore en développement et sujet à des améliorations constantes, et ils encouragent des études supplémentaires sur les méthodes d’évaluation de la TA.
La méthode traditionnelle d’évaluation de la TA est le score BLEU. Le score BLEU est basé sur la similarité des chaînes de mots entre la traduction automatique et la traduction humaine. Cependant, le score BLEU a été critiqué pour ne pas prendre en compte le sens de la traduction. Le score COMET est une nouvelle méthode d’évaluation de la TA qui est plus sensible au sens de la traduction. Le score COMET est basé sur l’utilisation d’un modèle de langue multi-langues comme XLM-R, modèle pré entraîné que l’on spécialise sur de l’évaluation de traduction à l’aide d’évaluation humaine.

Exemple d’une traduction correcte même si différente de la référence
Les résultats des études ont montré que le score COMET est plus fiable que le score BLEU pour évaluer la qualité de la traduction automatique. Le score COMET est également plus sensible au contexte, ce qui signifie qu’il est moins susceptible de manquer des erreurs de traduction qui dépendent du contexte.
Avantages / Inconvénients
Le score COMET a plusieurs avantages par rapport aux méthodes d’évaluation traditionnelles, telles que le score BLEU. Le score
COMET est plus fiable, plus sensible au contexte et est plus susceptible de refléter la qualité de la traduction humaine. Cependant, le score COMET est également plus complexe et plus difficile à calculer que le score BLEU.
Conclusion
Le domaine de l’évaluation de la TA est encore en développement. Le score COMET est une nouvelle méthode d’évaluation qui est plus fiable et plus sensible au contexte que les méthodes d’évaluation traditionnelles. Cependant, le score COMET est également plus complexe et plus difficile à calculer que le score BLEU. D’autres études sont nécessaires pour améliorer le score COMET et le rendre plus pratique.
Enfin, au milieu d’une multitude de nouvelles approches d’évaluation, l’article identifie un défi majeur : sélectionner la méthode la plus efficace et fiable. Ce domaine est toujours en développement et sujet à des améliorations constantes, l’article encourage des études supplémentaires sur les méthodes d’évaluation de la traduction automatique.
Méthodes de contrôle pour la génération de texte
Towards a Robust Detection of Language Model-Generated Text: Is ChatGPT that easy to detect? (Antoun et al., 2023)
Introduction
Avec l’avènement des grands modèles linguistiques (LLM), tels que ChatGPT, les inquiétudes concernant la détection du texte généré par une machine, en particulier dans les langues non anglaises et dans divers domaines, ont augmenté. La détection de tels textes est essentielle dans un certain nombre d’applications, y compris les plateformes de médias sociaux et les chatbots, où l’identification de contenus inappropriés est essentielle.
Contribution
Les auteurs proposent une méthodologie pour développer et évaluer des détecteurs ChatGPT. Ils ont traduit un ensemble de données de l’anglais vers le français en utilisant chatgpt, puis ont entraîné un classificateur sur les données traduites. Les performances des détecteurs ont été évaluées à la fois sur des données dans le domaine et hors domaine.
L’étude montre que les détecteurs peuvent identifier efficacement le texte généré par ChatGPT et afficher une robustesse contre les techniques d’attaque de base, en particulier dans le même domaine. Cependant, ces détecteurs présentent des vulnérabilités dans les contextes hors domaine, soulignant le défi permanent de la détection du texte adversaire.
Exemple : Bonnes performances sur les tests FTB et FAQ-Gouv, mais une baisse de précision observée sur l’ensemble FAQ-Rand, possiblement due à des erreurs de traduction.
L’étude souligne également l’importance de comprendre que les résultats des tests en domaine peuvent ne pas se généraliser à une plus grande variété de contenus. Elle montre que, bien que les détecteurs soient efficaces dans des contextes spécifiques, ils peuvent rencontrer des difficultés lorsque les données générées par la machine sont présentées de manière plus subtile ou dans un contexte qui diffère de celui dans lequel le détecteur a été entraîné.
Avantages / Inconvénients
Les avantages de l’approche proposée sont les suivants :
- Elle permet d’identifier efficacement le texte généré par ChatGPT.
- Elle est robuste contre les techniques d’attaque de base.
- Elle peut être utilisée dans un certain nombre d’applications, y compris les plateformes de médias sociaux et les chatbots.
Les inconvénients de l’approche proposée sont les suivants :
- Elle présente des vulnérabilités dans les contextes hors domaine.
- Elle nécessite un modèle de machine learning, qui peut être complexe à mettre en œuvre.
