

Evitez le hors-piste à vos modèles d’IA grâce au contrôle des dérives !

L’intelligence artificielle de Confiance est un sujet que l’on adresse tous les jours chez Quantmetry pour fournir à nos clients des algorithmes de qualité. Ce sujet est traité par l’expertise Reliable AI qui assure la connaissance et l’application de l’état de l’art des 8 thématiques de l’IA de Confiance introduites dans cet article. Le contrôle des dérives est l’une de ces 8 composantes.
Le contrôle des dérives, à quoi ça sert ?
Selon le baromètre 2022 que nous réalisons chez Quantmetry, 46% des projets data atteignent le stade de mise en production contre 27% en 2021. Cette augmentation des projets data en production se couple avec un agrandissement du périmètre d’utilisation de l’intelligence artificielle, notamment sur des sujets critiques : risque de récidive pour une personne coupable d’un délit, détection de pathologies, conduite autonome, etc. Les avancées scientifiques alimentent la création de nouveaux outils et méthodes poussant plus loin les standards projet, ayant pour impact une augmentation des risques liées aux dérives des modèles. En effet, plus il y a de modèle en production, plus il y a d’utilisateurs impactés en cas de dérive !
Suite à des évènements exogènes (conjoncturels, sociétaux ou politiques), tels que la crise sanitaire du COVID ou bien la guerre en Ukraine, les modèles d’intelligence artificielle peuvent subir des fortes perturbations de leurs données d’entrées menant à des prédictions erronées. Le contrôle des dérives des données d’entrées et des performances des modèles d’IAs s’inscrit comme un des moyens d’encadrer leurs impacts et de limiter les risques associés.
Le contrôle des dérives permet de garantir dans la durée que le comportement des modèles est bien celui attendu et que les objectifs métiers restent atteints tout en contrôlant leur impact opérationnel.
Le contrôle des dérives, qu’est-ce que c’est ?
Selon le dictionnaire Larousse : une dérive se définie comme le « fait de s’écarter de la voie normale, d’aller à l’aventure, de déraper. Fait de se laisser aller sans réagir. ». Concrètement, le contrôle des dérives signifie contrôler les dérives de données, de performance, et prendre en compte les retours terrains.
Contrôle des dérives de données
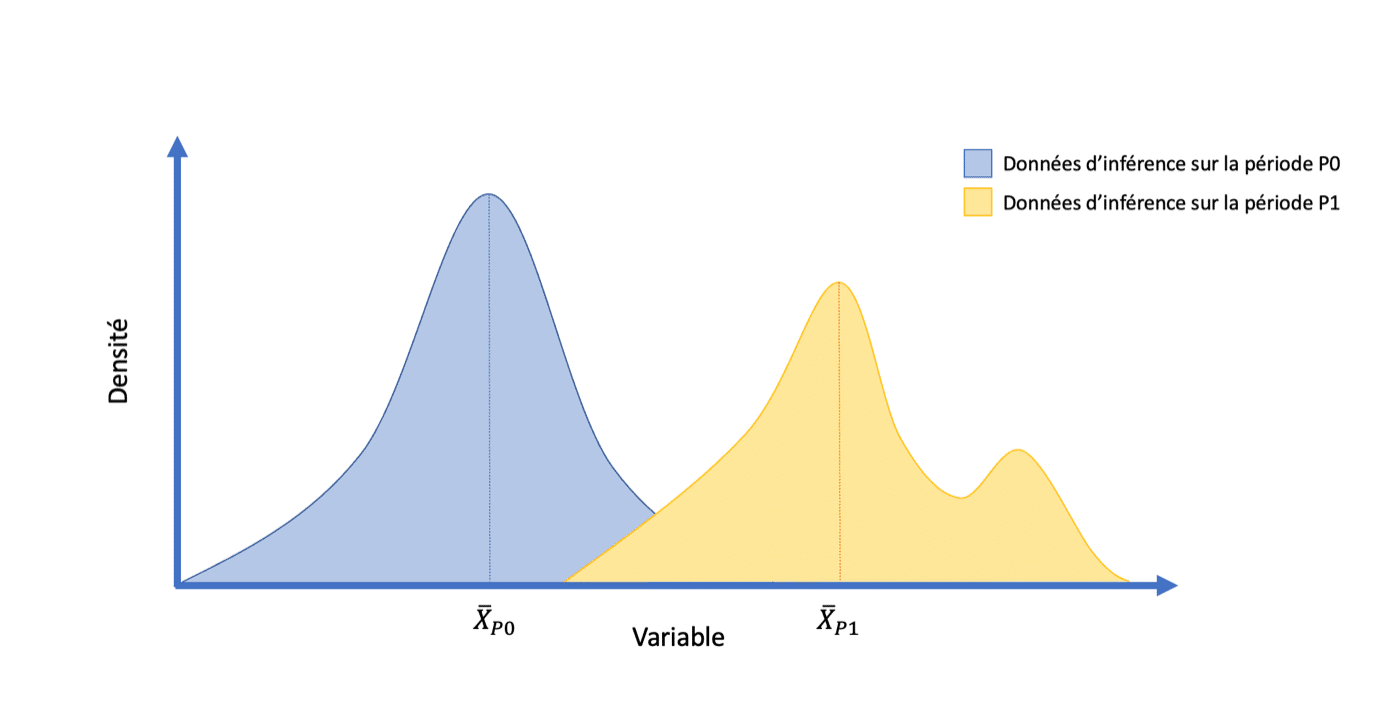
