

DALL-E 2 : derrière la hype, ruptures technologiques, opportunités et limites

DALL-E 2, le dernier outil de génération d’image à partir de texte d’Open AI, l’entreprise spécialisée dans la recherche en IA à qui l’on doit plus récemment ChatGPT, a fait couler beaucoup d’encre. Cet algorithme génère des visuels de haute qualité, est facile d’utilisation et très peu cher. Le nombre de formations disponibles pour sa prise en main montre un engouement réel non limité aux seuls data scientists. Cette révolution en cours pose malgré tout de nombreuses questions techniques, éthiques et business. Au-delà des métiers des concepts artistes, qui seraient directement menacé de disparition d’après Usbek & Rica, le potentiel de cette technologie est immense.
Dans cet article, nous étudions les différentes technologies qui ont permis l’avènement de la dernière génération de modèles génératifs et plus spécifiquement de DALL-E 2, nous abordons les limitations d’ordre technique et éthiques avant d’explorer les opportunités business liées à cette nouvelle technologie.
Les transformers au cœur d’une avancée scientifique et technique
Les Large Language Models utilisant des transformers comme GPT-3 ont déjà révolutionné le NLP. Ils permettent un accès à des modèles très puissants et déjà entrainés pouvant être adaptés avec peu d’entrainement dans la majorité des cas d’usages métier y compris sur des tâches non déjà vues.
Les modèles transformers sont une technologie récente à l’échelle du deep learning.
![]()
Source : A Survey on Vision Transformer
Après le NLP, ils se démocratisent en Computer Vision avec des modèles qui font référence comme ViT (2020) ou DETR (2020). Ils peuvent être préférés aux CNN car ils permettent :
- une meilleure parallélisation des calculs
- d’apprendre plus facilement des features sémantiques
- de lier plus efficacement des pixels très éloignés
- d’obtenir des performances qui saturent moins vite avec le nombre de paramètres.
Le modèle DALL-E 2
DALL-E 2 consiste en un assemblage de plusieurs briques de Deep Learning, chacune étant entraînée séparément.
- Le modèle CLIP est entrainé sur un jeu de données non labellisé de 650M de paires images / description extraites d’internet.
- Un modèle de diffusion appelé « prior » génère un embedding d’image à partir d’un embedding de texte généré par CLIP. Même s’il n’est pas strictement nécessaire, il permet d’améliorer grandement la qualité perçue des images générées. Cette étape est non-déterministe : des sorties différentes seront générées à partir d’une même entrée, ce qui crée de la diversité.
- D’autres modèles de diffusions rassemblés dans la brique « decoder » permettent ensuite de générer une image de taille 64×64 d’après le résultat du prior puis de l’upsampler pour augmenter sa résolution à 1024×1024. C’est à eux qu’on doit la qualité des images générées !
La partie supérieure du schéma ci-dessous représente le processus d’entraînement de CLIP, tandis que la partie inférieure représente le processus de génération.
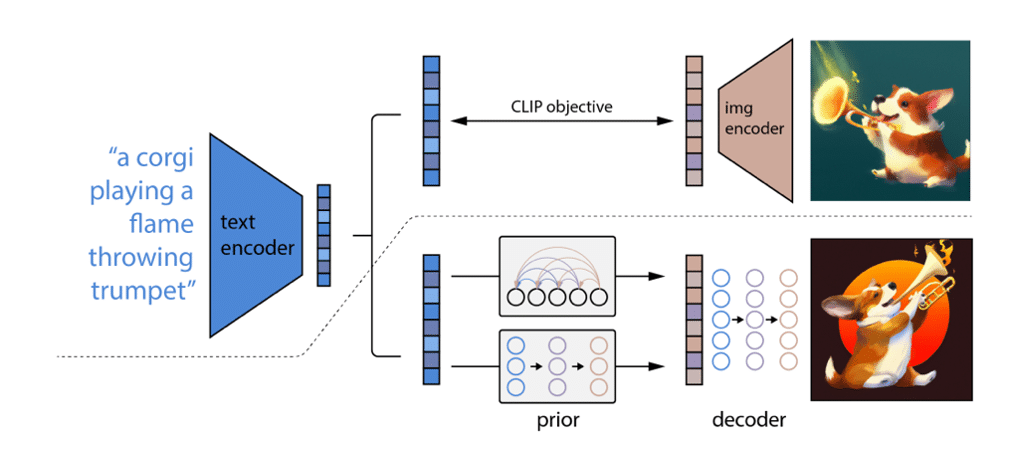
Extrait de l’article d’OpenAI sur DALL-E2
On notera que les modèles de génération text-to-image dernière génération ont des structures très similaires. On peut citer parmi eux :
- Imagen de Google qui n’est pas encore testable
- eDiffi de NVidia qui n’est pas encore testable
- Stable diffusion de StabilityAI qui est utilisable gratuitement et opensource.
Les limitations techniques de DALL-E 2
Malgré une architecture très innovante et des performances impressionnantes, DALL-E 2 comporte quelques limitations qui sont communes avec les GANs. On observe que le modèle a du mal à générer des images avec beaucoup de détails. Les auteurs le reconnaissent et l’attribuent aux briques d’upsampling de 64×64 à 1024×1024.
Ainsi, les visages et les mains ne sont pas très bien représentés pour les humains, et le texte dans les photos n’est pas sémantiquement juste.