Conclusion
L’approche proposée est prometteuse et pourrait être utilisée pour améliorer la capacité de détecter le texte généré par ChatGPT dans différentes langues et domaines. Les auteurs suggèrent d’autres travaux futurs, tels que l’amélioration de la robustesse des détecteurs contre les attaques hors domaine et l’extension de l’approche à d’autres LLM.
Intelligibilité
Introduction
Avec la montée en puissance de l’apprentissage automatique, les algorithmes d’explicabilité sont devenus essentiels pour comprendre les décisions prises par les modèles. Les méthodes agnostiques, qui sont indépendantes du type de modèle, suscitent un intérêt particulier car elles permettent de générer des exemples artificiels en modifiant légèrement les données originales, puis d’observer les changements de décision du modèle sur ces exemples. Cependant, ces méthodes requièrent des exemples initiaux et ne fournissent des explications que pour ces derniers.
Contribution
Pour remédier à ces limitations, les chercheurs ont proposé une méthode appelée Therapy, qui offre une explicabilité modèle-agnostique pour les modèles de langue sans avoir besoin de données d’entrée. . . De plus, cette méthode fournit des explications sur le fonctionnement global du modèle plutôt que de fournir plusieurs explications locales, offrant ainsi une vue d’ensemble.
Les expériences menées ont démontré que Therapy fournissait des informations instructives sur les caractéristiques des textes utilisées par le modèle de manière compétitive, même en l’absence de données d’entrée, par rapport aux méthodes qui utilisent des données. La méthode coopérative de génération de textes permet une compréhension approfondie du modèle de langue, offrant ainsi une explicabilité globale.
Avantages / Inconvénients
Les avantages de l’approche proposée sont les suivants :
- Therapy propose une méthode modèle-agnostique pour l’explicabilité des modèles de langue, ce qui la rend applicable à une variété de modèles.
- En se basant sur la génération coopérative, cette approche n’a pas besoin de données d’entrée spécifiques, ce qui la rend flexible et applicable dans des cas où les données sont indisponibles pour des raisons de confidentialité ou autres.
- En fournissant une explication globale plutôt que plusieurs explications locales, Therapy permet une vue d’ensemble du fonctionnement du modèle de langue.
Les inconvénients de l’approche proposée sont les suivants :
- La méthode Therapy pourrait nécessiter des ressources de calcul supplémentaires en raison de la génération coopérative de textes, ce qui pourrait affecter les performances en termes de temps d’exécution.
- Comme toute méthode d’explicabilité, les résultats de Therapy peuvent nécessiter une interprétation et une analyse supplémentaires pour une compréhension complète du modèle.
Conclusion
L’article présente Therapy, une méthode coopérative pour l’explicabilité globale des modèles de TAL. En utilisant la génération coopérative de textes, Therapy offre des explications instructives sur les caractéristiques du modèle de langue, sans nécessiter de données d’entrée spécifiques. Cette approche modèle-agnostique permet une compréhension approfondie du modèle et offre une vue d’ensemble de son fonctionnement.
TAL et réseaux sociaux
Classification de tweets en situation d’urgence pour la gestion de crises (Meunier et al., 2023)
Introduction
Les réseaux sociaux, en particulier Twitter, sont une source d’information précieuse en cas de crise. Ils peuvent être utilisés pour obtenir des informations sur l’état de la crise, les besoins des personnes touchées et les efforts de secours. Cependant, la quantité d’informations disponibles sur les réseaux sociaux peut être écrasante, ce qui rend difficile pour les services de secours de trouver les informations les plus pertinentes.
Contribution
Dans cet article, les auteurs présentent un nouveau jeu de données en français qui a été annoté manuellement dans le contexte de la gestion de crise. Ce jeu de données contient plus de 10 000 tweets annotés selon leur pertinence, leur urgence et leur intention. Les auteurs ont ensuite utilisé plusieurs modèles d’apprentissage automatique pour classer des tweets de ce jeu de données.