Exemple fictif de l’impact d’une dérive des données sur la distribution de probabilités d’une variable :
Ce graphique représente l’impact qu’une dérive de données peut avoir sur une variable. En bleu est représentée la distribution de la variable pendant l’inférence sur la période P0 et en jaune la distribution pendant l’inférence après dérive des données sur la période P1. On remarque un changement des propriétés statistiques, tel qu’un changement de moyenne par exemple. La loi de probabilités associée change aussi, passant d’une loi proche d’une loi normale à une loi inconnue asymétrique.
Les modèles d’Intelligence Artificielle sont entrainés à partir d’un certain nombre d’observations appartenant à un jeu d’entrainement défini comme un échantillon d’une population et supposé en avoir les mêmes propriétés statistiques. Ainsi, en régime stationnaire, lorsque des prédictions sont réalisées sur des nouvelles données appartenant à cette population, les prédictions observées devraient être proche de celles obtenues lors de l’entrainement. Malheureusement, elles peuvent être bien différentes.
Chez Quantmetry nous avons rencontré cette problématique chez l’un de nos clients, du secteur de l’automobile, qui utilisait un modèle de traitement naturel du langage afin de classifier des commentaires clients. Suite à des alertes, la nette baisse de la performance est constatée : celle-ci s’est effondrée en se voyant divisée par deux ! En effet, l’expérience utilisateur avait été modifiée : auparavant les commentaires étaient un champ facultatif mais suite à une mise à jour du site internet. L’utilisateur final était donc contraint de laisser un commentaire pour valider le formulaire, ce qui donnait parfois lieu à des commentaires vides ou bien des « RAS ». Ces données n’ayant jamais été présentes pendant l’entrainement, le modèle ne savait pas correctement les classifier.
La dérive des données se définie comme une altération prolongée de la distribution statistique d’une ou plusieurs variables explicatives de notre modèle. Il ne faut d’ailleurs pas la confondre avec une anomalie qui survient de façon très ponctuelle et nerveuse autour d’un signal stationnaire.
Contrôle des dérives de performance
Contrôler l’amont c’est bien, contrôler l’amont et l’aval c’est mieux !
Les dérives de performance sont étroitement liées aux dérives des données, mais pas seulement !
