

Intelligence artificielle de confiance et équité : éviter le piège d’ignorer les biais

L’intelligence artificielle de Confiance est un sujet que l’on adresse tous les jours chez Quantmetry pour fournir à nos clients des algorithmes de qualité. Ce sujet est traité par l’expertise Reliable AI qui assure la connaissance et l’application de l’état de l’art des 8 thématiques de l’IA de Confiance introduites dans cet article. L’équité est une de ces 8 composantes.

L’équité, à quoi ça sert ?
L’équité est un sujet à part entière de l’intelligence artificielle de confiance. Cette dimension a longtemps été négligée, créant nombres de scandales d’IA racistes ou sexistes. L’équité cherche à recentrer la notion le respect de l’être humain, afin de maîtriser les risques de discrimination.
L’équité, qu’est-ce que c’est ?
L’équité, c’est « attribuer à chacun ce qui lui est dû par référence aux principes de la justice naturelle et de l’impartialité », nous apprend le dictionnaire Larousse. Appliquée à l’IA, cette définition va prendre quatre significations opérationnelles.
Définir les groupes sensibles
Si l’un des objectifs de l’équité consiste à éviter la discrimination, encore faut-il savoir quels groupes sont susceptibles d’être discriminés. Ces groupes sont en général très dépendants du cas d’usage : personnes maîtrisant mal le langage (enfants, handicapés, étrangers) ; apparence physique (âge, genre, ethnie) ; revenus ; localisation géographique ; pour ne citer que les plus courants.
Une bonne pratique est de considérer qu’un groupe est sensible dès lors que les personnes n’ont pas choisi d’appartenir à ce groupe, soit par des facteurs innés (couleur de peau, langue maternelle), soit par des facteurs sociétaux (pauvreté, géographie).
Contrôler les biais de données
On ne maîtrise une source de données que quand on connaît bien tous les biais qui la constituent. Contrôler les biais dans les données, c’est donc un travail de recensement et de quantification de tous les différents biais possibles.
D’une manière générale, les personnes qui émettent peu de données ou des données de mauvaise qualité sont souvent mal représentées numériquement : l’illectronisme touche plusieurs millions de personnes en France, et les minorités sont souvent également minoritaires dans les données. A cela s’ajoute le contexte socio-économique, qui peut véhiculer des biais de société passés indésirables aujourd’hui (clichés, racisme, misogynie, etc.).
Contrôler les biais de modélisation
Trop souvent, la performance d’un modèle est réduite à une simple moyenne prise sur toute la population. C’est une erreur méthodologique grave, et dangereuse. Un diagnostic médical peut ne créer que 1% d’erreurs, si toutes ces erreurs sont concentrées sur un groupe sensible particulier sans aucune justification biologique, c’est une marque de discrimination flagrante.
Maîtriser les biais de modélisation, c’est donc avant tout être capable de segmenter ses analyses de performance, et d’assurer non seulement le plus haut niveau de performance global, mais aussi au sein de chaque groupe sensible. On attend d’un modèle équitable que sa performance et son niveau d’incertitudes soient sensiblement identiques d’un groupe sensible à l’autre.
Contrôler les biais d’interaction
L’interaction homme-machine est également biaisée : les décideurs ont tendance à suivre les recommandations de l’IA (biais de confirmation). A cela s’ajoute d’autres biais cognitifs : l’effet « mouton de Panurge », qui consiste à suivre les décisions du plus grand nombre, ou encore le biais de sélection des interactions humaines, comme les commentaires de satisfaction, qui sont plus souvent rédigés par des personnes insatisfaites.
Dans un cas d’usage IA, l’équité n’est pas circonscrite à l’algorithme : bien au contraire, elle englobe toute la chaîne de décision, y compris les décideurs finaux. Un algorithme peut très bien faire une recommandation non-discriminante, mais son utilisateur peut continuer à discriminer. C’est ce qui a été observé dans certaines applications de covoiturage, où cacher le nom/prénom des conducteurs et des passagers changeait le taux d’acceptation de certaines populations par les uns et les autres.
L’équité, comment l’activer ?
Implémenter des IAs équitables est plus facile à dire qu’à faire ! Heureusement, trois actions de bon sens permettent de faire l’essentiel du chemin.
Spécifier
La première action à mettre en place est politique : définir les groupes sensibles susceptibles d’être discriminés. C’est bien une action politique car elle fait appel à des notions éthiques. Cette action demande également un effort d’anticipation : « qu’est-ce qui pourrait mal se passer avec ce cas d’usage, et quelles populations seraient impactées ? ». Les chartes éthiques des entreprises peuvent servir de boussoles pour orienter les réflexions.