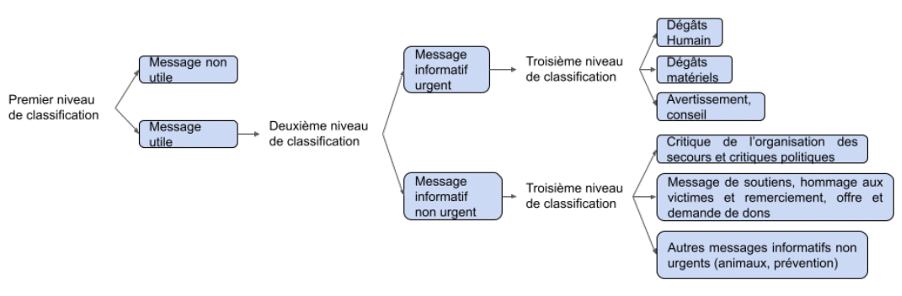
Typologie des messages pour les crises écologies
Ils ont ensuite testé plusieurs modèles d’apprentissage automatique pour classifier les tweets en fonction de leur pertinence, de leur niveau d’urgence et de l’intention qu’ils véhiculent. L’objectif est d’aider au mieux les services de secours pendant les crises en utilisant des méthodes d’évaluation spécifiques à la gestion de crise. Les résultats obtenus lors de l’évaluation des modèles sont encourageants, même lorsque ces derniers sont confrontés à de nouvelles crises ou à de nouveaux types de crises. Ils ont pu classer les tweets avec une précision de plus de 90 % pour la pertinence, de plus de 80 % pour l’urgence et de plus de 70 % pour l’intention.
Avantages / Inconvénients
Les avantages de l’approche proposée par les auteurs :
- Elle permet de classer les tweets en fonction de leur pertinence, de l’urgence et de l’intention, ce qui peut aider les services de secours à trouver les informations les plus pertinentes.
- Elle est basée sur un jeu de données en français, ce qui est rare pour ce type d’étude.
Les inconvénients de l’approche proposée :
- Elle nécessite un jeu de données annoté, ce qui peut être difficile à obtenir.
- Elle nécessite un modèle d’apprentissage automatique, qui peut être plus complexe à mettre en œuvre, notamment en terme d’infrastructure au vue de la volumétrie que représente ces réseaux sociaux.
Conclusion
L’approche proposée par les auteurs est prometteuse et pourrait être utilisée pour améliorer la gestion des crises. Les auteurs suggèrent d’autres travaux futurs, tels que l’amélioration de la précision des modèles et l’extension de l’approche à d’autres langues.
Protocole d’annotation multi-label pour une nouvelle approche à la génération de réponse socio-émotionnelle orientée-tâche (Vanel et al., 2023)
Introduction
Les systèmes conversationnels sont de plus en plus populaires, mais ils peuvent parfois avoir du mal à générer des réponses pertinentes et adaptées au contexte émotionnel de l’interlocuteur. Dans cet article, les chercheurs se concentrent sur la modélisation des comportements humains dans les systèmes conversationnels, en particulier les agents conversationnels génératifs orientés-tâches. Ils proposent une nouvelle approche visant à améliorer la pertinence des réponses générées en tenant compte du contexte émotionnel de l’interlocuteur.
Contribution
L’approche proposée par les chercheurs consiste à prédire des labels émotionnels supplémentaires pour conditionner la réponse générée. Pour ce faire, ils ont développé un protocole d’annotation de données qui permet de collecter des données annotées avec des labels émotionnels. Le protocole d’annotation est basé sur un ensemble de questions qui permettent d’identifier les émotions exprimées dans les messages.

Annotation d’un tour de parole en émotion et stratégie de dialogue
Les chercheurs ont évalué leur approche sur un ensemble de données de messages annotés avec des labels émotionnels. Ils ont obtenu des résultats encourageants, démontrant que leur approche permet de générer des réponses plus pertinentes et adaptées au contexte émotionnel de l’interlocuteur.
Avantages / Inconvénients
Les avantages de l’approche proposée par les auteurs :
- L’approche proposée permet de générer des réponses plus pertinentes et adaptées au contexte émotionnel de l’interlocuteur.
- Le protocole d’annotation développé permet de collecter des données annotées avec des labels émotionnels, ce qui peut être utilisé pour améliorer les modèles de réponse émotionnelle.
Les inconvénients de l’approche proposée par les auteurs :
- L’approche nécessite un ensemble de données annotées avec des labels émotionnels, ce qui peut être difficile à obtenir.
- L’approche nécessite un modèle de machine learning, qui peut être complexe à mettre en œuvre.
- L’approche n’est pas encore parfaite et peut parfois générer des réponses qui ne sont pas pertinentes ou adaptées au contexte émotionnel de l’interlocuteur.
Conclusion
L’approche proposée par les chercheurs est prometteuse et pourrait être utilisée pour améliorer la qualité des réponses générées par les systèmes conversationnels. Les chercheurs suggèrent d’autres travaux futurs, tels que l’amélioration de la précision des modèles et l’extension de l’approche à d’autres langues.