« Ceo talking to employees »
Les auteurs expliquent que CLIP ne gérant pas l’orthographe des mots dans les images générées, les parties textuelles des images sont souvent incorrectes.

“Datascientist coding a deep learning algorithm”
L’algorithme gère mal les longs textes descriptifs, aussi appelée prompts. Sur notre exemple ci-dessous, DALL-E 2 préfère dessiner un animal hybride dauphin-éléphant plutôt que de faire apparaître les deux.
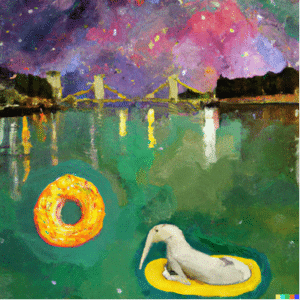
“Dolphins swimming in a river with an elephant on a giant donut across the Seine. Sky is full of stars. With style of Monet. »
Aussi, OpenAI est connu pour avoir un approche propriétaire et de ne rendre ni leurs codes, ni les poids de leurs modèles open source comme ici avec DALL-E 2. Cela limite le partage de connaissance qui est à la base de la recherche dont a bénéficié OpenAI même et l’émergence de nouveaux cas d’usages multimodaux vision / langage. Cela crée aussi un manque de transparence notamment dans les choix qui ont été fait pour la base d’entrainement avec des questions éthiques et légales.
Une propriété intellectuelle à définir
En effet, DALL-E 2 a été entrainé sur un jeu de données extrait d’internet dont l’origine n’a pas été dévoilée. Sur de précédentes itérations de modèles similaires, on pouvait par exemple trouver des watermarks des banques d’image. A titre d’exemple, on peut toujours trouver dans le jeu de données Conceptual Caption de Google des images Shutterstock malgré leurs termes et conditions d’utilisation.
OpenAI prétend avoir grandement limité la prédiction d’images venant du jeu d’entrainement, comme dans l’itération précédente DALL-E, grâce à la déduplication d’une partie de leurs données. En effet, ce serait la présence de nombreuses images très similaires dans la base d’entrainement qui provoque ce genre d’effet. C’est aussi ce qu’ont remonté des chercheurs d’Alphabet qui ont trouvé ce genre de problème dans Imagen et recommandent d’aller encore plus loin en auditant avec des techniques d’attaques et en garantissant le respect de la vie privée dès l’entrainement.
Malgré tout, la question de l’origine et des droits d’auteurs sur ces paires (image / description) gagnerait à être posée étant donné l’absence de consentement des artistes, des comme détaillé ci-dessous et le caractère commercial d’OpenAI.
De fait, une des fonctionnalités les plus mise en avant par OpenAI est de générer des images dans le style d’un artiste sur le mode des Style Transfer GANs. Même si les résultats proposés par DALL-E 2 ont bien été générés par l’algorithme et ne ressemble pas directement à une œuvre originale, il est difficile de ne pas prendre en compte la contribution de l’artiste dont le style est imité.
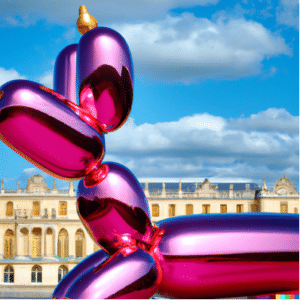
« Jeff Koons balloon dog in the Chateau de Versailles »
Cette image ressemble suffisamment à une véritable œuvre de Jeff Koons pour devenir un plagiat.