En complément, spécifier des métriques d’équité quantifiables, mesurables, ainsi que des objectifs à atteindre permet de factualiser et d’auditer la démarche mise en œuvre.
Détecter
La deuxième action réside dans l’analyse des biais. Le contexte socio-économique n’est pas neutre, et induit en général une représentation biaisée de certaines populations dans le monde digital. Certaines données à première vue anodines sont en réalité des proxys de variables sensibles. Par exemple, le métier peut être un proxy du genre, le salaire un proxy de l’âge, le lieu d’habitation un proxy de l’origine ethnique, etc. Répertorier les variables sensibles (présentes ou non dans le jeu de données), et leurs proxys est un premier travail préparatoire à l’identification des biais.
Une fois ce premier travail effectué, on peut alors tenter de répondre à ces questions : est-ce que le jeu de données est représentatif de la population cible ? est-ce que la qualité de données est bien homogène dans les groupes sensibles ? est-ce que les performances et les incertitudes sont bien homogènes dans les groupes sensibles ?
Corriger
Une fois identifiés les biais présents dans les données d’entrée ou les prédictions du modèle, il devient souvent beaucoup plus facile d’y remédier. Toutes les solutions ne sont pas techniques, loin s’en faut : souvent, c’est par la gouvernance de la donnée, ou l’acquisition de nouvelles données, que les problèmes sont résolus. Si cela ne suffit pas, on peut alors, envisager de « réparer » le biais identifié, à conditions de maîtriser les effets de bords (voir notre article illustratif à sujet).
Par exemple, on peut réparer la donnée par un pré-traitement, en rééchantillonnant le jeu de données pour le rendre plus représentatif ou accentuer les événements rares. On peut appliquer des post-traitements, en ajustant des seuils de détection, ou en hybridant le modèle avec des garde-fous comme des règles métiers. Enfin, on peut aussi sélectionner le modèle en intégrant la métrique d’équité dans la notion de performance opérationnelle. Tout cela n’a d’intérêt et d’impact que si la chaîne de décision aval est elle-même équitable.
L’équité, en vrai ça donne quoi ?
Afin d’illustrer ces concepts, voici comment nous avons rendu plus équitable un modèle de recommandations chez l’un de nos clients, leader du secteur des télécommunications.
A des fins marketing, on cherche à estimer un score d’appétence pour un produit, comme un abonnement TV. Un des prérequis imposés à l’IA par le métier est le suivant : les scores d’appétence doivent être calibrés, et représenter des probabilités d’achat : si l’algorithme donne un score de 0.2, il doit y avoir 20% de chances que le client soit appétant.
Ici, si l’on considère le genre comme une variable sensible, on a pu mesurer que ces scores d’appétence étaient bien calibrés au global, mais mal calibrés pour les hommes ET pour les femmes : un score de 0.2 traduit bien une probabilité d’achat de 20% au global, mais de 30% chez les hommes et 10% chez les femmes. Cet écart à l’exigence de base peut se mesurer via la métrique de Spiegelhalter, comme l’illustre le graphique ci-dessous.
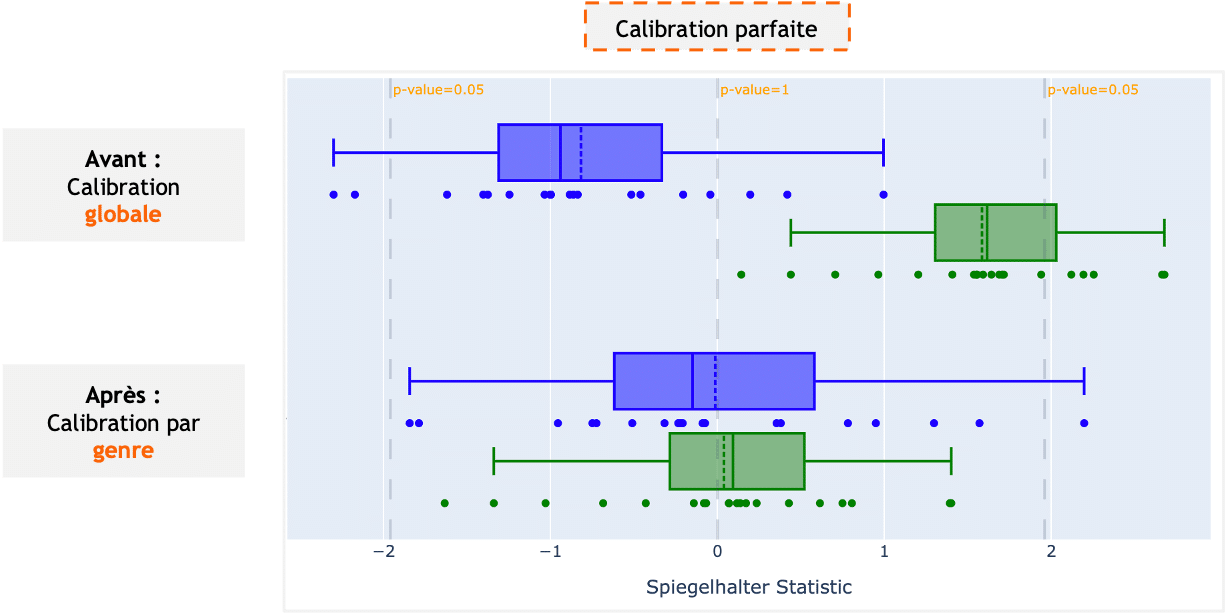
Après remédiation en post-traitement, qui consiste à opérer une recalibration au sein de chaque groupe, l’objectif est atteint : quand l’algorithme donne un score de 0.2, il y a bien 20% de chances que le client soit appétant, et ce quel que soit son genre !
Finalement, l’algorithme, en étant mieux calibré au sein de chaque groupe, a gagné en pertinence au global. Loin d’avoir perdu en performance opérationnelle, l’équité nous a permis de renforcer l’algorithme en s’affranchissant des effets de moyenne.
Cette démarche est générale, et s’applique notamment à d’autres cas d’usage bien plus à risques, tels les scores de récidive dans les tribunaux américains.
Bref, l’équité et la performance sont deux facettes d’une même pièce : une IA aux impacts maîtrisés sur l’humanité !
Les membres de l’expertise Reliable AI développent des modèles performants, fiables et maîtrisés, sur l’ensemble du cycle de vie, pour une IA de confiance.

Senior Expert de l'expertise Reliable AI
Grégoire anime l’expertise IA de confiance de Quantmetry. Il structure la veille et dirige les orientations scientifiques sur le thème IA de confiance. Il est le référent R&D de tous les projets visant à établir une méthodologie d’homologation des IAs.