Normalisation lexicale de contenus générés par les utilisateurs sur les réseaux sociaux. (Nishimwe, 2023)
Introduction
Dans l’ère des réseaux sociaux, les contenus générés par les utilisateurs sont souvent caractérisés par des abréviations, des fautes d’orthographe et des variations lexicales, ce qui rend le traitement automatique du langage naturel plus difficile. Une récente étude menée par Lydia Nishimwe propose une solution prometteuse pour surmonter ces défis : la normalisation lexicale. Cette approche consiste à normaliser les mots non standards présents dans les contenus générés par les utilisateurs, ouvrant ainsi la voie à une meilleure compréhension et interprétation de ces contenus.
Contribution
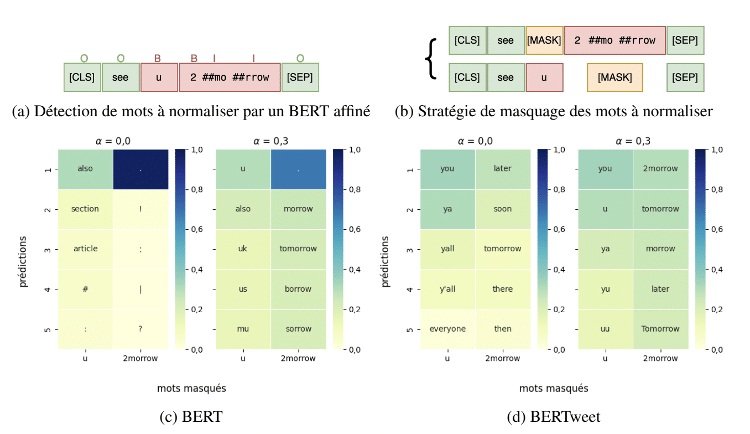
La méthodologie utilisée pour la normalisation lexicale comprend plusieurs étapes. Tout d’abord, les mots qui doivent être normalisés sont détectés dans les phrases. Ensuite, la phrase est dupliquée en remplaçant les mots non standards par des masques. Enfin, une combinaison linéaire avec une distance d’édition est utilisée pour générer la phrase normalisée. Il est suggéré d’explorer des stratégies de masquage plus larges, telles que le masquage de mots entiers ou de portions de mots, ainsi que l’intégration d’un module de similarité phonétique pour améliorer davantage les résultats.

Détection (a) et masquage (b) de mots à normaliser par un détecteur BERT. Prédictions des mots masqués par les correcteurs BERT (c) et bertweet (d) pour α = 0,0 et 0,3, triées par score.
Les résultats de cette étude démontrent que l’approche de normalisation lexicale propose une solution efficace pour améliorer le traitement des contenus générés par les utilisateurs sur les réseaux sociaux. En normalisant les mots non standards, il est possible d’améliorer la compréhension et l’interprétation de ces contenus, tout en renforçant les performances des modèles de traitement automatique du langage naturel (TAL).
Avantages / Inconvénients
Les avantages de l’approche proposée par les auteurs :
- La normalisation lexicale permet d’améliorer la qualité des données des réseaux sociaux en éliminant les variations lexicales et les mots non standards, ce qui facilite le traitement automatique du langage naturel.
- En normalisant les contenus générés par les utilisateurs, il est possible d’améliorer la compréhension et l’interprétation de ces contenus, ce qui est bénéfique pour les chercheurs et les utilisateurs des réseaux sociaux.
- L’approche de combinaison linéaire avec une distance d’édition offre une méthode efficace pour générer des phrases normalisées à partir de contenus non standards.
Les inconvénients de l’approche proposée par les auteurs :
- L’approche de normalisation lexicale peut être complexe et nécessite une étape de détection des mots non standards, ce qui peut ajouter de la complexité au processus de traitement du langage naturel.
- Bien que les résultats de cette étude soient prometteurs, il est nécessaire d’explorer davantage de stratégies de masquage et d’améliorer la similarité phonétique pour obtenir des performances optimales.
Conclusion
La normalisation lexicale des contenus générés par les utilisateurs sur les réseaux sociaux est une approche prometteuse pour améliorer le traitement automatique du langage naturel. En détectant et en normalisant les mots non standards, il est possible de mieux comprendre et interpréter ces contenus, tout en renforçant les performances des modèles de TAL. Cependant, des efforts supplémentaires sont nécessaires pour explorer de nouvelles stratégies de masquage et d’amélioration de la similarité phonétique.
