

Qualité des données, ou la genèse de l’intelligence artificielle de confiance

L’intelligence artificielle de Confiance est un sujet que l’on adresse tous les jours chez Quantmetry pour fournir à nos clients des algorithmes de qualité. Ce sujet est traité par l’expertise Reliable AI qui assure la connaissance et l’application de l’état de l’art des 8 thématiques de l’IA de Confiance introduites dans cet article. La qualité de données est une de ces 8 composantes.
![]()
La qualité des données, à quoi ça sert ?
Maîtriser la qualité des données en entrée d’un modèle est un important prérequis dans la mise en place d’une IA de confiance. En effet, un modèle étant entraîné à partir de données, si elles-mêmes ne respectent pas certains critères de qualité, le modèle d’IA pourra difficilement les respecter à son tour. Comme dit l’adage : garbage in, garbage out.
Derrière le terme de qualité des données, sont cachés cinq concepts clés que nous allons détailler : la gouvernance, le contrôle de la pertinence, de la cohérence, de la complétude et de la précision.
La qualité des données, qu’est-ce que c’est ?
D’après la définition du Larousse, la qualité est « chacun des caractères et propriétés positifs de la donnée qui font qu’elle correspond au mieux à ce qu’on en attend ». La qualité des données se décompose donc en 5 critères distincts.
Gouvernance de la donnée
Dans un premier temps, pour pouvoir contrôler les données, il faut être capable de les connaître et de les comprendre : savoir quelles données sont utilisées à chaque phase de la construction ou de l’exploitation d’un modèle, de connaître leur origine, leurs étapes de transformation éventuelles et qui en est responsable. C’est ce qu’on appelle la gouvernance de la donnée. Il s’agit également d’anticiper le cycle de vie la donnée et de son processus de labellisation, car la donnée labellisée est le carburant de la plupart des IAs en production.
Contrôle de la pertinence
Lors du développement d’un modèle d’IA, toutes les variables des données disponibles ne sont pas forcément pertinentes. En effet, cela dépend du cas d’usage métier et contrôler la pertinence des données revient à sélectionner les variables les plus alignées avec l’objectif métier, et uniquement celles-ci. C’est à la fois un enjeu d’efficacité et de conformité à certaines réglementations, comme le RGPD (principe de minimisation).
Contrôle de la cohérence
La cohérence est une autre des propriétés de la donnée à contrôler pour assurer sa qualité. Elle correspond à la qualification de son format et de sa gestion : la donnée doit être cohérente d’une source de donnée à l’autre d’une part et doit également être en cohérence avec la connaissance métier la réalité du terrain. Contrôler cette cohérence, cela signifie implémenter les méthodes de quantification des incohérences et les correctifs nécessaires, le tout de manière documentée et reproductible.
Contrôle de la complétude
Contrôler la complétude des données se fait par deux angles différents. Dans un premier temps, on s’assure de la représentativité temporelle : si la date de création ou d’intégration des données est cohérente avec les hypothèses de modélisation (on parle de profondeur d’historique). Dans un second temps, on contrôle la spatialité ; c’est-à-dire si toutes les populations cibles du cas d’usage sont également représentées, de manière à identifier les biais présents dans les données. On s’assure également de mettre en place un contrôle des valeurs manquantes présentes dans les données aligné avec l’objectif métier.
Contrôle de la précision
La donnée donne toujours une vision déformée de la réalité. Non seulement par sa non-représentativité (on l’a vu dans le paragraphe précédent sur la complétude), mais aussi par son inexactitude. Toute donnée peut être vue comme une mesure du monde réel, et toute mesure s’accompagne de bruit, d’incertitudes et d’anomalies. Contrôler la précision de la donnée, c’est définir les différentes sources d’inexactitudes (bruits, anomalies, biais de mesure), les quantifier, et les corriger de manière proactive.
La qualité des données, comment l’activer ?
Maintenant que nous comprenons mieux tous les critères qui font qu’une donnée est de qualité, définissons trois actions qui permettent de mesurer et mettre en place ces propriétés pour assurer cette qualité des données au sein des modèles d’IA.