La performance d’un modèle est définie comme la capacité de celui-ci à réaliser des prédictions justes, en accord avec des métriques métiers. Le suivi de cette performance est nécessaire au maintien de la confiance accordée aux prédictions.
La dérive de la performance s’identifie par un changement du comportement du modèle dans ses prédictions au niveau de leur stabilité et de leur justesse. Celle-ci peut survenir à la suite d’une dérive des données ingérées pour l’inférence ou bien d’un changement du monde réel remettant en question les corrélations identifiées auparavant.
C’est le cas par exemple de la détection de fraude bancaire. Les fraudeurs, qui sont des personnes gagnant leur vie en effectuant des achats à la place des consommateurs, élaborent sans cesse des stratégies différentes pour échapper aux mesures de sécurité. Certains jours, un fraudeur va préférer faire des « petites » fraudes en nombre (pattern 1 : 10 euros par-ci, 10 euros par-là), et d’autre jour des fraudes plus ponctuelles de grande ampleur (pattern 2 : 1500 euros). Même si la distribution des transactions globales est restée la même, certains jours c’est le pattern 1 qui est frauduleux, et d’autres jours c’est le pattern 2. Un modèle entraîné sur l’un ou l’autre des patterns va donc voir sa performance s’effondrer dès que le fraudeur change de stratégie.
Dans un autre contexte, l’accoutumance à la publicité est également un phénomène très sujet à la dérive de performance. Les mêmes internautes navigant sur leurs mêmes sites habituels, exposés à la même publicité, y sont beaucoup moins sensibles quand cela fait trois jours d’affilés qu’ils la voient. La probabilité de clic va donc diminuer avec le temps, toutes choses égales par ailleurs.
Boucle de retours terrains
Après avoir contrôlé la dérive des performances, et si on s’attardait sur le pourquoi du comment ?
Afin de rester aligné avec les utilisateurs finaux et les personnes impactées par les IAs, il est nécessaire de récolter leurs retours (commentaires, score de satisfaction ou d’accord avec la prédiction) et maintenir une feuille de route d’amélioration continue.
La mise en place de boucles de rétroaction sur le terrain est essentielle pour améliorer un modèle d’intelligence artificielle (IA) pour plusieurs raisons. Premièrement, cela permet d’identifier des erreurs et des lacunes : les modèles d’IA peuvent souvent produire des résultats inattendus ou des erreurs lorsqu’ils sont déployés dans un environnement réel. En mettant en place des boucles de rétroaction, il est possible de récolter des commentaires et des observations des utilisateurs finaux. Cela permet de comprendre les problèmes spécifiques auxquels le modèle est confronté et d’apporter les ajustements nécessaires. De plus, les conditions réelles peuvent évoluer avec le temps, que ce soit en raison de changements dans les données d’entrée, les préférences des utilisateurs ou les contextes d’utilisation.
Les boucles de retour terrain permettent aussi d’intégrer les utilisateurs en leur montrant la prise en compte de leurs commentaires afin d’établir une relation de confiance avec eux. Cela peut contribuer une plus large adoption et utilisation du modèle.
En résumé, les boucles de rétroaction sur le terrain sont essentielles pour identifier les erreurs, améliorer la performance, adapter le modèle aux conditions changeantes et collecter des données supplémentaires. Elles sont le moteur du cycle de vie du modèle et d’une expérience utilisateur optimale.
Le contrôle des dérives, comment l’activer ?
Récolter
En mettant en place une stratégie de récolte des retours utilisateurs, il est possible de tirer parti des leurs connaissances et perspectives pour améliorer continuellement l’IA et offrir une solution pertinente.