Analyse syntaxique
Derrière les plongements de relations(Hugo Thomas (1) , Guillaume Gravier (1) , Pascale Sébillot (1)
Repo GitLab: https://gitlab.inria.fr/huthomas/taln_experiments
Introduction
Les relations entre les entités nommées dans le texte sont essentielles pour une variété de tâches de traitement automatique du langage naturel (TALN), telles que la compréhension du langage naturel (NLU), la question-réponse et le résumé automatique. Cependant, l’extraction de ces relations peut être un défi, car elles ne sont pas toujours explicitement marquées dans le texte.
Contribution
Dans cet article, les auteurs explorent différentes approches pour extraire les relations entre les entités nommées dans une phrase. Ils se concentrent notamment sur l’utilisation de plongements de relations, la classification des relations et l’analyse de similarité linguistique et géométrique.
Les auteurs ont montré que leurs approches peuvent extraire avec précision les relations entre les entités nommées dans un texte. Ils ont également montré que leurs approches sont plus précises que les approches traditionnelles, telles que l’extraction d’entités nommées et l’analyse sémantique.
Les résultats de cet article montrent que les plongements de relations, la classification des relations et l’analyse de similarité linguistique et géométrique sont des approches prometteuses pour l’extraction de relations entre les entités nommées dans le texte. Ces approches peuvent être utilisées pour améliorer la performance d’un certain nombre de tâches de TALN.
Avantages / Inconvénients
Les avantages des approches proposées par les auteurs incluent :
- Une précision élevée lors de l’extraction des relations entre les entités nommées dans le texte.
- Une capacité à améliorer la performance d’un certain nombre de tâches de TALN.
Les inconvénients des approches proposées par les auteurs incluent :
- Une complexité élevée.
- Une dépendance à de grandes quantités de données d’entraînement.
Conclusion
Dans l’ensemble, les résultats de cet article montrent que les plongements de relations, la classification des relations et l’analyse de similarité linguistique et géométrique sont des approches prometteuses pour l’extraction de relations entre les entités nommées dans le texte. Ces approches peuvent être utilisées pour améliorer la performance d’un certain nombre de tâches de TALN.
Géométrie de l’auto-attention en classification : quand la géométrie remplace l’attention (Fosse et al., 2023)
Introduction
Les modèles de langage auto-supervisés (LLM) tels que BERT ont connu un succès remarquable dans un large éventail de tâches de traitement automatique du langage naturel (TALN). Une caractéristique clé des LLM est leur capacité à apprendre des relations entre les mots d’une phrase, ce qu’ils font à l’aide d’une couche d’auto-attention.
La couche d’auto-attention est une fonction non linéaire qui prend en entrée un vecteur de mots et renvoie un vecteur de mots, où chaque mot est pondéré en fonction de sa relation avec les autres mots de la phrase. Ces poids d’attention sont ensuite utilisés pour calculer une représentation de la phrase, qui est utilisée pour la tâche de classification.
Contribution
Dans cette étude, les auteurs explorent la géométrie de l’auto-attention en classification. Ils s’intéressent particulièrement à l’anisotropie des plongements de mots, c’est-à-dire leur concentration dans une direction spécifique. Ils analysent les propriétés géométriques des plongements de mots, des clés et des valeurs dans une couche d’auto-attention. Ils découvrent que la direction dans laquelle les plongements s’alignent indique l’appartenance à une classe.
Les auteurs enquêtent ensuite sur le mécanisme de la couche d’auto-attention et l’interaction entre les clés et les valeurs qui assure la construction d’une représentation anisotrope. Ils constatent que cette construction est progressive lorsque plusieurs couches sont empilées et est également robuste face aux contraintes externes sur la distribution des poids d’attention, compensées par le modèle grâce aux valeurs et aux clés.
Les auteurs présentent les résultats suivants :
- Les plongements de mots s’alignent dans une direction déterminée par la classe.
- La construction de la représentation anisotrope est progressive lorsque plusieurs couches sont empilées.
- La représentation anisotrope est robuste face aux contraintes externes sur la distribution des poids d’attention.
Dans l’ensemble, les auteurs constatent que l’anisotropie des plongements au sein d’un énoncé est liée à la classe. Les plongements s’alignent dans une direction déterminée par la classe, ce qui est en accord avec le fonctionnement intrinsèque du modèle. Ils découvrent également comment le modèle compense les contraintes pour garantir son fonctionnement en alignant les plongements dans une direction, même lorsqu’il y a des contraintes externes sur la distribution des poids d’attention.
Avantages / Inconvénients
Les avantages de l’approche proposée incluent :
- Elle permet de comprendre le fonctionnement des LLM en classification.
- Elle permet de développer de nouvelles techniques pour améliorer les performances des LLM en classification.
Les inconvénients de l’approche proposée incluent :
- Elle nécessite une compréhension approfondie de la géométrie des plongements de mots.