Sélectionner
La première action à mettre en place est la sélection des données pertinentes alignées sur le besoin métier. Nous voulons produire un document de cadrage définissant les choix des variables des données mais aussi la manière dont la cible a été choisie ou modélisée. Ces choix doivent être justifiés en accord avec l’objectif métier. Pour cela, il faut effectuer un travail de qualification de la pertinence pour chaque variable d’un jeu de données ainsi qu’un recensement des hypothèses et approximations faites pour définir la cible.
Qualifier
Une fois les données sélectionnées, il est nécessaire de définir des critères de qualités de données pour les qualifier. Ces critères de qualités sont multiples. Liés au concept de cohérence nous pouvons recenser le format, le type, la cohérence métier et inter-sources. Si nous nous intéressons à la complétude des données, la fraîcheur (date) et la représentativité sont à mesurer. Enfin, du côté de la pertinence, les propriétés importantes sont la présence de bruit, d’anomalies ou de doublons. Ces critères de qualités recensés peuvent alors être mesurés et documentés.
Filtrer
Le filtrage de la donnée permet de corriger une donnée de mauvaise qualité. Après avoir détecté certaines caractéristiques de non-qualité, il est possible de mettre en place une stratégie de filtrage (ou suppression) ou de correction de la donnée. Cette stratégie doit être justifiée par rapport aux objectifs métiers. Son impact doit être mesuré en comparant la volumétrie des données corrigées par rapport à la volumétrie initiale. Chaque correctif doit être tracé dans le temps et réversible.
La qualité des données, en vrai ça donne quoi ?
Pour mieux comprendre et s’imprégner de ce concept clé de l’IA de confiance, nous présentons un cas d’usage concret mettant en place une évaluation et des actions pour s’assurer de la qualité des données.
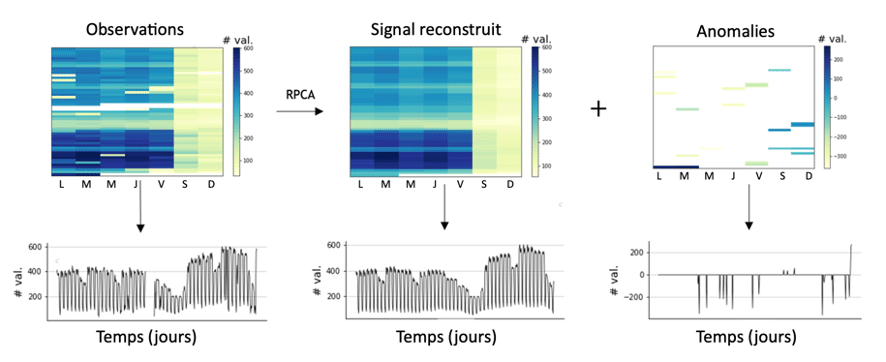
Figure 1 : Reconstruction des séries temporelles avec données manquantes grâce à Qolmat. Les données brutes disponibles sont des séries temporelles de l’affluence voyageur avec des données manquantes. Le signal a été reconstruit pour obtenir un jeu de données complet et cohérent grâce à la méthode d’imputation multivariée RPCA implémentée dans le package Qolmat développé par Quantmetry. Cette méthode permet également d’extraire les anomalies depuis les observations brutes.
Ce cas d’usage prend place chez un client qui cherche à prédire le nombre de voyageurs, notamment les pics d’affluence, sur le réseau transilien (Ile-de-France). Les données disponibles sont des séries temporelles d’affluence voyageurs avec des données manquantes. En effet, l’historique des données est perturbé à cause de dysfonctionnements, de portes ouvertes, de grèves, etc.
L’entraînement d’un modèle de prévision capable de faire la prédiction de l’affluence quotidienne nécessite d’avoir de la donnée complète sur les séries temporelles. C’est ici qu’intervient le concept de complétude des données. En effet, nous avons besoin de palier à ces valeurs manquantes tout en gardant la cohérence entre les différentes données. D’une part une cohérence temporelle : les données doivent garder une continuité dans le temps, et d’autre part une cohérence spatiale ; c’est-à-dire l’affluence relative entre les différentes gares.
Pour répondre à cette problématique et remettre en qualité les données, il a été nécessaire de mettre en place des algorithmes avancés de reconstruction du signal : pour détecter les anomalies puis y remédier. Le package open-source Qolmat en cours de développement a permis cette imputation de données manquantes en les remplaçant par des données artificielles, aussi réalistes que possible, afin de les rendre exploitables pour un modèle de machine learning et obtenir des gains significatifs de performance.
A travers cet exemple, on prend conscience que des données remises en qualités sont le point de départ d’une IA de confiance et permettent de rendre ses prédictions plus performantes !
Vive la qualité de données !
Les membres de l’expertise Reliable AI développent des modèles performants, fiables et maîtrisés, sur l’ensemble du cycle de vie, pour une IA de confiance.

Data Scientist de l'expertise Reliable AI