Balloon Dog (magenta), Jeff Koons, 1994-2000 exposé au Château de Versailles en 2008
Les artistes imités ne sont pourtant pas crédités sur l’image et ne touchent pas de droits d’auteur.
Dans les conditions d’utilisation actuelles, l’utilisateur est propriétaire des prompts et OpenAI des images générées. Certaines banques d’images comme Getty Image ne préfèrent donc pas autoriser la vente d’images générées par DALL-E 2 pour éviter de potentiels risques juridiques voire poursuivent en justice d’autres modèles comme Stable Diffusion. D’autres banques d’images comme Shutterstock préfèrent capitaliser sur cette technologie en rémunérant les artistes proportionnellement à leurs contributions au nombre d’images dans le jeu d’entraînement.
Des biais et images problématiques
OpenAI a cherché à limiter les images problématiques (scène violente et/ou sexuelle) générées par DALL-E 2 en les identifiant et retirant dans une phase de pré-entrainement. Cela ayant des conséquences sur la répartition des échantillons par mots clé, un rééquilibrage a eu lieu pour correspondre à la distribution initiale. OpenAI limite aussi la génération de ce genre d’image qui sont contraires aux termes d’utilisation en filtrant directement les prompts générées.
Il demeure quand même des biais qui étaient présents dans le jeu d’entrainement. The Wired pointe, par exemple, des biais sexistes et racistes comme des « man sitting in a prison cell » en hommes majoritairement de couleur, des « CEO » en hommes blancs et des « assistants » en femmes.
DALL-E 2 comportant ce genre de biais et n’étant pas certifié, son utilisation peut être compliqué dans les entreprises. L’expertise ReliableAI de Quantmetry peut vous accompagner pour mesurer l’équité et corriger les biais.
Quels impacts business ?
Si certaines campagnes marketing ont été produites avec DALL-E 2 comme celle de La Laitière, ce genre d’initiative ne s’est pas encore véritablement démocratisée dans les entreprises. Les aspects éthiques et juridiques risquent d’être encore plus mis en avant avec les régulations à venir en Europe. Il semble donc difficile à d’utiliser DALL-E 2 tel quel de façon véritablement industrialisée en Europe à ce stade.
De manière générale, cette technologie fait aussi émerger de nouveaux usages en appuyant les métiers créatifs ou en personnalisant davantage les produits B2C. D’une part comme on a pu le voir, certains métiers créatifs peuvent bénéficier de la mise à disposition de ces outils. Savoir utiliser ces outils pourrait devenir une partie du métier de graphistes et designers que ce soit pour trouver des prompts permettant d’arriver rapidement à un résultat satisfaisant. En ce sens, DALL-E 2 peut se révéler très utile dans le domaine de la mode ou de la publicité. D’autre part, la Harvard Business Review évoque l’utilisation de la génération d’image pour la personnalisation de vêtements avec Stitch Fix ou de jouets avec Hot Wheels de Mattel.
Les membres de l’expertise Computer Vision adressent des thématiques couvrant l’ensemble du cycle de valorisation des images : de la constitution du jeu de données à l’implémentation du modèle sur des dispositifs embarqués.

Data Scientist chez Quantmetry
Après une première expérience dans une scale-up de la cyber sécurité et un double diplôme en Data Science et Management, j'ai rejoint l'expertise Computer Vision où je travaille sur des images satellitaires mais pas que !

Senior Data Scientist chez Quantmetry
Data Scientist depuis quatre ans, j'ai une multitude de projets à mon actif, du diagnostic de neuropathies sur images médicales à la détection de documents frauduleux pour l'assurance. J'anime aujourd'hui l'Expertise Computer Vision de Quantmetry.