- Elle peut être difficile à mettre en œuvre dans des applications pratiques.
Conclusion
L’approche proposée est prometteuse et pourrait être utilisée pour améliorer les performances des LLM en classification. Les auteurs suggèrent d’autres travaux futurs, tels que l’application de leur approche à d’autres tâches de TALN et l’amélioration de sa faisabilité pratique.
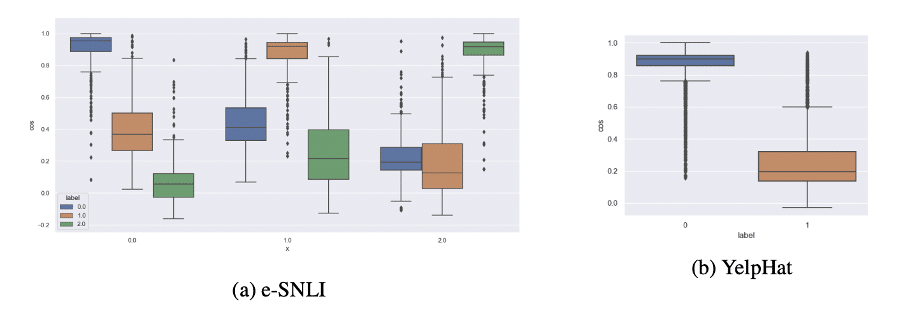
Distribution de la similarité cosinus entre le plongement d’un énoncé représentant une classe et les plongements du reste des énoncés du corpus
Utilisation des modèles de langue comme bases de connaissances
Enrichissement des modèles de langue pré-entraînés par la distillation mutuelle des connaissances. (Moreno et al., 2023)
Introduction
Les bases de connaissances sont des ressources essentielles dans de nombreuses applications nécessitant une grande quantité d’informations. Cependant, leur incomplétude limite leur utilité, ce qui souligne l’importance de compléter ces bases de connaissances. Récemment, une approche de monde ouvert a émergé, combinant les capacités des bases de connaissances à représenter des connaissances factuelles avec celles des modèles de langue pré-entraînés (PLM) à capturer des connaissances linguistiques hautement contextuelles à partir de corpus de textes.
Contribution
Dans cette étude, les auteurs proposent un cadre de distillation pour la complétion des bases de connaissances, où les modèles de langue pré-entraînés utilisent des annotations souples sous forme de prédictions d’entités et de relations fournies par un modèle de plongements de bases de connaissances. Ainsi, ils préservent la capacité des modèles de langue pré-entraînés à prédire des entités à partir de vastes collections de textes. Pour mieux s’adapter à la tâche de complétion des connaissances, ils étendent la modélisation traditionnelle du langage masqué des PLM à la prédiction d’entités et d’entités liées dans un contexte donné.
Les expériences menées dans le cadre de l’évaluation KILT, sur des tâches à forte intensité de connaissances, démontrent le potentiel de cette approche. L’enrichissement des modèles de langue pré-entraînés par la distillation mutuelle des connaissances permet d’améliorer la capacité de ces modèles à prédire et à compléter des entités et des relations dans les bases de connaissances. Cette méthode ouvre de nouvelles perspectives pour améliorer la complétude des bases de connaissances et renforcer les performances des modèles de langue pré-entraînés.
Avantages / Inconvénients
Les avantages de l’approche proposée incluent :
- Cette approche combine les avantages des bases de connaissances et des modèles de langue pré-entraînés, permettant ainsi une meilleure complétion des connaissances.
- En utilisant des annotations souples, les modèles de langue pré-entraînés préservent leur capacité à prédire des entités à partir de vastes collections de textes.
- L’extension de la modélisation du langage masqué des PLM à la prédiction d’entités et d’entités liées dans un contexte donné améliore leur adaptabilité à la tâche de complétion des connaissances.
Les inconvénients de l’approche proposée incluent :
- La distillation mutuelle des connaissances peut nécessiter des ressources de calcul importantes en raison de la complexité des modèles de langue pré-entraînés et des bases de connaissances.
- L’efficacité et les performances de cette méthode peuvent dépendre de la qualité des prédictions d’entités et de relations fournies par le modèle de plongements de bases de connaissances.