Cette stratégie peut s’activer en mettant en place des canaux de communication appropriés pour permettre aux utilisateurs de donner leurs retours à chaque prédiction consommée. Cela peut inclure des systèmes de likes (« en accord/désaccord avec la prédiction »), des champs de commentaires, des enquêtes, ou des réseaux sociaux internes sur lesquels les problèmes sont collectés. Par ailleurs, il est aussi possible d’encourager les utilisateurs à donner leur avis en mettant en avant l’importance de leurs retours pour l’amélioration du système, simplement en expliquant comment leurs retours contribueront à l’amélioration continue de l’IA. Afin de pérenniser cette démarche, il est important d’être réactif aux retours des utilisateurs en communiquant les mises à jour de manière transparente pour montrer que leurs retours sont pris en compte.
Surveiller
La surveillance permet de suivre les performances du modèle d’IA dans un environnement réel. Cela permet de détecter rapidement toute dégradation de la précision, des temps de réponse ou d’autres métriques de performance techniques, scientifiques et opérationnelles. Selon le cas d’usage, certaines métriques sont plus pertinentes que d’autres. Toutes les métriques n’ont pas la même teneure en information et ne sont pas mesurables instantanément.
A minima, ce sont les indicateurs métiers et financiers qui doivent être mis en place, et ce dans une optique d’estimation de ROI. Le problème est que souvent, ces indicateurs nécessitent des données labellisées (ex : fraude / pas fraude), qui arrivent avec un certain retard sur les événements. Lorsqu’un indicateur financier baisse, il est souvent déjà trop tard et l’inertie du changement peut être de plusieurs mois.
De plus dans certains cas, certains indicateurs sont tout simplement indisponibles (ex: est-ce qu’une demande de crédit refusée était finalement solvable ? est-ce qu’un candidat recalé aurait finalement dû être recruté ?), et la notion même de faux positifs ou de vrais positifs peut tout simplement disparaître en production.
Il est donc important de se focaliser :
- d’une part sur des métriques non-supervisées, qui vont permettre d’anticiper les évolutions de distribution de données sans attendre l’arrivée des labels,
- d’autre part sur des métriques fonctionnelles, qui vont mesurer l’impact immédiat du modèle sur les processus de l’entreprise.
Par exemple, dans une chaîne de validation modèle + expert, toutes les détections de “positifs” (vrais ou faux) peuvent déclencher une validation experte, et donc requérir du temps de traitement. On peut alors surveiller une éventuelle sur-sollicitation (ou sous-sollicitation) des experts métier par le modèle.
Afin d’effectuer une surveillance efficace, il est donc recommandé de définir en amont des métriques fonctionnelles, et techniques (performance, stabilité) qui devront être conjointement analysées en fonction des réalités métiers.
Il est aussi possible de monitorer en temps réel les prédictions et les confronter aux attentes métier à travers un dashboard par exemple.
Surveiller ces modèles c’est l’assurance d’une réaction rapide et adaptée, si des leviers d’actions ont bien été définis en amont.
Actualiser
Suite à la récolte et l’analyse des retours utilisateurs et de la performance du modèle, il est judicieux de l’actualiser en conséquence. En effet, le réentrainement des modèles d’IA permet de maintenir leur pertinence, leur efficacité et leur qualité au fil du temps.
Il donc nécessaire de définir une stratégie de réentrainement en production des modèles. Cette stratégie gravite autour de plusieurs éléments clefs :
- Le déclenchement d’un ré-entraînement : il peut s’opérer de manière régulière à intervalles fixes ou de manière déclenchée par une alarme. Dans tous les cas, ces stratégies doivent être paramétrées par le concepteur : quelle fréquence de ré-entraînement ? Quel critère fait sonner l’alarme ?
- La profondeur d’historique retenue : qui dit ré-entraînement dit également sélection de modèles. Dans un contexte d’adaptation aux dérives, on peut imaginer deux challengers très simples : un modèle ayant rafraîchi son jeu d’entraînement avec les données supplémentaires (adaptation graduelle) et un autre ayant volontairement supprimé les données avant la dérive et se réentraînant sur un sous-ensemble très récent de donnée (adaptation abrupte).