Conclusion
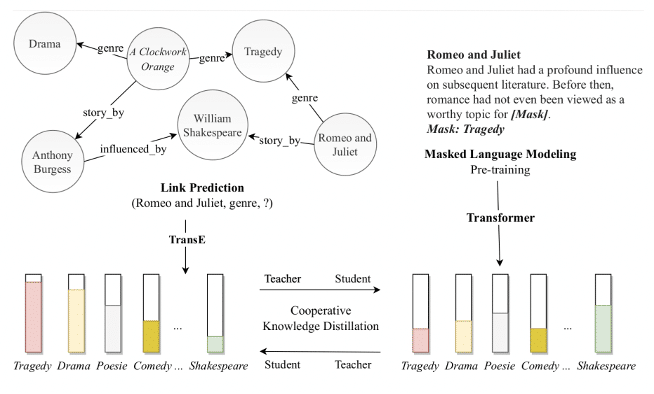
L’article présente une approche novatrice pour l’enrichissement des modèles de langue pré-entraînés en complétant les bases de connaissances. Grâce à la distillation mutuelle des connaissances, cette méthode combine les avantages des bases de connaissances et des modèles de langue pré-entraînés, permettant ainsi une meilleure prédiction et complétion des entités et des relations. Les expériences réalisées démontrent le potentiel de cette approche, ouvrant de nouvelles perspectives pour améliorer la complétude des bases de connaissances.
Exploitation de plongements de graphes pour l’extraction de relation biomédicales (Tang et al., 2023)
Introduction
L’extraction de relations biomédicales (BRE) est une tâche clé dans le domaine de la bio-informatique. Elle consiste à identifier les relations entre les entités nommées dans un texte biomédical, telles que les médicaments, les maladies et les symptômes. La BRE est un défi car les relations biomédicales peuvent être complexes et subtiles, et elles peuvent être exprimées de différentes manières dans le texte.
Contribution
Dans cet article, les auteurs proposent une nouvelle approche pour la BRE basée sur l’utilisation de plongements de graphes et de variantes adaptées de BERT pour le domaine biomédical. BERT est un modèle d’apprentissage automatique basé sur des réseaux neuronaux qui a été pré-entraîné sur un grand corpus de texte et de code. Les auteurs ont adapté BERT au domaine biomédical en pré-entraîné le modèle sur un ensemble de données de texte biomédical. Ils ont également utilisé des plongements de graphes pour représenter les relations entre les entités nommées dans le texte.
Les auteurs ont évalué leur approche sur plusieurs jeux de données de BRE. Les résultats ont montré que leur approche était capable d’extraire les relations biomédicales avec une précision supérieure aux méthodes existantes.
L’étude de Robert Bossy, Anfu Tang et Louise Deleger propose une approche innovante pour améliorer la BRE en utilisant des plongements de graphes et des variantes adaptées de BERT pour le domaine biomédical. Ces avancées contribuent à une meilleure compréhension des informations biomédicales et peuvent avoir des applications importantes dans la recherche médicale et pharmaceutique.
Avantages / Inconvénients
Les avantages de l’approche proposée par les auteurs incluent :
- Une précision élevée lors de l’extraction des relations biomédicales.
- Une capacité à traiter un large éventail de relations biomédicales.
- Une capacité à être adaptée à différents domaines biomédicaux.
Les inconvénients de l’approche proposée par les auteurs incluent :
- Une complexité élevée.
- Une dépendance à de grandes quantités de données d’entraînement.
Conclusion
Dans l’ensemble, les résultats de l’étude de Robert Bossy, Anfu Tang et Louise Deleger montrent que leur approche est une amélioration significative des méthodes existantes pour la BRE. Cette approche peut avoir un impact important sur la recherche médicale et pharmaceutique en permettant aux chercheurs d’extraire plus facilement et plus précisément les relations biomédicales des textes.

Un exemple venant du corpus d’extraction de relations ChemProt . Une relation “CPR:4” est annotée dans la phrase entre Argatroban et thrombin ; on trouve une relation “decreaseˆactivity” entre ces entités dans la BC externe CTD.
Tri-apprentissage génératif : génération de données pour de la reconnaissance d’entités nommées semi-supervisé (Boulanger et al., 2023)
Introduction
Le développement de nouvelles solutions de traitement automatique de la langue (TAL) nécessite généralement un accès à des données coûteuses et potentiellement sensibles. Dans de nombreux cas, les chercheurs utilisent des modèles pré-entraînés de grande taille comme point de départ pour des tâches spécialisées. Cependant, la spécialisation de ces modèles nécessite une grande quantité de données étiquetées spécifiques à la tâche. Dans leur étude, les auteurs explorent l’utilisation de l’apprentissage semi-supervisé dans un contexte où les exemples étiquetés sont limités et les données non étiquetées sont inexistantes.
Contribution
Les auteurs proposent différentes méthodes de génération de corpus non étiquetés, qui sont utilisés en alternance avec les étapes d’entraînement des modèles. De plus, ils emploient ces modèles entraînés pour filtrer les exemples générés. Ils ont évalué cette approche en utilisant le tri-apprentissage et l’auto-apprentissage sur des corpus en anglais et en français.
Les auteurs ont obtenu des résultats encourageants, démontrant que leur approche permet d’améliorer les performances des modèles d’apprentissage semi-supervisé sur des corpus où les exemples étiquetés sont limités.
Avantages / inconvénients
Les avantages de l’approche proposée par les auteurs sont les suivants :
- Elle permet d’améliorer les performances des modèles d’apprentissage semi-supervisé sur des corpus où les exemples étiquetés sont limités.
- Elle est relativement simple à mettre en œuvre.
Les inconvénients de l’approche proposée sont les suivants :
- Elle nécessite un modèle pré-entraîné de grande taille.
- Elle peut être chronophage pour générer des données non étiquetées de qualité.
Conclusion
L’approche proposée par les auteurs est prometteuse et pourrait être utilisée pour améliorer les performances des modèles d’apprentissage semi-supervisé sur des corpus où les exemples étiquetés sont limités. Les auteurs suggèrent d’autres travaux futurs, tels que l’amélioration de la vitesse de génération des données non étiquetées et l’extension de l’approche à d’autres langues.
Conclusion générale
La conférence TALN 2023 a été un événement majeur pour la communauté du traitement automatique du langage naturel (TALN) en France. Réunissant plus de 1 000 participants de la communauté NLP du monde entier. La conférence a été marquée par une série de présentations de pointe sur les dernières avancées en matière de traitement automatique du langage naturel (NLP).
Les conférenciers invités, les tutoriels, les ateliers et les sessions d’affiches ont offert une vision complète de l’état de l’art du TALN. Elles ont notamment mis en lumière les progrès récents réalisés dans les domaines de l’apprentissage automatique profond, de l’intelligence artificielle conversationnelle et de la traduction automatique.
La participation active de Quantmetry a contribué à consolider le lien entre l’industrie et la recherche. Cet événement a permis aux ingénieurs chercheurs de Quantmetry et à la communauté du TALN de se retrouver et de présenter leurs travaux sur des sujets et de discuter des défis et des opportunités du domaine tels que la recherche d’information sémantique, la génération automatique de texte et la compréhension du langage naturel.
En conclusion, la conférence TALN 2023 a été un succès à tous égards. Elle a contribué à la diffusion des connaissances et des innovations en TALN, tout en renforçant les liens entre la recherche et l’industrie.
Les membres de l’expertise NLP exploitent le potentiel des données textuelles à l’aide de solutions d’IA à forte valeur ajoutée grâce à la maîtrise des technologies à l’état de l’art (modèles de deep-learning « pré-entrainés » BERT, ELMo, GPT-2 ou FlauBERT).

Senior Data Scientist
Badreddine, membre actif de l'expertise NLP et animateur du Pôle R&D NLP, ayant collaboré avec des clients tels que le Parlement Européen, Kering, Atos, Renault Nissan Mitsubishi, Damart, sur diverses thématiques d'Intelligence artificielle. Il est passionné par l'exploration de nouvelles techniques NLP autour des LLMs, Qlora, LORA et RAG.

Data Scientist Ph.D confirmé
Lead Tech de MAPIE mais aussi Data Scientist Confirmé au sein de l’expertise NLP, Thibault participe activement à la R&D de Quantmetry autour de l’IA de confiance à travers MAPIE, la librairie python open-source pour la quantification de l'incertitude des prédictions.

Data Scientis confirmé
Data Scientist diplômé de Telecom Paris et titulaire d'un master 2 de Polytechnique Paris, Hussein a également travaillé sur plusieurs sujets de data science (Text mining, systèmes de recommandation, détection d'anomalies, classification d’images, …) il est passionné de sujets R&D autour de la détection de failles de LLM.

Data Scientis confirmé
Benjamin possède un master en Systèmes d'Information & Big Data de l'ECE Paris et un mastère spécialisé en machine learning de l'ESCP Business School. Il a une expérience en data science, notamment en résumé automatique et en modélisation de données pour une mutuelle, où il a implémenté des modèles comme BERT via PyTorch.

Stagiaire NLP
Stagiaire NLP sur les modèles Transformers pour les données multi-modales, Ornella possède un Master MVA de l'École normale supérieure et un Master en Mathématiques et Applications à l'Université Paris Dauphine-PSL. Son parcours est axé sur les méthodes deep learning de pointe et la modélisation des données.