- L’évaluation par A/B test : pour déployer une solution a minima meilleure que celle sujette à dérive, encore faut-il s’assurer que le modèle candidat est bien plus performant en environnement de production. L’A/B test permet de comparer au moins deux modèles entre eux en production, à condition de pouvoir mesurer la performance de l’un et l’autre simultanément (en canari ou en shadow, voire notre article dédié sur le sujet). Cette phase doit être suffisamment longue pour récolter de la donnée et acquérir de la puissance statistique, et suffisamment courte pour ne pas laisser la dérive causer trop de dégâts ! Il y a donc un véritable enjeu autour de la durée de l’A/B test.
D’une manière générale, ces trois éléments sont sujets à plusieurs facteurs qui nécessitent une première phase de rodage (ou d’hypercare en anglais), pendant laquelle on ajuste empiriquement le design du cycle de vie du modèle (fréquence de réentraînement, modèles challengers, durée des A/B test etc.).
Le contrôle des dérives, en vrai ça donne quoi ?
Contrôler les dérives, plus facile à dire qu’à faire ? Qu’est-ce que ça donne en pratique ?
Prenons un modèle en production permettant de prédire le volume de gaz consommé dans une région. Ce signal est saisonnier et fortement perturbé par des facteurs exogènes (géopolitiques). Les performances du modèle peuvent fortement varier au cours du temps. Afin de contrôler l’impact opérationnel du modèle en production, on souhaite définir et implémenter une stratégie de surveillance et de maintenance du modèle. Avant de mettre en place un plan d’action efficace, il faudra d’abord répondre à toutes les interrogations que soulève l’optimisation de cette stratégie.
Premièrement, il faut connaitre le bénéfice réel d’implémenter une stratégie de contrôle des dérives avec réentrainement des modèles et mise en production. Il faudra donc définir un indicateur de performance métier, qui sera dans notre cas un indicateur fonctionnel ou financier corrélé à la performance : une métrique agrégée de bonus/malus.
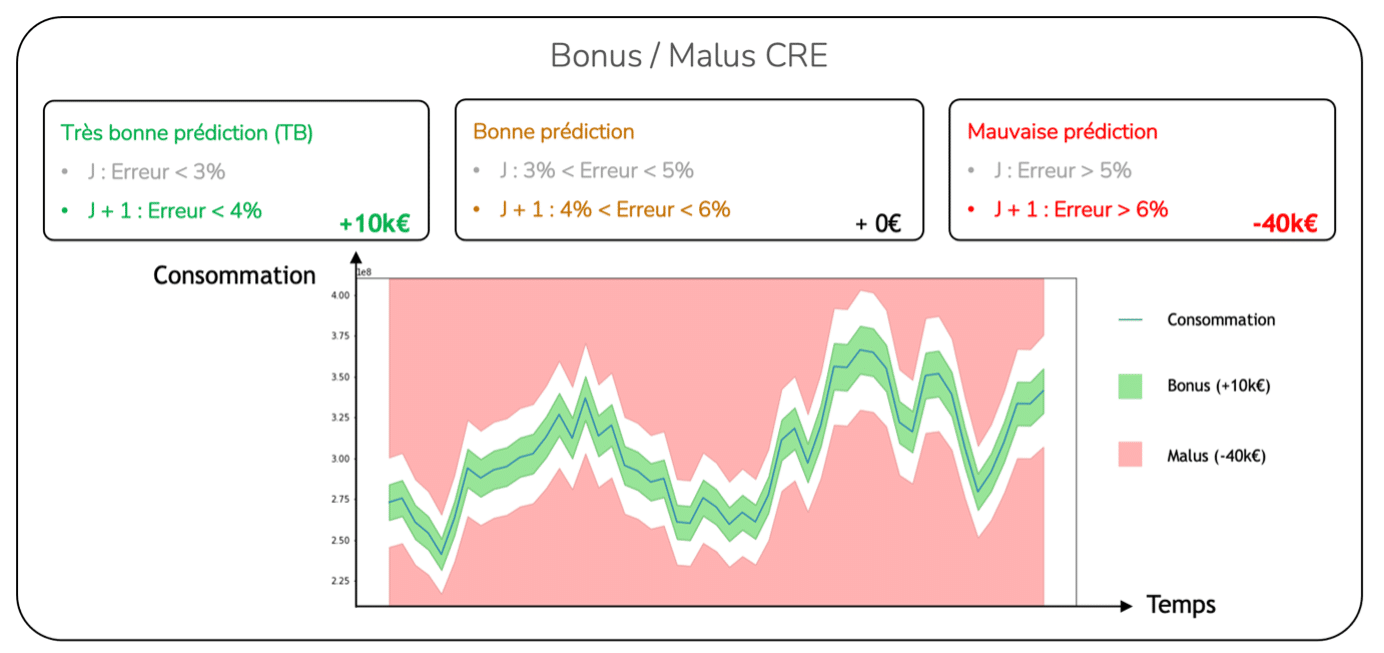
Métrique de bonus/malus inspirée de celle donnée par la Commission de régulation de l’énergie (CRE).
Cette métrique divise et note les prédictions du modèle en trois catégories différentes :
-
- Par mois, un bonus max de +1 est accordé pour le nombre de jours dans la catégorie très bonne prédiction,
- Par mois, une pénalité maximale de -4 est donnée pour le nombre de jours dans la catégorie de mauvaise prédiction,
- Aucun bonus/malus n’est accordé pour un pronostic pour la catégorie de bonne prédiction.
Deuxièmement, il faut définir précisément les stratégies de réentrainement qui vont être évaluées. Une première approche serait de tester différentes combinaisons de la profondeur d’historique utilisée (total, 1 an ou 3 ans) et de la fréquence de réentrainement (1 mois, 3 mois, 6 mois ou 1 an). Puis de comparer ces stratégies en comparant les performances de celles-ci à travers la métrique agrégée.
Comme évoqué, les réentrainements peuvent être coûteux et les mises en production risquées. La question de la frugalité se pose donc ! Peut-on obtenir une performance similaire, voire supérieure, avec une approche plus frugale, en ne réentraînant les modèles que lorsque c’est nécessaire ? C’est là qu’intervient le système d’alerte. Dans notre cas, l’alerte se lève lorsque l’erreur de prédiction (MAPE) dépasse une certaine valeur qu’on nommera Upper Control Limit (UCL) pendant une durée déterminée.
Une dernière question se pose : comment être plus confiant sur la performance du modèle ? L’A/B test permet de s’en assurer ! Lui aussi nécessite une paramétrisation : durée et critère de succès. Il faut donc évaluer ces différentes combinaisons à travers les mêmes métriques de performance dans une phase de rodage. Pour en savoir plus sur l’A/B test vous pouvez également consulter notre article détaillé sur le sujet.
Finalement, il s’est avéré que la stratégie la plus performante pour maximiser le ROI était de réentraîner le modèle de façon automatique en réalisant des A/B tests à intervalles fixes.
Hourra ! Grâce à cette stratégie de contrôle des dérives, le modèle a pu être réentraîné de façon optimale afin de prendre en compte les perturbations exogènes. Celle-ci permet donc d’atteindre un ROI maximum conformément aux attentes métiers.
Le contrôle des dérives, en pratique, agit donc comme un véritable allié dans la maitrise de la performance et des risques opérationnels.
Les membres de l’expertise Reliable AI développent des modèles performants, fiables et maîtrisés, sur l’ensemble du cycle de vie, pour une IA de confiance.

Data Scientist Confirmé chez Reliable AI
Thomas fait partie de l’expertise Reliable AI au sein de Quantmetry et participe au développement d’une plateforme d’audit des IAs.